3DTeethSAM: Taming SAM2 for 3D Teeth Segmentation
作者: Zhiguo Lu, Jianwen Lou, Mingjun Ma, Hairong Jin, Youyi Zheng, Kun Zhou
分类: cs.CV
发布日期: 2025-12-12
备注: Accepted by AAAI 2026
💡 一句话要点
3DTeethSAM:利用SAM2进行3D牙齿分割,实现牙科数字化
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D牙齿分割 SAM2 数字化牙科 医学图像分割 深度学习
📋 核心要点
- 现有3D牙齿分割方法难以应对真实牙列的复杂性,分割精度和效率有待提高。
- 3DTeethSAM通过渲染2D图像,利用SAM2的强大分割能力,并结合轻量级模块进行优化。
- 实验表明,3DTeethSAM在3DTeethSeg基准上取得了91.90%的IoU,达到了新的SOTA。
📝 摘要(中文)
本文提出3DTeethSAM,一种用于3D牙齿分割的Segment Anything Model 2 (SAM2)的改进方法。3D牙齿分割,包括在3D牙科模型中定位牙齿实例并进行语义分类,是数字化牙科中一项关键但具有挑战性的任务,因为真实牙列的复杂性。SAM2是一个预训练的图像和视频分割基础模型,在各种下游场景中表现出强大的骨干网络。为了使SAM2适应3D牙齿数据,我们从预定义的视图渲染3D牙齿模型的图像,应用SAM2进行2D分割,并使用2D-3D投影重建3D结果。由于SAM2的性能取决于输入提示,并且其初始输出通常存在缺陷,并且鉴于其类别不可知性,我们引入了三个轻量级的可学习模块:(1)提示嵌入生成器,用于从图像嵌入中导出提示嵌入,以进行精确的掩码解码,(2)掩码细化器,用于增强SAM2的初始分割结果,以及(3)掩码分类器,用于对生成的掩码进行分类。此外,我们将可变形全局注意力插件(DGAP)集成到SAM2的图像编码器中。DGAP提高了分割精度和训练速度。我们的方法已在3DTeethSeg基准上得到验证,在高分辨率3D牙齿网格上实现了91.90%的IoU,在该领域建立了新的最先进水平。
🔬 方法详解
问题定义:3D牙齿分割旨在从3D牙科模型中准确地分割出每个牙齿实例,并进行语义分类。现有方法在处理复杂牙列时,分割精度和效率较低,难以满足实际应用需求。此外,现有方法通常需要大量标注数据进行训练,泛化能力有限。
核心思路:本文的核心思路是利用预训练的SAM2模型强大的2D分割能力,结合2D-3D投影,实现高效准确的3D牙齿分割。通过引入轻量级可学习模块,弥补SAM2在3D牙齿分割任务中的不足,并提高分割精度和效率。
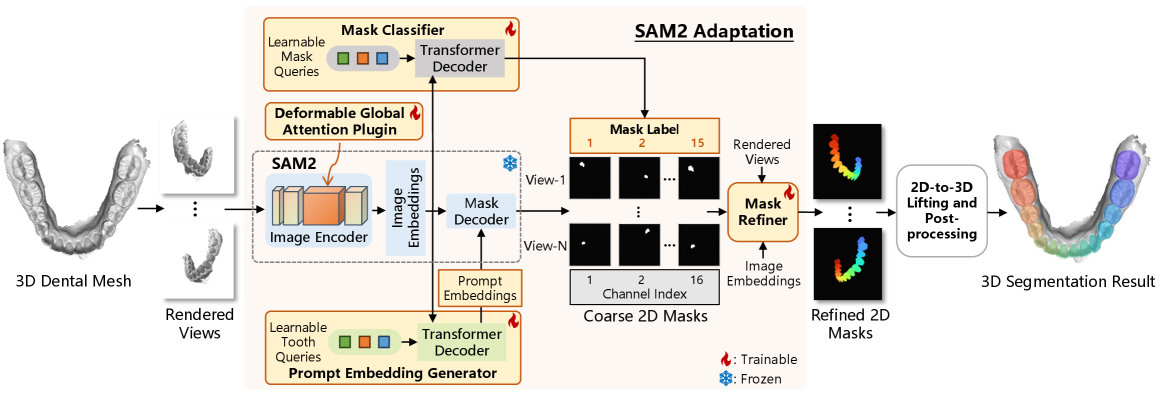
技术框架:3DTeethSAM的整体框架包括以下几个主要阶段:(1)3D牙齿模型渲染:从预定义的视角渲染3D牙齿模型的2D图像。(2)SAM2分割:使用SAM2对2D图像进行分割,生成初始的分割掩码。(3)掩码优化:通过提示嵌入生成器、掩码细化器和掩码分类器等模块,对SAM2的初始分割结果进行优化。(4)3D重建:利用2D-3D投影,将2D分割结果重建为3D分割结果。
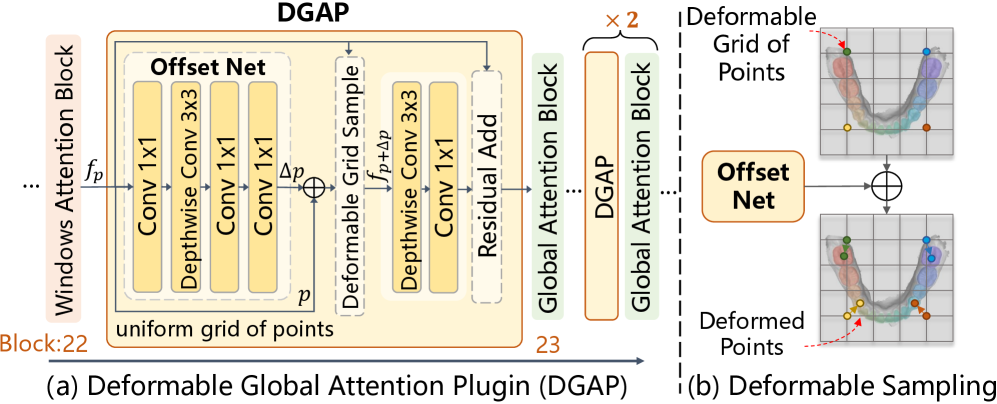
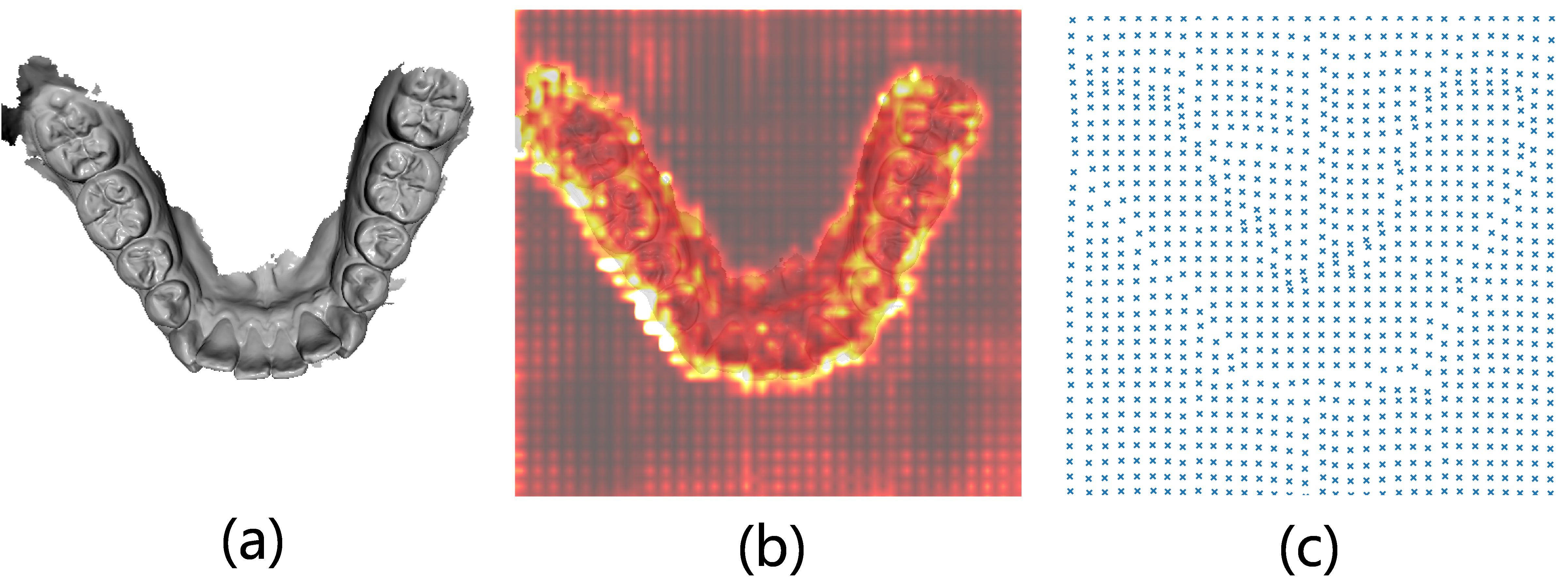
关键创新:本文的关键创新在于:(1)将SAM2应用于3D牙齿分割任务,充分利用了预训练模型的强大能力。(2)引入了轻量级可学习模块,包括提示嵌入生成器、掩码细化器和掩码分类器,有效提高了分割精度和效率。(3)将可变形全局注意力插件(DGAP)集成到SAM2的图像编码器中,进一步提高了分割精度和训练速度。
关键设计:提示嵌入生成器用于从图像嵌入中生成精确的提示嵌入,以指导SAM2进行掩码解码。掩码细化器用于增强SAM2的初始分割结果,提高分割精度。掩码分类器用于对生成的掩码进行分类,实现牙齿实例的语义分割。DGAP通过可变形卷积,增强了图像编码器的全局感受野,提高了分割精度和训练速度。损失函数包括分割损失和分类损失,用于优化模型参数。
🖼️ 关键图片
📊 实验亮点
实验结果表明,3DTeethSAM在3DTeethSeg基准上取得了显著的性能提升,在高分辨率3D牙齿网格上实现了91.90%的IoU,超过了现有方法,达到了新的SOTA。与基线方法相比,3DTeethSAM在分割精度和效率方面均有明显优势,证明了该方法的有效性。
🎯 应用场景
3DTeethSAM在数字化牙科领域具有广泛的应用前景,例如辅助牙齿矫正、种植牙设计、牙科手术规划等。该研究可以提高牙科诊断和治疗的效率和精度,降低医疗成本,改善患者的治疗体验。未来,该方法可以进一步扩展到其他医学图像分割任务中,例如骨骼分割、器官分割等。
📄 摘要(原文)
3D teeth segmentation, involving the localization of tooth instances and their semantic categorization in 3D dental models, is a critical yet challenging task in digital dentistry due to the complexity of real-world dentition. In this paper, we propose 3DTeethSAM, an adaptation of the Segment Anything Model 2 (SAM2) for 3D teeth segmentation. SAM2 is a pretrained foundation model for image and video segmentation, demonstrating a strong backbone in various downstream scenarios. To adapt SAM2 for 3D teeth data, we render images of 3D teeth models from predefined views, apply SAM2 for 2D segmentation, and reconstruct 3D results using 2D-3D projections. Since SAM2's performance depends on input prompts and its initial outputs often have deficiencies, and given its class-agnostic nature, we introduce three light-weight learnable modules: (1) a prompt embedding generator to derive prompt embeddings from image embeddings for accurate mask decoding, (2) a mask refiner to enhance SAM2's initial segmentation results, and (3) a mask classifier to categorize the generated masks. Additionally, we incorporate Deformable Global Attention Plugins (DGAP) into SAM2's image encoder. The DGAP enhances both the segmentation accuracy and the speed of the training process. Our method has been validated on the 3DTeethSeg benchmark, achieving an IoU of 91.90% on high-resolution 3D teeth meshes, establishing a new state-of-the-art in the field.