DentalGPT: Incentivizing Multimodal Complex Reasoning in Dentistry
作者: Zhenyang Cai, Jiaming Zhang, Junjie Zhao, Ziyi Zeng, Yanchao Li, Jingyi Liang, Junying Chen, Yunjin Yang, Jiajun You, Shuzhi Deng, Tongfei Wang, Wanting Chen, Chunxiu Hao, Ruiqi Xie, Zhenwei Wen, Xiangyi Feng, Zou Ting, Jin Zou Lin, Jianquan Li, Guangjun Yu, Liangyi Chen, Junwen Wang, Shan Jiang, Benyou Wang
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-12-12
💡 一句话要点
DentalGPT:通过激励多模态复杂推理提升牙科自动化水平
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 牙科 多模态学习 大型语言模型 计算机视觉 医疗诊断 强化学习 领域知识注入
📋 核心要点
- 现有MLLM在牙科领域应用受限,无法有效捕捉牙科图像的细粒度视觉特征,推理能力不足。
- DentalGPT通过构建大规模牙科多模态数据集,并结合强化学习,提升模型对牙科图像的理解和推理能力。
- 实验结果表明,DentalGPT在牙科疾病分类和VQA任务中表现优异,超越了许多参数量更大的SOTA模型。
📝 摘要(中文)
牙科领域多模态数据的可靠解读对于自动化口腔健康至关重要,但当前的多模态大型语言模型(MLLM)难以捕捉精细的牙科视觉细节,并且缺乏足够的推理能力来进行精确诊断。为了解决这些限制,我们提出了DentalGPT,一种通过高质量领域知识注入和强化学习开发的专用牙科MLLM。具体来说,我们构建了迄今为止最大的带注释的牙科多模态数据集,该数据集汇集了超过12万张牙科图像,并配有详细的描述,突出了与诊断相关的视觉特征,使其成为迄今为止牙科图像收集最广泛的多模态数据集。基于该数据集的训练显著增强了MLLM对牙科状况的视觉理解,随后的强化学习阶段进一步加强了其多模态复杂推理能力。在口内和全景基准以及医学VQA基准的牙科子集上的综合评估表明,DentalGPT在疾病分类和牙科VQA任务中取得了优异的性能,优于许多最先进的MLLM,尽管只有70亿个参数。这些结果表明,高质量的牙科数据与分阶段的适应相结合,为构建有能力的、领域专业的牙科MLLM提供了一条有效的途径。
🔬 方法详解
问题定义:论文旨在解决现有通用多模态大语言模型(MLLM)在牙科领域应用时,无法有效理解牙科图像中的细微视觉特征,以及缺乏足够的推理能力进行准确诊断的问题。现有方法通常依赖通用数据集进行训练,缺乏针对牙科领域的专业知识,导致模型在牙科相关任务中表现不佳。
核心思路:论文的核心思路是通过构建大规模、高质量的牙科多模态数据集,并结合领域知识注入和强化学习,来训练一个专门针对牙科领域的MLLM。这种方法旨在让模型能够更好地理解牙科图像中的视觉信息,并具备更强的推理能力,从而提高在牙科相关任务中的性能。
技术框架:DentalGPT的整体框架包含以下几个主要阶段:1) 构建大规模牙科多模态数据集:收集并标注超过12万张牙科图像,并配以详细的描述,突出与诊断相关的视觉特征。2) 领域知识注入:利用构建的数据集对MLLM进行预训练,使其具备初步的牙科领域知识。3) 强化学习:通过强化学习进一步提升模型的多模态复杂推理能力。4) 评估:在口内和全景基准以及医学VQA基准的牙科子集上对模型进行评估。
关键创新:论文的关键创新在于:1) 构建了迄今为止最大的带注释的牙科多模态数据集,为牙科MLLM的训练提供了高质量的数据基础。2) 提出了结合领域知识注入和强化学习的分阶段训练方法,有效提升了模型在牙科领域的视觉理解和推理能力。3) 证明了即使参数量较小(7B),通过高质量数据和针对性训练,也能超越许多参数量更大的通用MLLM。
关键设计:论文中关于数据集构建的关键设计包括:图像的多样性(口内、全景等)、标注的详细程度(突出诊断相关特征)。强化学习阶段的具体奖励函数和策略优化方法未知,但推测是针对牙科诊断的准确性和合理性进行设计的。具体的网络结构细节未在摘要中提及,但可以推断是基于现有MLLM架构进行修改和优化的。
🖼️ 关键图片
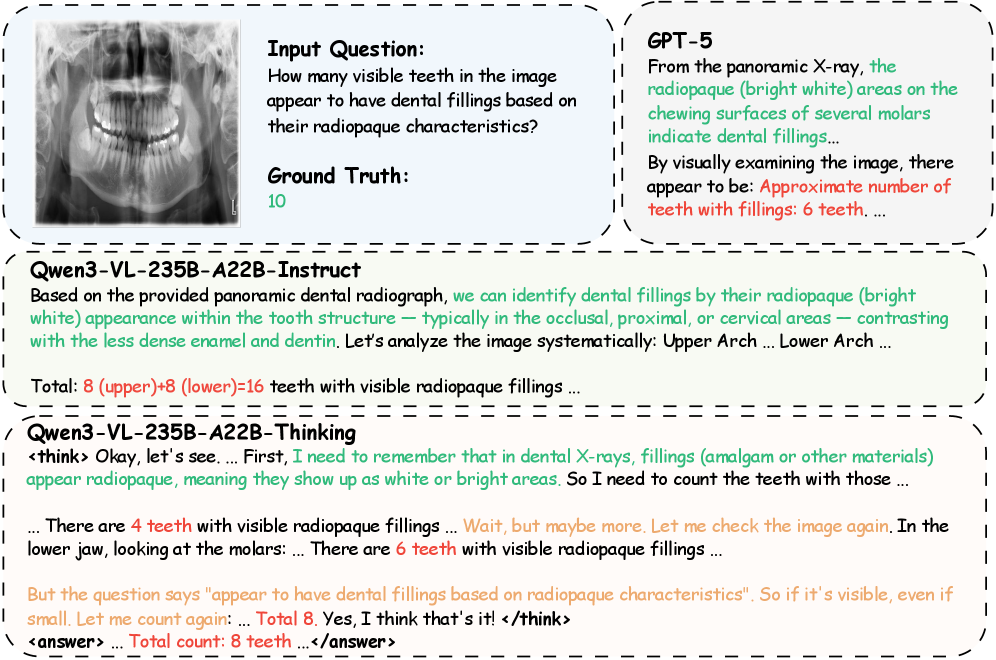
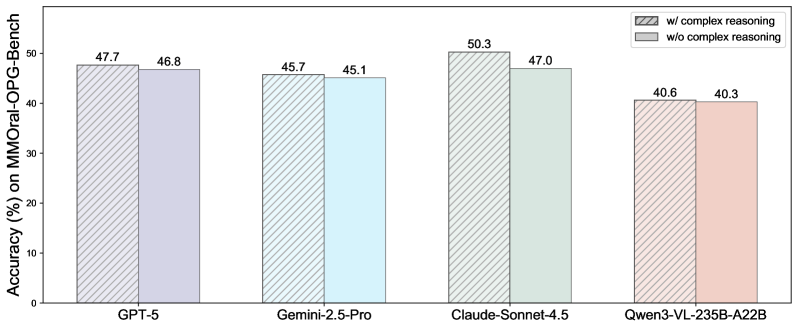
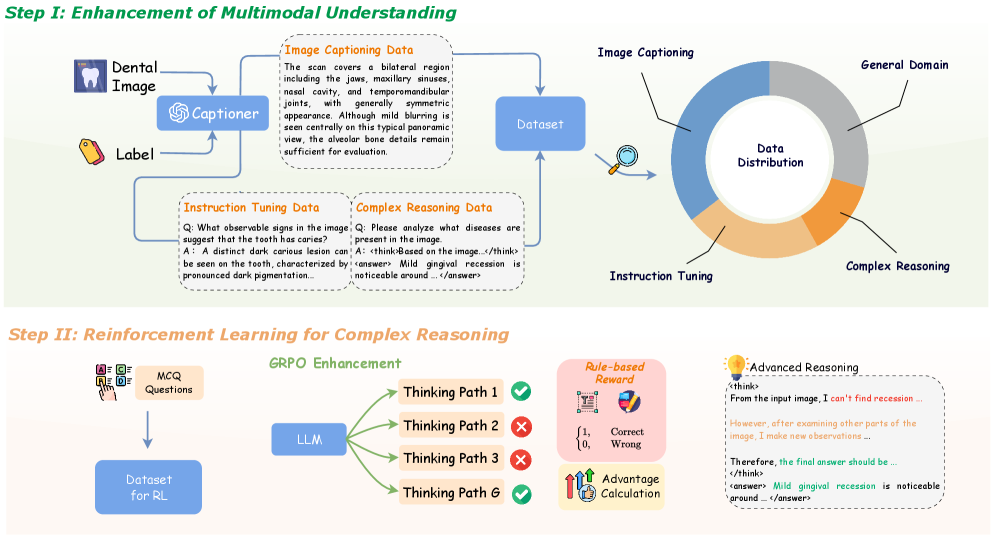
📊 实验亮点
DentalGPT在牙科疾病分类和牙科VQA任务中取得了显著的性能提升,超越了许多state-of-the-art的MLLM,尽管其参数量仅为7B。具体性能数据未在摘要中给出,但强调了其优于现有模型的表现,证明了高质量牙科数据和分阶段训练的有效性。
🎯 应用场景
DentalGPT有望应用于自动化牙科诊断、治疗方案推荐、患者教育等领域。通过分析牙科图像和相关文本信息,辅助医生进行更准确、高效的诊断,提高医疗服务质量。未来,该技术还可用于远程医疗、口腔健康监测等方面,具有广阔的应用前景。
📄 摘要(原文)
Reliable interpretation of multimodal data in dentistry is essential for automated oral healthcare, yet current multimodal large language models (MLLMs) struggle to capture fine-grained dental visual details and lack sufficient reasoning ability for precise diagnosis. To address these limitations, we present DentalGPT, a specialized dental MLLM developed through high-quality domain knowledge injection and reinforcement learning. Specifically, the largest annotated multimodal dataset for dentistry to date was constructed by aggregating over 120k dental images paired with detailed descriptions that highlight diagnostically relevant visual features, making it the multimodal dataset with the most extensive collection of dental images to date. Training on this dataset significantly enhances the MLLM's visual understanding of dental conditions, while the subsequent reinforcement learning stage further strengthens its capability for multimodal complex reasoning. Comprehensive evaluations on intraoral and panoramic benchmarks, along with dental subsets of medical VQA benchmarks, show that DentalGPT achieves superior performance in disease classification and dental VQA tasks, outperforming many state-of-the-art MLLMs despite having only 7B parameters. These results demonstrate that high-quality dental data combined with staged adaptation provides an effective pathway for building capable and domain-specialized dental MLLMs.