Kinetic Mining in Context: Few-Shot Action Synthesis via Text-to-Motion Distillation
作者: Luca Cazzola, Ahed Alboody
分类: cs.CV
发布日期: 2025-12-12 (更新: 2026-01-26)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出KineMIC框架,通过文本到动作的知识蒸馏实现少样本动作合成,提升人体动作识别。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion)
关键词: 动作合成 少样本学习 文本到动作 知识蒸馏 人体活动识别 扩散模型 迁移学习
📋 核心要点
- 现有HAR方法依赖大量标注数据,而T2M模型虽然能生成动作,但与HAR任务存在领域差异。
- KineMIC利用文本编码空间的语义对应关系,通过运动挖掘策略实现T2M模型到HAR领域的迁移。
- 实验表明,KineMIC仅需少量样本即可生成连贯动作,显著提升HAR模型的准确率,达到+23.1%的提升。
📝 摘要(中文)
大型带标注的动作数据集获取成本仍然是基于骨骼的人体活动识别(HAR)的关键瓶颈。虽然文本到动作(T2M)生成模型提供了一种引人注目的、可扩展的合成数据来源,但它们的训练目标(强调通用艺术动作)和数据集结构与HAR对运动学精确、类区分性动作的要求存在根本差异。这种差异造成了显著的领域差距,使得通用T2M模型无法生成适合HAR分类器的动作。为了解决这个问题,我们提出了KineMIC(情境中的运动挖掘),一个用于少样本动作合成的迁移学习框架。KineMIC通过假设文本编码空间中的语义对应关系可以为运动学知识蒸馏提供软监督,从而将T2M扩散模型适应于HAR领域。我们通过一种运动挖掘策略来实现这一点,该策略利用CLIP文本嵌入来建立稀疏HAR标签和T2M源数据之间的对应关系。这个过程指导微调,将通用T2M骨干网络转换为专门的少样本动作到动作生成器。我们使用HumanML3D作为源T2M数据集,NTU RGB+D 120的子集作为目标HAR领域来验证KineMIC,每个动作类别随机选择10个样本。我们的方法生成了更加连贯的动作,提供了一个强大的数据增强源,提供了+23.1%的准确率提升。
🔬 方法详解
问题定义:论文旨在解决人体活动识别(HAR)中,由于缺乏大规模标注动作数据集而导致的模型训练困难问题。现有的文本到动作(T2M)模型虽然可以生成动作,但其训练目标和数据集结构与HAR任务的需求不匹配,存在显著的领域差异,直接应用于HAR任务效果不佳。
核心思路:论文的核心思路是利用T2M模型生成动作的能力,通过知识蒸馏的方式,将T2M模型中的动作知识迁移到HAR领域。具体来说,通过挖掘文本编码空间中的语义对应关系,建立T2M源数据和HAR目标任务之间的联系,从而指导T2M模型进行微调,使其能够生成更符合HAR任务需求的动作。
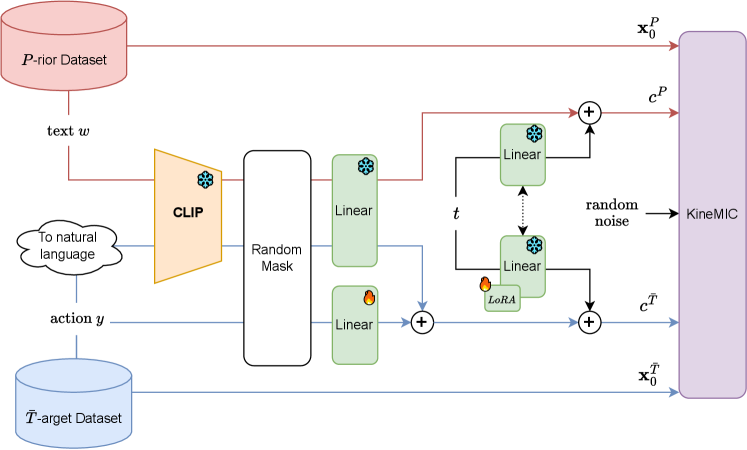
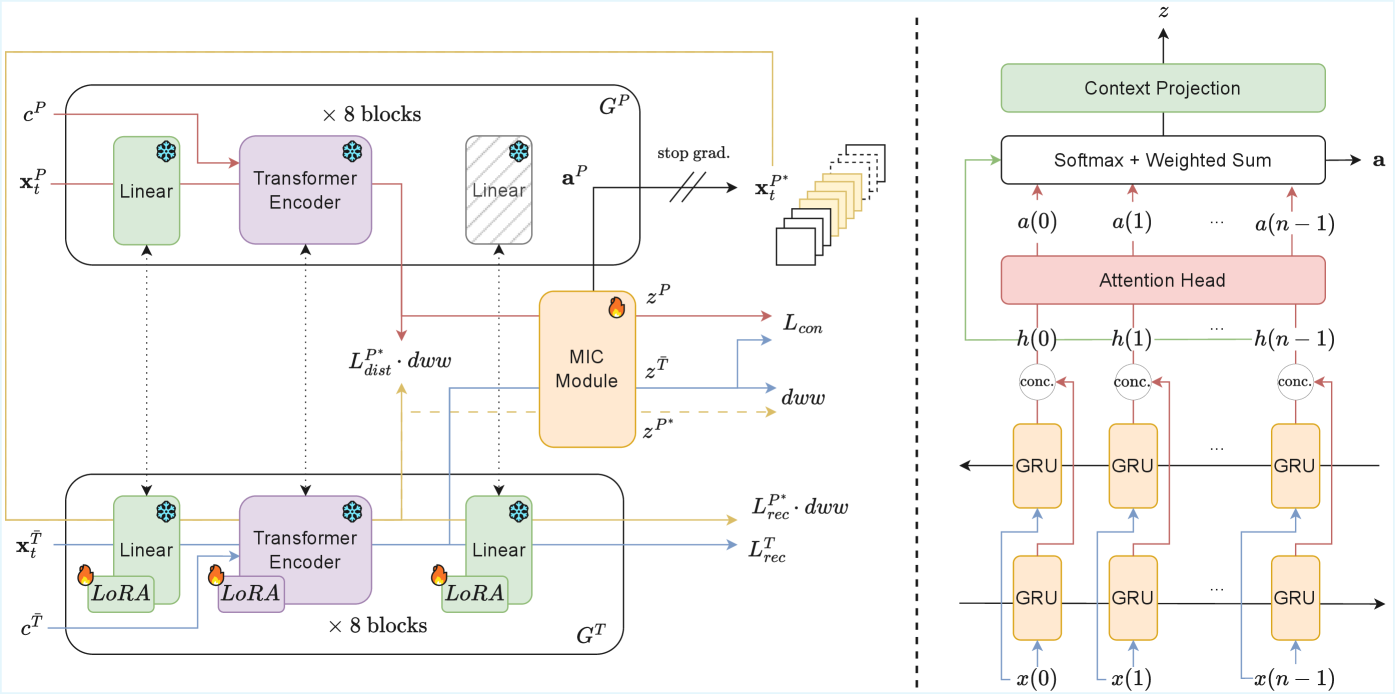
技术框架:KineMIC框架主要包含以下几个阶段:1) 利用CLIP模型提取HAR标签和T2M数据的文本嵌入;2) 通过运动挖掘策略,建立HAR标签和T2M数据之间的对应关系;3) 使用建立的对应关系,对T2M扩散模型进行微调,使其适应HAR领域;4) 使用微调后的模型生成动作数据,用于增强HAR模型的训练。
关键创新:论文的关键创新在于提出了基于文本编码空间语义对应关系的运动挖掘策略。该策略能够有效地建立T2M源数据和HAR目标任务之间的联系,从而指导T2M模型进行微调,使其能够生成更符合HAR任务需求的动作。这种方法避免了直接在HAR数据集上训练T2M模型,从而降低了对大规模标注数据的依赖。
关键设计:KineMIC框架的关键设计包括:1) 使用CLIP模型提取文本嵌入,以捕捉文本的语义信息;2) 设计运动挖掘策略,利用文本嵌入的相似度来建立HAR标签和T2M数据之间的对应关系;3) 使用扩散模型作为T2M的骨干网络,以生成高质量的动作数据;4) 设计合适的损失函数,指导T2M模型进行微调,使其能够生成更符合HAR任务需求的动作。
🖼️ 关键图片

📊 实验亮点
实验结果表明,KineMIC框架在NTU RGB+D 120数据集上,仅使用每个动作类别10个样本进行训练,即可获得显著的性能提升,准确率提升了23.1%。这表明KineMIC能够有效地利用T2M模型中的知识,生成高质量的动作数据,从而提高HAR模型的性能。
🎯 应用场景
KineMIC框架可应用于各种需要人体动作识别的场景,如智能监控、人机交互、康复训练等。该方法能够有效解决标注数据不足的问题,降低模型训练成本,提高动作识别的准确率和鲁棒性。未来可进一步扩展到其他模态的数据增强,例如结合图像或视频信息。
📄 摘要(原文)
The acquisition cost for large, annotated motion datasets remains a critical bottleneck for skeletal-based Human Activity Recognition (HAR). Although Text-to-Motion (T2M) generative models offer a compelling, scalable source of synthetic data, their training objectives, which emphasize general artistic motion, and dataset structures fundamentally differ from HAR's requirements for kinematically precise, class-discriminative actions. This disparity creates a significant domain gap, making generalist T2M models ill-equipped for generating motions suitable for HAR classifiers. To address this challenge, we propose KineMIC (Kinetic Mining In Context), a transfer learning framework for few-shot action synthesis. KineMIC adapts a T2M diffusion model to an HAR domain by hypothesizing that semantic correspondences in the text encoding space can provide soft supervision for kinematic distillation. We operationalize this via a kinetic mining strategy that leverages CLIP text embeddings to establish correspondences between sparse HAR labels and T2M source data. This process guides fine-tuning, transforming the generalist T2M backbone into a specialized few-shot Action-to-Motion generator. We validate KineMIC using HumanML3D as the source T2M dataset and a subset of NTU RGB+D 120 as the target HAR domain, randomly selecting just 10 samples per action class. Our approach generates significantly more coherent motions, providing a robust data augmentation source that delivers a +23.1% accuracy points improvement. Animated illustrations and supplementary materials are available at https://lucazzola.github.io/publications/kinemic.