Robust MLLM Unlearning via Visual Knowledge Distillation
作者: Yuhang Wang, Zhenxing Niu, Haoxuan Ji, Guangyu He, Haichang Gao, Gang Hua
分类: cs.CV, cs.AI
发布日期: 2025-12-12 (更新: 2026-02-01)
💡 一句话要点
提出基于视觉知识蒸馏的MLLM稳健不可学习方法,解决视觉知识选择性擦除问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多模态大语言模型 机器不可学习 视觉知识蒸馏 知识解耦 隐私保护 重新学习攻击 模型安全
📋 核心要点
- 现有不可学习方法主要针对LLM,缺乏对MLLM中视觉知识选择性擦除的有效方案。
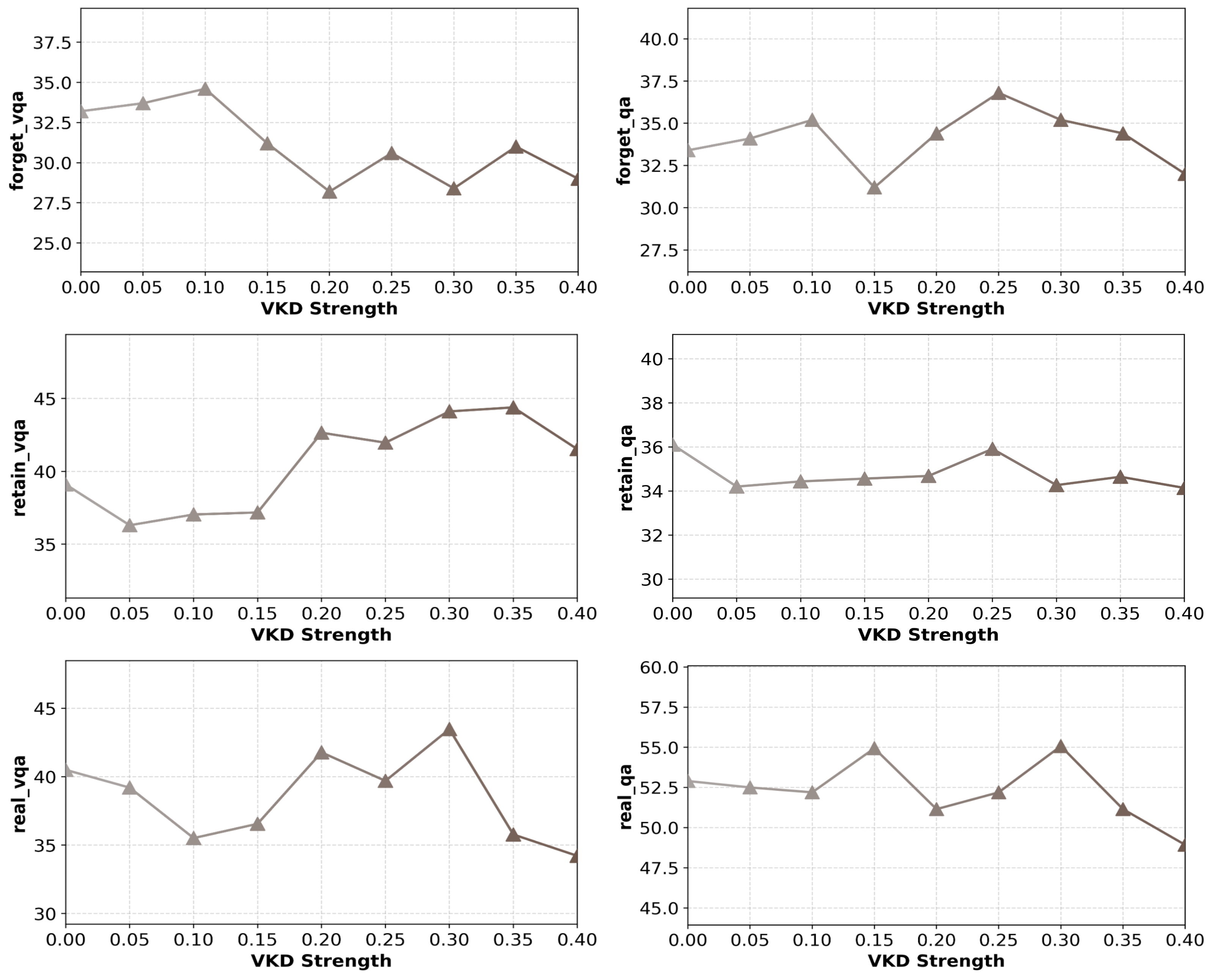
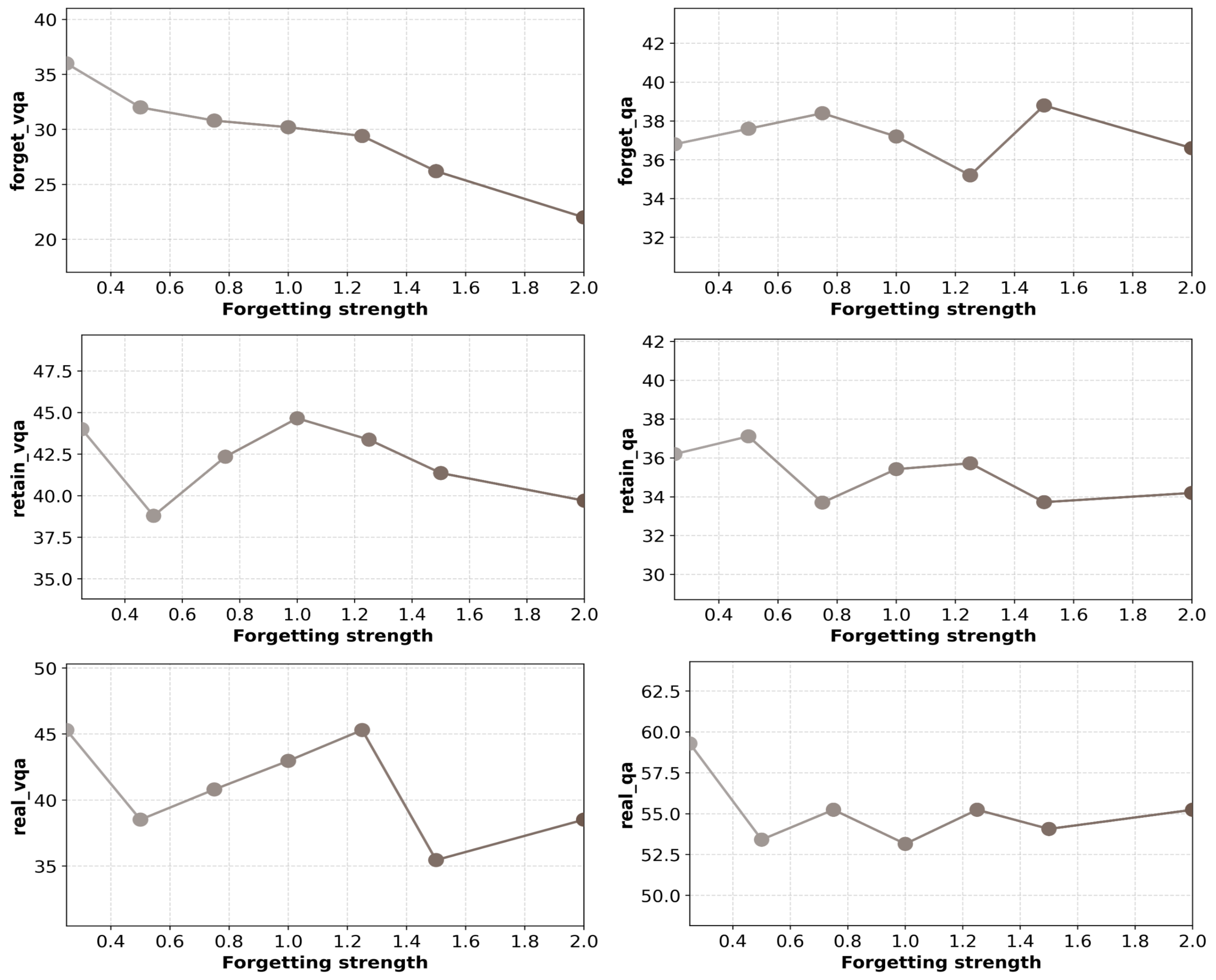
- 提出视觉知识蒸馏(VKD)方案,利用MLLM中间视觉表示作为监督信号,选择性擦除目标视觉知识并保留文本知识。
- 实验表明,该方法在不可学习的有效性和效率方面均优于现有方法,并首次评估了对重新学习攻击的鲁棒性。
📝 摘要(中文)
本文提出了一种针对多模态大语言模型(MLLM)的不可学习方法,旨在从模型中移除敏感信息。现有方法主要针对LLM,而MLLM的不可学习研究尚处于早期阶段。受MLLM内部机制研究的启发,本文提出解耦MLLM中嵌入的视觉和文本知识,并引入一种专门的方法来选择性地擦除目标视觉知识,同时保留文本知识。与依赖输出级别监督的现有方法不同,本文引入了视觉知识蒸馏(VKD)方案,该方案利用MLLM中的中间视觉表示作为监督信号,从而显著提高不可学习的有效性和模型效用。此外,由于该方法仅微调MLLM的视觉组件,因此具有显著的效率优势。大量实验表明,该方法在有效性和效率方面均优于最先进的不可学习方法。此外,本文首次评估了MLLM不可学习对重新学习攻击的鲁棒性。
🔬 方法详解
问题定义:现有的不可学习方法主要集中在LLM上,缺乏针对MLLM的有效解决方案。直接将LLM的不可学习方法应用于MLLM,无法很好地处理视觉和文本知识的复杂交互,导致擦除效果不佳或模型性能下降。此外,如何保证在擦除特定视觉知识的同时,保留模型原有的文本知识和泛化能力是一个挑战。
核心思路:本文的核心思路是将MLLM中的视觉和文本知识解耦,然后通过视觉知识蒸馏(VKD)选择性地擦除目标视觉知识。VKD利用MLLM内部的视觉表示作为监督信号,引导模型学习不包含目标视觉知识的新视觉表示。这种方法避免了直接在输出层进行监督,从而更好地保留了模型的文本知识和泛化能力。
技术框架:该方法主要包含以下几个阶段:1) 知识解耦:通过分析MLLM的内部结构,确定视觉和文本知识的表示层。2) 视觉知识蒸馏:使用VKD方案,利用中间视觉表示作为监督信号,训练一个新的视觉编码器,使其不包含目标视觉知识。3) 模型微调:将新的视觉编码器集成到MLLM中,并进行微调,以确保模型能够正常工作。
关键创新:该方法最重要的创新点在于引入了视觉知识蒸馏(VKD)方案。与传统的输出层监督方法不同,VKD利用中间视觉表示作为监督信号,能够更精确地控制知识擦除的过程,从而提高不可学习的有效性和模型效用。此外,该方法只微调MLLM的视觉组件,大大提高了效率。
关键设计:VKD方案的关键设计包括:1) 选择合适的中间视觉表示层:选择能够有效表示视觉知识,同时又不会过度影响文本知识的中间层。2) 设计合适的蒸馏损失函数:使用合适的损失函数来衡量新视觉编码器和原始视觉编码器之间的差异,从而引导新编码器学习不包含目标视觉知识的表示。3) 微调策略:采用合适的微调策略,以确保模型能够正常工作,并保留原有的文本知识和泛化能力。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在不可学习的有效性和效率方面均优于现有方法。具体而言,该方法能够在显著降低模型对目标视觉知识的记忆的同时,保持模型在其他任务上的性能。此外,该方法对重新学习攻击具有较强的鲁棒性,能够有效防止被擦除的知识被重新学习。
🎯 应用场景
该研究成果可应用于保护用户隐私、防止模型泄露敏感信息等场景。例如,在医疗影像分析中,可以擦除患者的身份信息,同时保留影像的诊断信息。在自动驾驶领域,可以擦除训练数据中的敏感场景,防止模型在实际应用中出现安全问题。该研究有助于推动安全可靠的MLLM应用。
📄 摘要(原文)
Recently, machine unlearning approaches have been proposed to remove sensitive information from well-trained large models. However, most existing methods are tailored for LLMs, while MLLM-oriented unlearning remains at its early stage. Inspired by recent studies exploring the internal mechanisms of MLLMs, we propose to disentangle the visual and textual knowledge embedded within MLLMs and introduce a dedicated approach to selectively erase target visual knowledge while preserving textual knowledge. Unlike previous unlearning methods that rely on output-level supervision, our approach introduces a Visual Knowledge Distillation (VKD) scheme, which leverages intermediate visual representations within the MLLM as supervision signals. This design substantially enhances both unlearning effectiveness and model utility. Moreover, since our method only fine-tunes the visual components of the MLLM, it offers significant efficiency advantages. Extensive experiments demonstrate that our approach outperforms state-of-the-art unlearning methods in terms of both effectiveness and efficiency. Moreover, we are the first to evaluate the robustness of MLLM unlearning against relearning attacks.