UFVideo: Towards Unified Fine-Grained Video Cooperative Understanding with Large Language Models
作者: Hewen Pan, Cong Wei, Dashuang Liang, Zepeng Huang, Pengfei Gao, Ziqi Zhou, Lulu Xue, Pengfei Yan, Xiaoming Wei, Minghui Li, Shengshan Hu
分类: cs.CV
发布日期: 2025-12-12
备注: 22 pages, 13 figures, technical report
💡 一句话要点
提出UFVideo,实现统一的多粒度视频协同理解的视频大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频大语言模型 多粒度理解 视觉-语言对齐 视频理解 多模态学习
📋 核心要点
- 现有视频LLM专注于特定任务,缺乏全面多粒度的视频理解能力。
- UFVideo通过统一的视觉-语言引导对齐,在单一模型中处理全局、像素和时间尺度的视频理解。
- UFVideo-Bench评估了模型在多粒度任务上的性能,验证了UFVideo的灵活性和优越性。
📝 摘要(中文)
随着多模态大语言模型(LLMs)的进步,视频LLMs得到了进一步发展,以执行整体和专业的视频理解。然而,现有的工作仅限于专业的视频理解任务,未能实现全面和多粒度的视频感知。为了弥合这一差距,我们推出了UFVideo,这是第一个具有统一多粒度协同理解能力的视频LLM。具体来说,我们设计了统一的视觉-语言引导对齐,以在单个模型中灵活地处理跨全局、像素和时间尺度的视频理解。UFVideo动态地编码不同任务的视觉和文本输入,并生成文本响应、时间定位或接地的掩码。此外,为了评估具有挑战性的多粒度视频理解任务,我们构建了UFVideo-Bench,它由尺度内的三个不同的协作任务组成,这证明了UFVideo相对于GPT-4o的灵活性和优势。此外,我们在涵盖各种常见视频理解任务的9个公共基准上验证了我们模型的有效性,为未来的视频LLMs提供了宝贵的见解。
🔬 方法详解
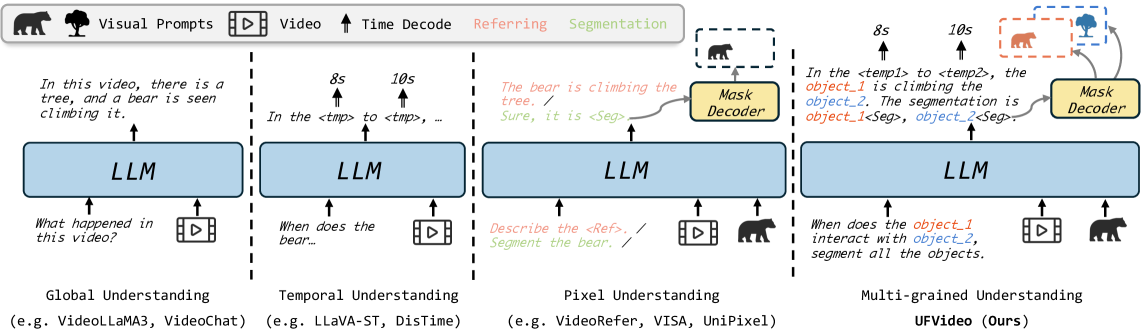
问题定义:现有视频大语言模型主要集中于特定领域的视频理解任务,例如视频问答或动作识别,缺乏对视频内容进行全面、多粒度的理解能力。它们难以同时处理全局语义信息、像素级别的细节以及时间维度的动态变化,限制了其在复杂视频场景中的应用。
核心思路:UFVideo的核心在于通过统一的视觉-语言引导对齐,将不同粒度的视频理解任务整合到一个模型中。该模型能够动态地编码视觉和文本输入,并根据任务需求生成相应的输出,包括文本回复、时间定位和像素级别的掩码。这种统一的设计使得模型能够灵活地处理不同类型的视频理解任务,并实现多粒度信息的协同理解。
技术框架:UFVideo的整体架构包含视觉编码器、文本编码器、视觉-语言对齐模块和任务解码器。视觉编码器负责提取视频帧的视觉特征,文本编码器负责提取文本输入的语义特征。视觉-语言对齐模块将视觉和文本特征对齐到统一的语义空间,从而实现跨模态的信息融合。任务解码器根据不同的任务类型生成相应的输出,例如文本回复、时间定位或像素级别的掩码。
关键创新:UFVideo的关键创新在于其统一的视觉-语言引导对齐机制,它能够灵活地处理不同粒度的视频理解任务。与现有方法相比,UFVideo无需针对不同的任务设计不同的模型结构,而是通过统一的框架实现多任务学习。此外,UFVideo还引入了UFVideo-Bench,这是一个专门用于评估多粒度视频理解能力的基准数据集。
关键设计:UFVideo使用了Transformer作为其核心架构,并采用了预训练-微调的训练策略。在预训练阶段,模型在大规模的视频和文本数据集上进行训练,以学习通用的视觉和语言表示。在微调阶段,模型在特定的视频理解任务上进行微调,以适应任务的需求。模型使用了交叉注意力机制来实现视觉和文本特征的对齐,并使用了不同的损失函数来优化不同任务的性能。
🖼️ 关键图片


📊 实验亮点
UFVideo在UFVideo-Bench上表现出优于GPT-4o的性能,证明了其在多粒度视频理解方面的优势。此外,UFVideo在9个公共基准数据集上进行了验证,涵盖了各种常见的视频理解任务,结果表明UFVideo具有良好的泛化能力和竞争力。
🎯 应用场景
UFVideo在视频监控、智能安防、自动驾驶、智能家居等领域具有广泛的应用前景。它可以用于视频内容分析、异常事件检测、人机交互等任务,提升系统的智能化水平和用户体验。未来,UFVideo有望成为视频理解领域的重要基石,推动相关技术的发展。
📄 摘要(原文)
With the advancement of multi-modal Large Language Models (LLMs), Video LLMs have been further developed to perform on holistic and specialized video understanding. However, existing works are limited to specialized video understanding tasks, failing to achieve a comprehensive and multi-grained video perception. To bridge this gap, we introduce UFVideo, the first Video LLM with unified multi-grained cooperative understanding capabilities. Specifically, we design unified visual-language guided alignment to flexibly handle video understanding across global, pixel and temporal scales within a single model. UFVideo dynamically encodes the visual and text inputs of different tasks and generates the textual response, temporal localization, or grounded mask. Additionally, to evaluate challenging multi-grained video understanding tasks, we construct the UFVideo-Bench consisting of three distinct collaborative tasks within the scales, which demonstrates UFVideo's flexibility and advantages over GPT-4o. Furthermore, we validate the effectiveness of our model across 9 public benchmarks covering various common video understanding tasks, providing valuable insights for future Video LLMs.