Cross-modal Context-aware Learning for Visual Prompt Guided Multimodal Image Understanding in Remote Sensing
作者: Xu Zhang, Jiabin Fang, Zhuoming Ding, Jin Yuan, Xuan Liu, Qianjun Zhang, Zhiyong Li
分类: cs.CV
发布日期: 2025-12-12
备注: 12 pages, 5 figures
💡 一句话要点
提出CLV-Net以解决遥感图像理解中的用户意图引导问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 遥感图像理解 多模态推理 用户意图引导 上下文感知学习 分割掩膜生成 语义一致性 关系建模
📋 核心要点
- 现有方法在仅依赖简单文本提示时,难以有效引导模型关注用户感兴趣的区域,导致识别精度不足。
- CLV-Net通过允许用户提供视觉线索(如边界框),并利用上下文感知掩膜解码器来增强目标表示,解决了这一问题。
- 在两个基准数据集上的实验结果显示,CLV-Net超越了现有方法,建立了新的最先进结果,精确捕捉用户意图。
📝 摘要(中文)
近年来,图像理解的进展使得利用大型语言模型进行遥感中的多模态推理成为可能。然而,现有方法在仅提供简单的通用文本提示时,仍难以引导模型关注用户相关区域。此外,在大规模航空影像中,许多物体的视觉外观高度相似,并且存在丰富的物体间关系,这进一步复杂化了准确识别。为了解决这些挑战,我们提出了跨模态上下文感知学习的视觉提示引导多模态图像理解模型(CLV-Net)。CLV-Net允许用户提供简单的视觉线索(如边界框)来指示感兴趣区域,并利用该线索引导模型生成与用户意图相符的分割掩膜和描述。我们设计的上下文感知掩膜解码器建模并整合物体间关系,以增强目标表示并提高掩膜质量。综合实验表明,CLV-Net在两个基准数据集上超越了现有方法,建立了新的最先进结果。
🔬 方法详解
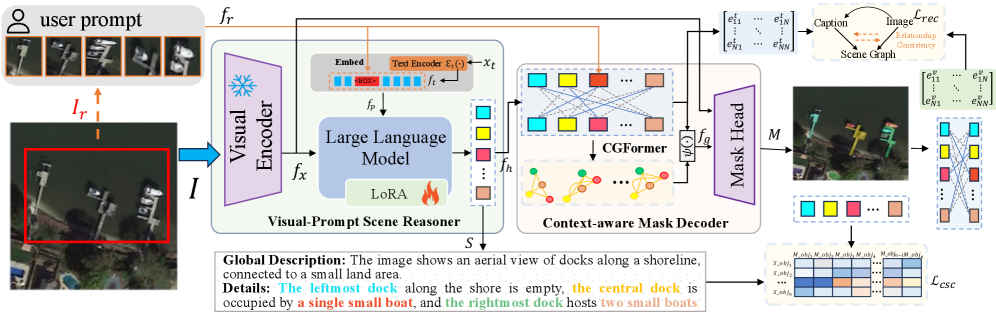
问题定义:本论文旨在解决遥感图像理解中,如何有效引导模型关注用户感兴趣区域的问题。现有方法在仅依赖简单的文本提示时,无法准确识别相似物体,导致识别效果不佳。
核心思路:CLV-Net的核心思路是通过用户提供的视觉线索(如边界框)来引导模型生成与用户意图相符的分割掩膜和描述。通过上下文感知掩膜解码器,模型能够更好地理解物体间的关系,从而提高识别精度。
技术框架:CLV-Net的整体架构包括用户输入的视觉线索、上下文感知掩膜解码器和语义与关系对齐模块。该框架通过整合视觉和文本信息,生成高质量的多模态输出。
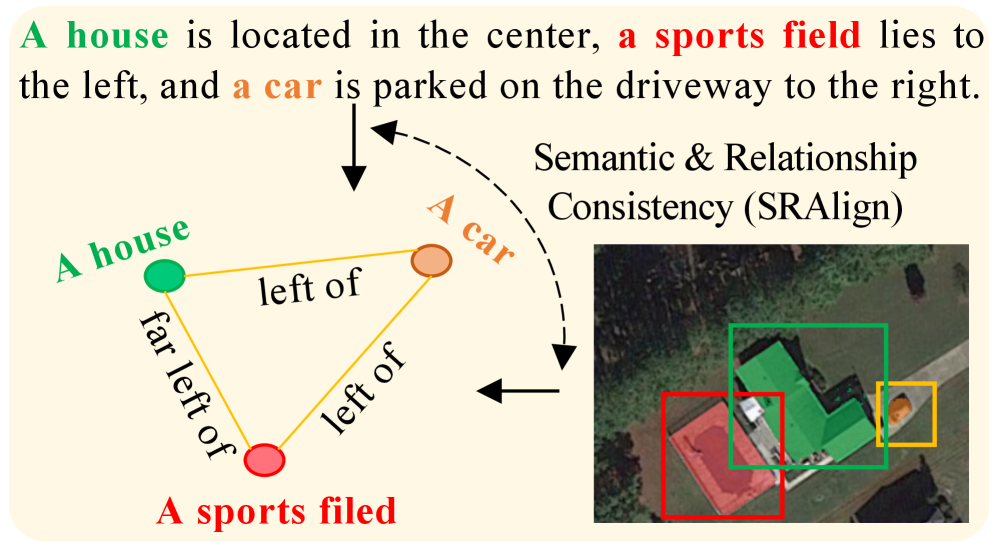
关键创新:CLV-Net的主要创新在于引入了上下文感知掩膜解码器和语义与关系对齐模块,这些设计使得模型能够更好地捕捉物体间的关系,并增强视觉与文本信息的一致性。
关键设计:模型采用了跨模态语义一致性损失和关系一致性损失,以增强对视觉相似目标的细粒度区分。此外,网络结构中对物体间关系的建模是提升掩膜质量的关键设计。
🖼️ 关键图片

📊 实验亮点
在两个基准数据集上的实验结果表明,CLV-Net在多模态图像理解任务中显著优于现有方法,达到了新的最先进结果。具体而言,模型在精度和召回率上均有显著提升,展示了其在用户意图捕捉和多模态输出生成方面的强大能力。
🎯 应用场景
该研究在遥感图像分析、环境监测、城市规划等领域具有广泛的应用潜力。通过更准确地捕捉用户意图,CLV-Net能够帮助用户更高效地进行数据分析和决策,推动相关领域的智能化发展。
📄 摘要(原文)
Recent advances in image understanding have enabled methods that leverage large language models for multimodal reasoning in remote sensing. However, existing approaches still struggle to steer models to the user-relevant regions when only simple, generic text prompts are available. Moreover, in large-scale aerial imagery many objects exhibit highly similar visual appearances and carry rich inter-object relationships, which further complicates accurate recognition. To address these challenges, we propose Cross-modal Context-aware Learning for Visual Prompt-Guided Multimodal Image Understanding (CLV-Net). CLV-Net lets users supply a simple visual cue, a bounding box, to indicate a region of interest, and uses that cue to guide the model to generate correlated segmentation masks and captions that faithfully reflect user intent. Central to our design is a Context-Aware Mask Decoder that models and integrates inter-object relationships to strengthen target representations and improve mask quality. In addition, we introduce a Semantic and Relationship Alignment module: a Cross-modal Semantic Consistency Loss enhances fine-grained discrimination among visually similar targets, while a Relationship Consistency Loss enforces alignment between textual relations and visual interactions. Comprehensive experiments on two benchmark datasets show that CLV-Net outperforms existing methods and establishes new state-of-the-art results. The model effectively captures user intent and produces precise, intention-aligned multimodal outputs.