Evaluating Foundation Models' 3D Understanding Through Multi-View Correspondence Analysis
作者: Valentina Lilova, Toyesh Chakravorty, Julian I. Bibo, Emma Boccaletti, Brandon Li, Lívia Baxová, Cees G. M. Snoek, Mohammadreza Salehi
分类: cs.CV
发布日期: 2025-12-12 (更新: 2026-01-15)
备注: NeurIPS 2025 UniReps workshop, to be published in PMLR
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于多视角对应分析的3D理解能力评估基准,无需微调。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D场景理解 基础模型 多视角学习 无微调评估 视觉特征 对应分析 机器人 自动驾驶
📋 核心要点
- 现有3D理解评估依赖下游微调,难以隔离预训练编码器的固有3D推理能力。
- 提出一种无需微调的上下文3D场景理解基准,直接探测密集视觉特征质量。
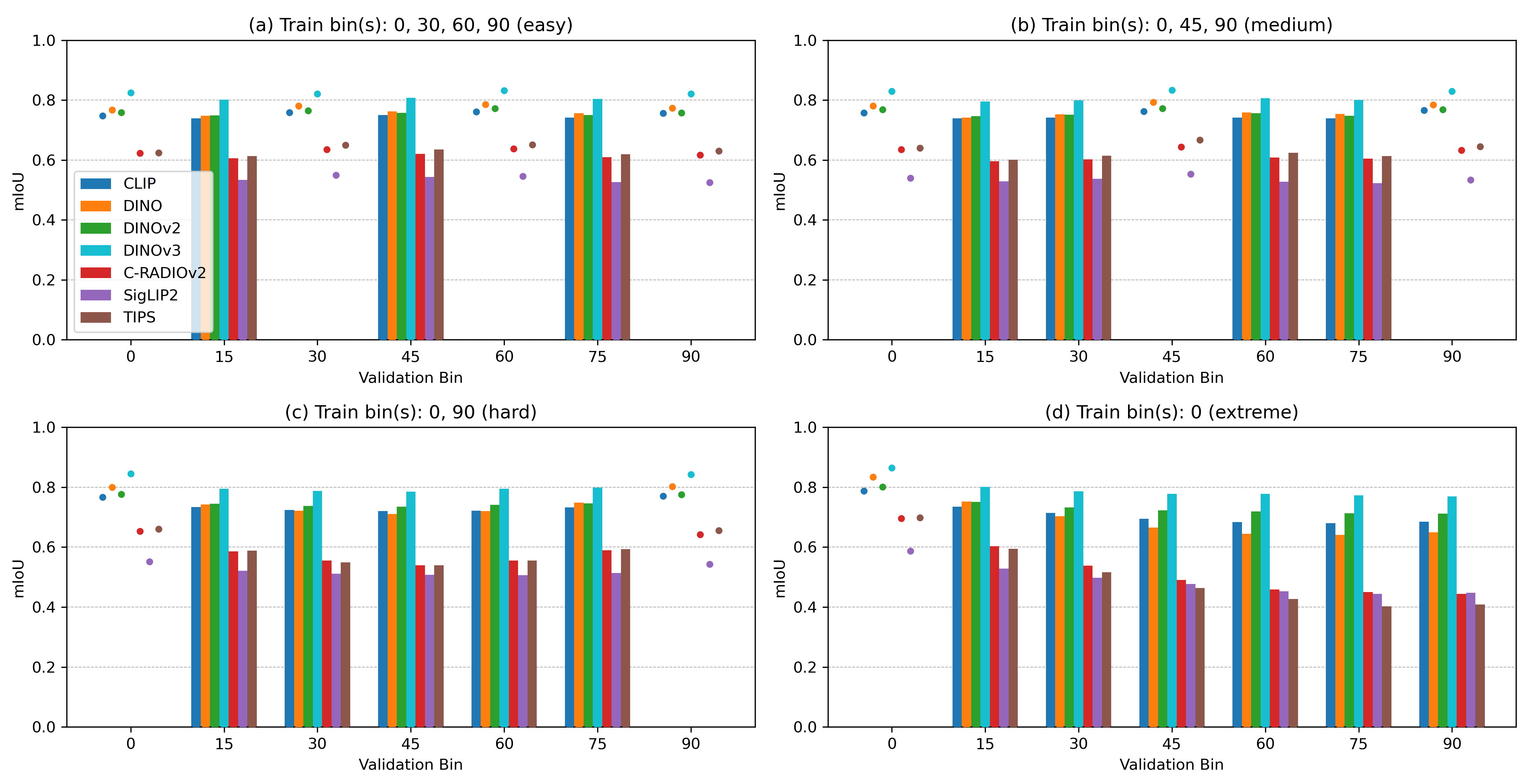
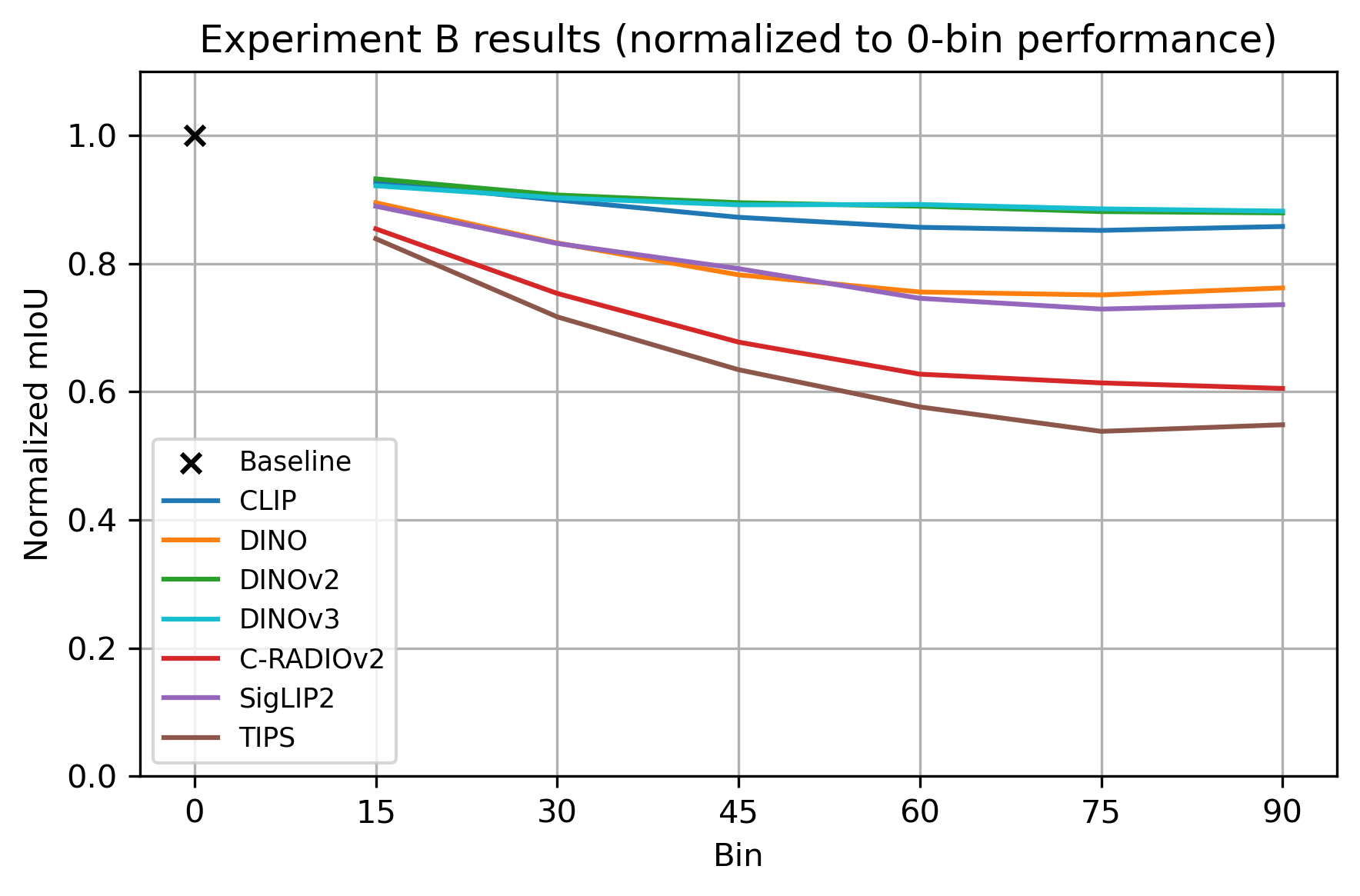
- 在MVImgNet数据集上评估多个模型,发现DINO类编码器在大视角变化下表现出色。
📝 摘要(中文)
本文提出了一种新的基准,用于评估基础模型在3D空间理解方面的能力。该基准通过多视角对应分析,直接探测密集视觉特征的质量,无需下游微调。该方法扩展了Hummingbird框架,将其应用于3D Multi-View ImageNet (MVImgNet)数据集,以评估上下文2D场景理解。给定一组特定相机角度的物体图像(keys),该基准评估分割新视角图像(queries)的性能,并根据key-query视角差异,将结果分为简单、中等、困难和极端四个类别。对7个最先进的基础模型进行了基准测试,结果表明,基于DINO的编码器在较大视角变化下仍具有竞争力。代码已公开。
🔬 方法详解
问题定义:论文旨在解决如何有效评估基础模型在3D场景理解方面的能力,尤其是在不进行微调的情况下。现有方法通常依赖于下游任务的微调,这使得评估结果受到微调策略的影响,难以准确反映预训练模型本身的3D推理能力。此外,缺乏一个专门针对3D场景理解的、无需微调的评估基准。
核心思路:论文的核心思路是利用多视角图像之间的对应关系来评估模型的3D理解能力。通过给定一组已知视角的图像(keys),模型需要分割出未知视角(queries)的图像中的物体。这种方法直接探测模型提取的视觉特征的质量,而无需额外的任务特定层或微调。
技术框架:整体框架基于Hummingbird,扩展到3D领域。具体流程如下:1)输入:一组已知视角的图像(keys)和待分割的未知视角图像(query);2)特征提取:使用基础模型(如DINO)提取keys和query图像的密集视觉特征;3)对应关系建立:利用keys图像的特征和query图像的特征,建立像素级别的对应关系;4)分割:基于建立的对应关系,将keys图像的分割信息传递到query图像,从而实现query图像的分割;5)评估:根据分割结果与ground truth的差异,评估模型的性能。
关键创新:该方法最重要的创新点在于提出了一个无需微调的3D场景理解评估基准。与现有方法相比,该基准能够更直接地反映预训练模型本身的3D推理能力,避免了微调带来的偏差。此外,该方法利用多视角图像之间的对应关系,能够有效地评估模型在不同视角下的泛化能力。
关键设计:该方法的关键设计包括:1)使用MVImgNet数据集,该数据集包含同一物体在不同视角下的图像,为多视角对应分析提供了基础;2)采用基于DINO的编码器,DINO在自监督学习方面表现出色,能够提取高质量的视觉特征;3)根据key-query视角差异,将评估结果分为不同难度等级,从而更全面地评估模型的性能;4)使用标准的分割指标(如IoU)来评估分割结果的准确性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,基于DINO的编码器在MVImgNet数据集上表现出色,尤其是在较大视角变化下,仍然能够保持较高的分割精度。该研究还对其他几个流行的基础模型进行了评估,并分析了它们在不同难度等级下的性能差异。结果表明,视角变化是影响模型性能的关键因素。
🎯 应用场景
该研究成果可应用于机器人、自动驾驶等领域,帮助提升机器在复杂3D环境中的感知和理解能力。通过评估不同基础模型的3D理解能力,可以为下游任务选择合适的模型,并指导模型的设计和训练。此外,该基准还可以用于评估新提出的3D理解算法的性能。
📄 摘要(原文)
Benchmarking 3D spatial understanding of foundation models is essential for real-world applications such as robotics and autonomous driving. Existing evaluations often rely on downstream fine-tuning with linear heads or task-specific decoders, making it difficult to isolate the intrinsic 3D reasoning ability of pre-trained encoders. In this work, we introduce a novel benchmark for in-context 3D scene understanding that requires no fine-tuning and directly probes the quality of dense visual features. Building on the Hummingbird framework, which evaluates in-context 2D scene understanding, we extend the setup to the 3D Multi-View ImageNet (MVImgNet) dataset. Given a set of images depicting objects at specific camera angles (keys), we benchmark the performance of segmenting novel views (queries) and report the scores in 4 categories of easy, medium, hard, and extreme based on the key-query view contrast. We benchmark 7 state-of-the-art foundation models and show that DINO-based encoders remain competitive across large viewpoint shifts. Our code is publicly available at https://github.com/ToyeshC/open-hummingbird-3d-eval.