Depth-Copy-Paste: Multimodal and Depth-Aware Compositing for Robust Face Detection
作者: Qiushi Guo
分类: cs.CV
发布日期: 2025-12-12
💡 一句话要点
提出Depth-Copy-Paste,通过多模态深度感知合成增强人脸检测鲁棒性。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据增强 人脸检测 深度感知 多模态融合 图像合成 Copy-Paste 语义匹配
📋 核心要点
- 传统Copy-Paste方法在人脸检测数据增强中存在前景提取不准、场景不一致等问题,导致合成图像不真实。
- Depth-Copy-Paste利用BLIP、CLIP、SAM3和Depth-Anything等多模态信息,实现语义兼容和深度感知的图像合成。
- 实验表明,Depth-Copy-Paste能生成更真实的数据,显著提升下游人脸检测任务的性能,优于传统方法。
📝 摘要(中文)
数据增强对于提高人脸检测系统的鲁棒性至关重要,尤其是在遮挡、光照变化和复杂环境等具有挑战性的条件下。传统的复制粘贴增强方法由于前景提取不准确、场景几何不一致和背景语义不匹配,通常会产生不真实的合成图像。为了解决这些限制,我们提出了一种多模态和深度感知的增强框架Depth Copy Paste,通过复制完整的人体实例并将它们粘贴到语义兼容的场景中,生成多样且物理一致的人脸检测训练样本。我们的方法首先采用BLIP和CLIP联合评估语义和视觉连贯性,从而自动检索给定前景人物最合适的背景图像。为了确保高质量的前景掩码,保留面部细节,我们集成了SAM3进行精确分割,并使用Depth-Anything提取未被遮挡的可见人物区域,防止损坏的面部纹理被用于增强。为了实现几何真实感,我们引入了一种深度引导的滑动窗口放置机制,该机制在背景深度图上搜索具有最佳深度连续性和尺度对齐的粘贴位置。由此产生的合成图像表现出自然的深度关系和改进的视觉合理性。大量的实验表明,与传统的复制粘贴和无深度增强方法相比,Depth Copy Paste提供了更多样化和真实的训练数据,从而显著提高了下游人脸检测任务的性能。
🔬 方法详解
问题定义:论文旨在解决传统Copy-Paste数据增强方法在人脸检测任务中生成不真实合成图像的问题。现有方法在前景提取、场景几何一致性和背景语义匹配方面存在不足,导致增强后的数据质量不高,影响人脸检测模型的鲁棒性。
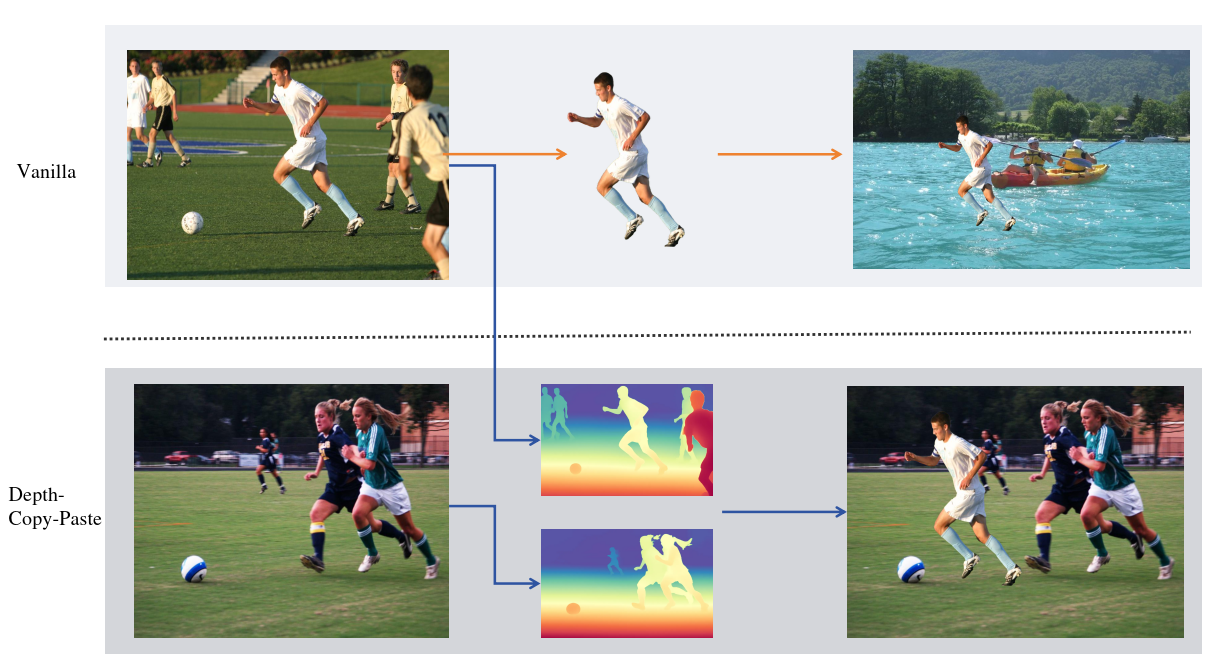
核心思路:论文的核心思路是利用多模态信息(包括语义和深度信息)来指导Copy-Paste过程,从而生成更真实、更符合物理规律的合成图像。通过语义匹配选择合适的背景,利用深度信息进行几何对齐,避免了传统方法中常见的合成伪影。
技术框架:Depth-Copy-Paste框架主要包含以下几个阶段:1) 背景选择:使用BLIP和CLIP联合评估前景人物和背景图像的语义和视觉连贯性,选择最合适的背景图像。2) 前景分割:使用SAM3进行精确的前景分割,保留面部细节。3) 深度提取:使用Depth-Anything提取未被遮挡的可见人物区域的深度信息。4) 深度引导的粘贴:在背景深度图上搜索具有最佳深度连续性和尺度对齐的粘贴位置,将前景人物粘贴到背景中。
关键创新:该方法最重要的创新点在于将深度信息引入到Copy-Paste过程中,并结合多模态信息进行指导。与传统的Copy-Paste方法相比,Depth-Copy-Paste能够生成更符合物理规律的合成图像,从而提高人脸检测模型的鲁棒性。
关键设计:在深度引导的粘贴阶段,论文提出了一种深度引导的滑动窗口放置机制,该机制在背景深度图上搜索具有最佳深度连续性和尺度对齐的粘贴位置。具体实现细节未知,但可以推测其目标是最小化前景和背景在深度上的不连续性,并确保前景人物的尺度与背景环境相匹配。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Depth-Copy-Paste方法在下游人脸检测任务中取得了显著的性能提升,优于传统的Copy-Paste方法和无深度信息的增强方法。具体的性能数据和提升幅度在摘要中没有明确给出,但强调了其在提供更多样化和真实训练数据方面的优势。
🎯 应用场景
该研究成果可广泛应用于人脸检测、人脸识别等计算机视觉任务的数据增强,尤其是在训练数据不足或存在偏差的情况下。通过生成更真实、更多样化的训练数据,可以显著提高人脸检测系统的鲁棒性和泛化能力,使其在复杂环境和具有挑战性的条件下也能表现良好。此外,该方法也可扩展到其他目标检测和图像合成任务中。
📄 摘要(原文)
Data augmentation is crucial for improving the robustness of face detection systems, especially under challenging conditions such as occlusion, illumination variation, and complex environments. Traditional copy paste augmentation often produces unrealistic composites due to inaccurate foreground extraction, inconsistent scene geometry, and mismatched background semantics. To address these limitations, we propose Depth Copy Paste, a multimodal and depth aware augmentation framework that generates diverse and physically consistent face detection training samples by copying full body person instances and pasting them into semantically compatible scenes. Our approach first employs BLIP and CLIP to jointly assess semantic and visual coherence, enabling automatic retrieval of the most suitable background images for the given foreground person. To ensure high quality foreground masks that preserve facial details, we integrate SAM3 for precise segmentation and Depth-Anything to extract only the non occluded visible person regions, preventing corrupted facial textures from being used in augmentation. For geometric realism, we introduce a depth guided sliding window placement mechanism that searches over the background depth map to identify paste locations with optimal depth continuity and scale alignment. The resulting composites exhibit natural depth relationships and improved visual plausibility. Extensive experiments show that Depth Copy Paste provides more diverse and realistic training data, leading to significant performance improvements in downstream face detection tasks compared with traditional copy paste and depth free augmentation methods.