Exploring MLLM-Diffusion Information Transfer with MetaCanvas
作者: Han Lin, Xichen Pan, Ziqi Huang, Ji Hou, Jialiang Wang, Weifeng Chen, Zecheng He, Felix Juefei-Xu, Junzhe Sun, Zhipeng Fan, Ali Thabet, Mohit Bansal, Chu Wang
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-12-12
备注: Project page: https://metacanvas.github.io
💡 一句话要点
MetaCanvas:利用MLLM在扩散模型中进行空间推理和规划,提升多模态生成效果
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 扩散模型 大语言模型 视觉生成 潜在空间规划
📋 核心要点
- 现有视觉生成方法未能充分利用MLLM的推理和规划能力,导致生成结果在布局、属性控制等方面存在不足。
- MetaCanvas框架的核心思想是让MLLM直接在扩散模型的潜在空间中进行推理和规划,从而实现更精确的生成控制。
- 实验结果表明,MetaCanvas在多种生成任务上均优于现有方法,证明了其有效性以及MLLM作为潜在空间规划器的潜力。
📝 摘要(中文)
多模态学习通过利用多模态大语言模型(MLLM)作为认知核心,极大地促进了视觉理解。然而,在视觉生成领域,这些强大的核心模型通常被简化为扩散模型的全局文本编码器,导致其大部分推理和规划能力未被利用。这造成了一个差距:当前的多模态LLM能够解析复杂的布局、属性和知识密集型场景,但难以生成具有同样精确和结构化控制的图像或视频。我们提出了MetaCanvas,这是一个轻量级框架,允许MLLM直接在空间和时空潜在空间中进行推理和规划,并与扩散生成器紧密连接。我们在三种不同的扩散模型骨干网络上进行了MetaCanvas的实验,并在六个任务中对其进行了评估,包括文本到图像生成、文本/图像到视频生成、图像/视频编辑和上下文视频生成,每个任务都需要精确的布局、强大的属性绑定和推理密集型控制。MetaCanvas始终优于全局条件基线,表明将MLLM视为潜在空间规划器是缩小多模态理解和生成之间差距的一个有希望的方向。
🔬 方法详解
问题定义:现有方法在视觉生成任务中,通常将强大的多模态大语言模型(MLLM)降维为简单的全局文本编码器,无法充分利用MLLM的推理和规划能力。这导致生成的图像或视频在布局控制、属性绑定以及对知识密集型场景的理解方面存在不足,难以满足复杂生成任务的需求。现有方法的痛点在于MLLM的强大能力没有被有效利用,限制了生成结果的质量和可控性。
核心思路:MetaCanvas的核心思路是将MLLM视为一个潜在空间规划器,使其直接在扩散模型的潜在空间中进行推理和规划。通过这种方式,MLLM可以更好地理解和控制生成过程,从而生成具有更精确布局、更强属性绑定以及更符合知识逻辑的图像或视频。这种设计旨在弥合多模态理解和生成之间的差距,充分发挥MLLM的潜力。
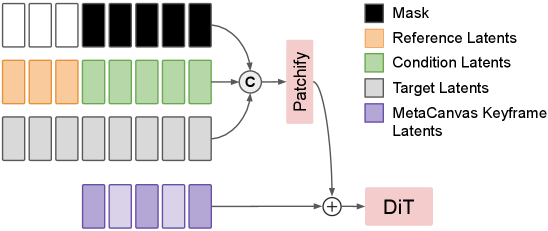
技术框架:MetaCanvas框架包含两个主要部分:MLLM规划器和扩散模型生成器。首先,MLLM接收文本或图像输入,并在潜在空间中生成布局、属性等规划信息。然后,这些规划信息被传递给扩散模型生成器,用于指导图像或视频的生成过程。框架通过轻量级的接口连接MLLM和扩散模型,实现MLLM对生成过程的精细控制。整体流程包括输入编码、MLLM潜在空间规划、扩散模型解码生成等步骤。
关键创新:MetaCanvas的关键创新在于将MLLM的角色从简单的文本编码器转变为潜在空间规划器。这种转变使得MLLM能够直接参与到生成过程的控制中,从而实现更精确、更可控的生成结果。与现有方法相比,MetaCanvas能够更好地利用MLLM的推理和规划能力,从而生成更符合用户意图的图像或视频。
关键设计:MetaCanvas采用轻量级的设计,以减少计算开销并提高效率。具体来说,MLLM的输出被设计为低维的潜在向量,以便于与扩散模型进行交互。此外,MetaCanvas还引入了一种新的损失函数,用于鼓励MLLM生成更符合用户意图的规划信息。具体的网络结构和参数设置根据不同的扩散模型骨干网络进行调整,以实现最佳性能。
🖼️ 关键图片


📊 实验亮点
MetaCanvas在六个不同的生成任务上进行了评估,包括文本到图像生成、文本/图像到视频生成、图像/视频编辑和上下文视频生成。实验结果表明,MetaCanvas在所有任务上均优于全局条件基线。例如,在文本到图像生成任务中,MetaCanvas生成的图像在视觉质量和语义一致性方面均有显著提升。具体性能提升幅度取决于任务和数据集,但总体而言,MetaCanvas能够有效提高生成结果的质量和可控性。
🎯 应用场景
MetaCanvas具有广泛的应用前景,包括图像和视频编辑、内容创作、虚拟现实、游戏开发等领域。它可以用于生成具有特定布局和属性的图像或视频,例如,根据文本描述生成具有特定场景和人物的动画短片。此外,MetaCanvas还可以用于图像修复和增强,例如,修复模糊的图像或提高图像的清晰度。该研究的实际价值在于提高了视觉生成的可控性和质量,未来可能推动多模态生成技术在各个领域的应用。
📄 摘要(原文)
Multimodal learning has rapidly advanced visual understanding, largely via multimodal large language models (MLLMs) that use powerful LLMs as cognitive cores. In visual generation, however, these powerful core models are typically reduced to global text encoders for diffusion models, leaving most of their reasoning and planning ability unused. This creates a gap: current multimodal LLMs can parse complex layouts, attributes, and knowledge-intensive scenes, yet struggle to generate images or videos with equally precise and structured control. We propose MetaCanvas, a lightweight framework that lets MLLMs reason and plan directly in spatial and spatiotemporal latent spaces and interface tightly with diffusion generators. We empirically implement MetaCanvas on three different diffusion backbones and evaluate it across six tasks, including text-to-image generation, text/image-to-video generation, image/video editing, and in-context video generation, each requiring precise layouts, robust attribute binding, and reasoning-intensive control. MetaCanvas consistently outperforms global-conditioning baselines, suggesting that treating MLLMs as latent-space planners is a promising direction for narrowing the gap between multimodal understanding and generation.