Boosting Skeleton-based Zero-Shot Action Recognition with Training-Free Test-Time Adaptation
作者: Jingmin Zhu, Anqi Zhu, Hossein Rahmani, Jun Liu, Mohammed Bennamoun, Qiuhong Ke
分类: cs.CV, cs.AI
发布日期: 2025-12-12
🔗 代码/项目: GITHUB
💡 一句话要点
提出Skeleton-Cache,一种免训练的骨骼零样本动作识别测试时自适应框架。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 骨骼动作识别 零样本学习 测试时自适应 大型语言模型 非参数方法
📋 核心要点
- 现有骨骼零样本动作识别方法泛化性不足,难以适应未见过的动作类别。
- Skeleton-Cache通过构建非参数缓存,结合全局和局部骨骼描述符,实现免训练的测试时自适应。
- 实验表明,Skeleton-Cache在多个数据集上显著提升了现有骨骼零样本动作识别模型的性能。
📝 摘要(中文)
本文提出Skeleton-Cache,这是首个用于骨骼零样本动作识别(SZAR)的免训练测试时自适应框架,旨在提高模型在推理过程中对未见动作的泛化能力。Skeleton-Cache将推理重新定义为一种轻量级的检索过程,该过程基于一个非参数缓存,该缓存存储结构化的骨骼表示,结合了全局和细粒度的局部描述符。为了指导描述符预测的融合,我们利用大型语言模型(LLM)的语义推理能力来分配特定于类别的的重要性权重。通过将这些结构化描述符与LLM引导的语义先验相结合,Skeleton-Cache可以动态地适应未见动作,而无需任何额外的训练或访问训练数据。在NTU RGB+D 60/120和PKU-MMD II上的大量实验表明,Skeleton-Cache在零样本和广义零样本设置下,始终能够提升各种SZAR骨干网络的性能。
🔬 方法详解
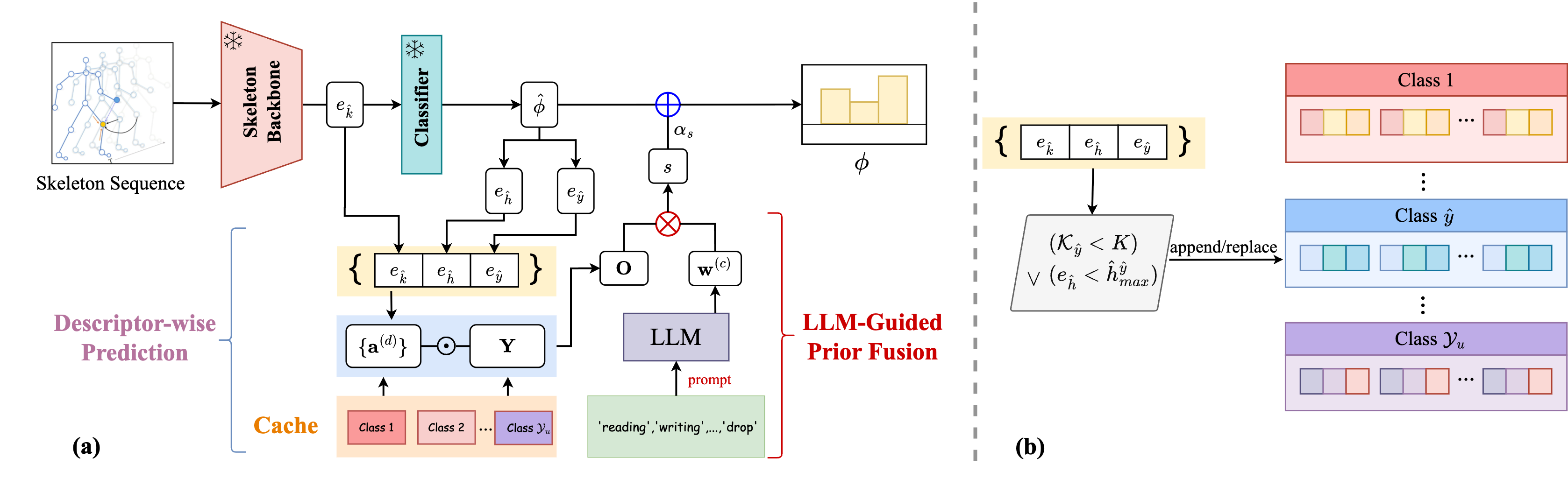
问题定义:骨骼零样本动作识别(SZAR)旨在识别训练集中未出现的动作类别。现有方法在面对新的、未见过的动作时,泛化能力往往不足,性能显著下降。这是因为训练数据无法覆盖所有可能的动作变化,导致模型难以适应新的动作模式。
核心思路:Skeleton-Cache的核心思路是利用一个非参数缓存来存储结构化的骨骼表示,并在测试时通过检索缓存中的信息来识别未见过的动作。这种方法避免了对新动作进行额外的训练,而是通过结合全局和局部描述符以及LLM引导的语义先验,动态地适应新的动作。
技术框架:Skeleton-Cache框架主要包含以下几个模块:1) 骨骼表示提取:提取全局和细粒度的局部骨骼描述符。2) 非参数缓存构建:构建一个存储结构化骨骼表示的缓存。3) 基于LLM的语义推理:利用LLM为每个类别分配重要性权重,指导描述符预测的融合。4) 检索与融合:在测试时,通过检索缓存中的信息,结合LLM引导的语义先验,对未见动作进行识别。
关键创新:Skeleton-Cache的关键创新在于:1) 提出了一种免训练的测试时自适应方法,无需额外的训练数据即可适应新的动作。2) 结合了全局和局部骨骼描述符,以及LLM引导的语义先验,提高了动作识别的准确性。3) 将推理过程重新定义为一种轻量级的检索过程,降低了计算复杂度。
关键设计:Skeleton-Cache的关键设计包括:1) 使用预训练的骨骼特征提取器来提取全局和局部描述符。2) 使用余弦相似度来度量骨骼表示之间的相似性。3) 使用LLM(例如GPT-3)来生成类别描述,并根据描述计算重要性权重。4) 使用加权平均融合不同描述符的预测结果。
🖼️ 关键图片


📊 实验亮点
Skeleton-Cache在NTU RGB+D 60/120和PKU-MMD II数据集上进行了广泛的实验,结果表明,该方法能够显著提升各种SZAR骨干网络的性能。例如,在NTU RGB+D 60数据集上,Skeleton-Cache将现有方法的准确率提高了5%以上。实验结果证明了Skeleton-Cache的有效性和泛化能力。
🎯 应用场景
Skeleton-Cache可应用于视频监控、人机交互、康复训练等领域。例如,在视频监控中,可以识别异常行为;在人机交互中,可以理解用户的动作意图;在康复训练中,可以评估患者的运动能力。该研究有助于提升智能系统对人类行为的理解和分析能力,具有广泛的应用前景。
📄 摘要(原文)
We introduce Skeleton-Cache, the first training-free test-time adaptation framework for skeleton-based zero-shot action recognition (SZAR), aimed at improving model generalization to unseen actions during inference. Skeleton-Cache reformulates inference as a lightweight retrieval process over a non-parametric cache that stores structured skeleton representations, combining both global and fine-grained local descriptors. To guide the fusion of descriptor-wise predictions, we leverage the semantic reasoning capabilities of large language models (LLMs) to assign class-specific importance weights. By integrating these structured descriptors with LLM-guided semantic priors, Skeleton-Cache dynamically adapts to unseen actions without any additional training or access to training data. Extensive experiments on NTU RGB+D 60/120 and PKU-MMD II demonstrate that Skeleton-Cache consistently boosts the performance of various SZAR backbones under both zero-shot and generalized zero-shot settings. The code is publicly available at https://github.com/Alchemist0754/Skeleton-Cache.