HFS: Holistic Query-Aware Frame Selection for Efficient Video Reasoning
作者: Yiqing Yang, Kin-Man Lam
分类: cs.CV, cs.CL, cs.MM
发布日期: 2025-12-12
备注: 18 pages, 8 figures
💡 一句话要点
提出HFS框架,通过整体查询感知的帧选择实现高效视频推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 关键帧选择 视频理解 Chain-of-Thought 师生互学习 集合优化
📋 核心要点
- 现有关键帧选择方法独立评分,忽略了帧之间的关联性,导致选择结果冗余且非全局最优。
- HFS框架利用Chain-of-Thought引导小型语言模型生成任务相关的查询向量,动态评分并优化帧集合。
- 实验表明,HFS在多个视频理解基准测试中显著优于现有方法,验证了其有效性。
📝 摘要(中文)
视频理解中的关键帧选择面临巨大挑战。传统的top-K选择方法独立地对帧进行评分,通常无法优化整体选择。这种独立评分导致选择的帧在时间上聚集且视觉上冗余。此外,使用多模态大型语言模型(MLLM)离线生成的伪标签训练轻量级选择器,使得监督信号无法动态适应任务目标。为了解决这些限制,我们提出了一个端到端可训练的、任务自适应的帧选择框架。Chain-of-Thought方法引导小型语言模型(SLM)生成任务特定的隐式查询向量,这些向量与多模态特征结合,实现动态帧评分。我们进一步定义了一个连续的集合级别目标函数,该函数结合了相关性、覆盖率和冗余度,从而可以通过Gumbel-Softmax进行可微优化,以在集合级别选择最佳帧组合。最后,采用师生互学习,其中学生选择器(SLM)和教师推理器(MLLM)通过KL散度训练以对齐它们的帧重要性分布。结合交叉熵损失,这实现了端到端优化,消除了对静态伪标签的依赖。在包括Video-MME、LongVideoBench、MLVU和NExT-QA在内的各种基准测试中进行的实验表明,我们的方法明显优于现有方法。
🔬 方法详解
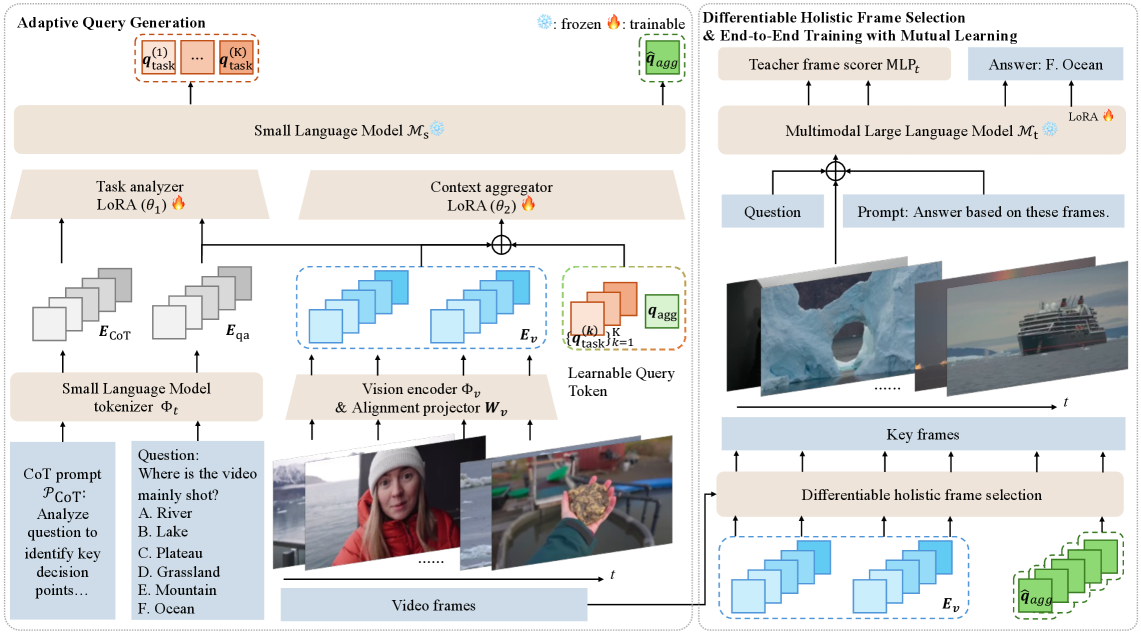
问题定义:论文旨在解决视频理解中关键帧选择的问题。现有方法,如top-K选择,独立评估每一帧的重要性,忽略了帧之间的相关性,导致选择的帧在时间上聚集,视觉上冗余,无法实现全局最优的帧集合选择。此外,使用MLLM离线生成的伪标签训练轻量级选择器,监督信号无法动态适应任务目标。
核心思路:论文的核心思路是提出一个端到端可训练的任务自适应框架,通过引入任务相关的查询向量和集合级别的优化目标,实现对帧集合的整体优化选择。利用Chain-of-Thought引导小型语言模型生成任务相关的隐式查询向量,结合多模态特征进行动态帧评分,并通过可微的集合级别目标函数优化帧组合。
技术框架:HFS框架主要包含以下几个模块:1) 小型语言模型(SLM):通过Chain-of-Thought生成任务特定的隐式查询向量。2) 多模态特征提取:提取视频帧的多模态特征,如视觉特征和文本特征。3) 动态帧评分:将查询向量与多模态特征结合,动态地对每一帧进行评分。4) 集合级别优化:定义一个连续的集合级别目标函数,该函数结合了相关性、覆盖率和冗余度,通过Gumbel-Softmax进行可微优化,选择最佳帧组合。5) 师生互学习:学生选择器(SLM)和教师推理器(MLLM)通过KL散度训练以对齐它们的帧重要性分布。
关键创新:论文的关键创新点在于:1) 提出了任务自适应的帧选择方法,通过引入任务相关的查询向量,动态地对帧进行评分。2) 定义了连续的集合级别目标函数,实现了对帧集合的整体优化选择。3) 采用师生互学习,消除了对静态伪标签的依赖,实现了端到端优化。
关键设计:1) Chain-of-Thought prompting:使用Chain-of-Thought方法引导小型语言模型生成任务特定的隐式查询向量。2) Gumbel-Softmax:使用Gumbel-Softmax技巧实现可微的帧集合选择。3) 集合级别目标函数:定义了一个连续的集合级别目标函数,该函数结合了相关性、覆盖率和冗余度。4) 师生互学习:使用KL散度作为损失函数,训练学生选择器(SLM)和教师推理器(MLLM)对齐帧重要性分布。
🖼️ 关键图片

📊 实验亮点
实验结果表明,HFS在Video-MME、LongVideoBench、MLVU和NExT-QA等多个视频理解基准测试中,显著优于现有方法。例如,在LongVideoBench数据集上,HFS的性能提升超过了10%。这证明了HFS框架在关键帧选择方面的有效性和优越性。
🎯 应用场景
该研究成果可应用于视频摘要、视频检索、视频问答等领域。通过选择最具代表性和信息量的关键帧,可以有效降低计算成本,提高视频处理效率。该方法在长视频理解和分析方面具有重要价值,有助于推动智能视频监控、在线教育等领域的发展。
📄 摘要(原文)
Key frame selection in video understanding presents significant challenges. Traditional top-K selection methods, which score frames independently, often fail to optimize the selection as a whole. This independent scoring frequently results in selecting frames that are temporally clustered and visually redundant. Additionally, training lightweight selectors using pseudo labels generated offline by Multimodal Large Language Models (MLLMs) prevents the supervisory signal from dynamically adapting to task objectives. To address these limitations, we propose an end-to-end trainable, task-adaptive framework for frame selection. A Chain-of-Thought approach guides a Small Language Model (SLM) to generate task-specific implicit query vectors, which are combined with multimodal features to enable dynamic frame scoring. We further define a continuous set-level objective function that incorporates relevance, coverage, and redundancy, enabling differentiable optimization via Gumbel-Softmax to select optimal frame combinations at the set level. Finally, student-teacher mutual learning is employed, where the student selector (SLM) and teacher reasoner (MLLM) are trained to align their frame importance distributions via KL divergence. Combined with cross-entropy loss, this enables end-to-end optimization, eliminating reliance on static pseudo labels. Experiments across various benchmarks, including Video-MME, LongVideoBench, MLVU, and NExT-QA, demonstrate that our method significantly outperforms existing approaches.