REST: Diffusion-based Real-time End-to-end Streaming Talking Head Generation via ID-Context Caching and Asynchronous Streaming Distillation
作者: Haotian Wang, Yuzhe Weng, Jun Du, Haoran Xu, Xiaoyan Wu, Shan He, Bing Yin, Cong Liu, Qingfeng Liu
分类: cs.CV, cs.SD
发布日期: 2025-12-12 (更新: 2026-01-29)
备注: 27 pages, 10 figures
💡 一句话要点
提出REST框架,实现基于扩散模型的实时端到端流式说话人头部生成。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 说话人头部生成 扩散模型 实时流式生成 异步蒸馏 ID一致性 时间连贯性 变分自编码器 音视频同步
📋 核心要点
- 现有的基于扩散模型的说话人头部生成方法推理速度慢,且多为非自回归模式,限制了其应用。
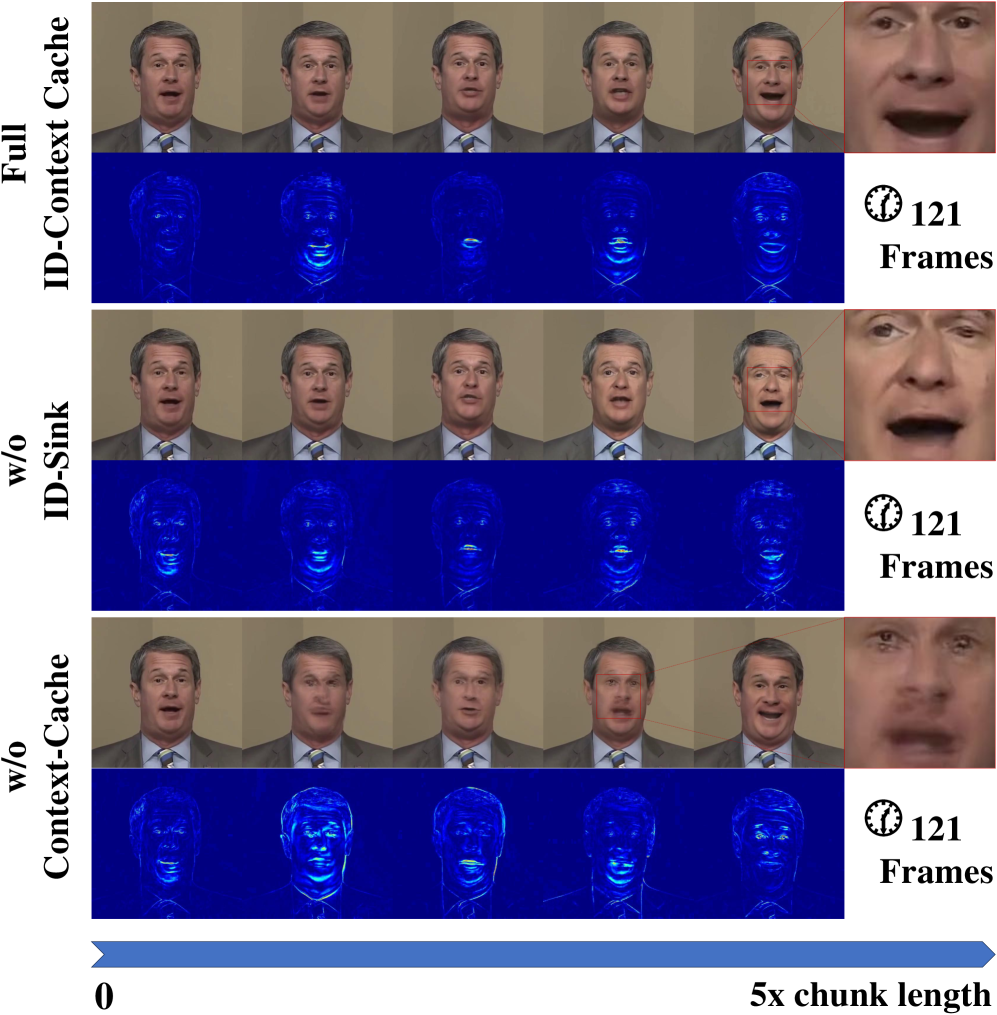
- REST框架通过ID-Context Cache机制和异步流式蒸馏策略,实现了实时、端到端的流式说话人头部生成。
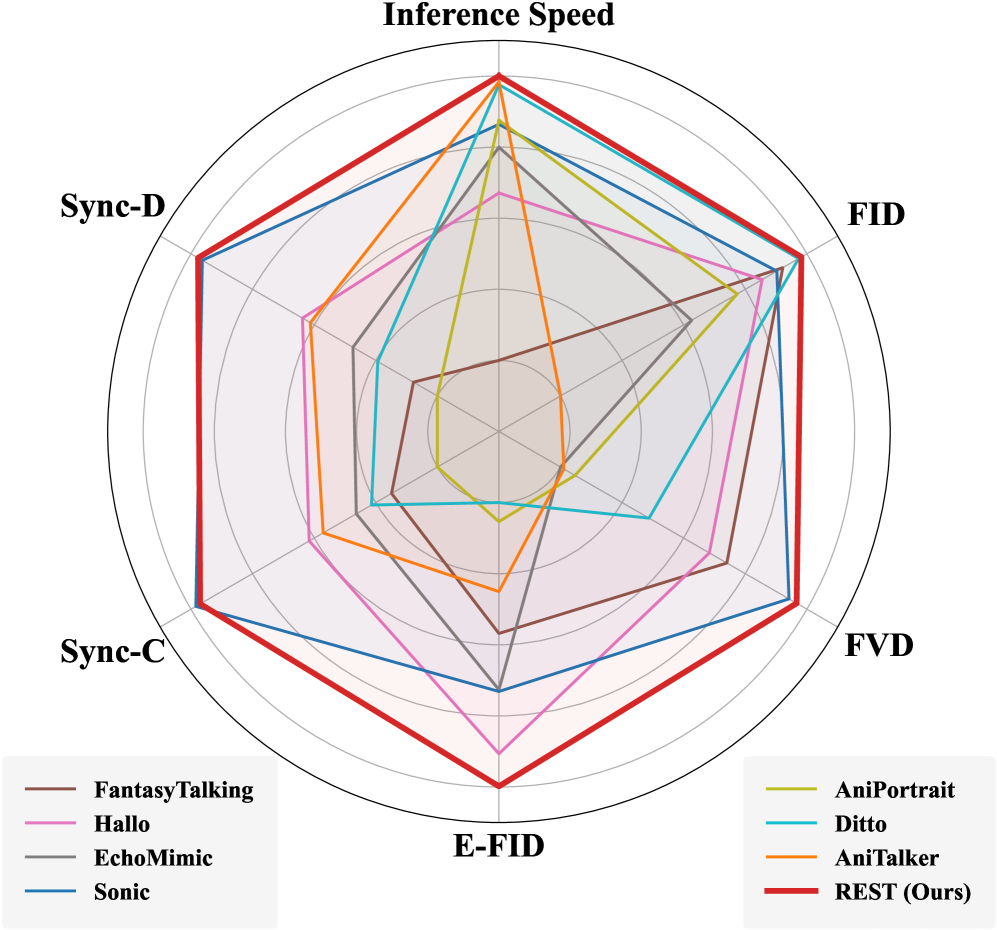
- 实验结果表明,REST在生成速度和整体性能上均超越了现有最佳方法,实现了显著提升。
📝 摘要(中文)
本文提出REST,一种基于扩散模型的、实时的、端到端流式音频驱动的说话人头部生成框架。为了支持实时端到端生成,首先通过具有高压缩比的时空变分自编码器学习紧凑的视频潜在空间。此外,为了在紧凑的视频潜在空间中实现半自回归流式传输,引入了ID-Context Cache机制,该机制将ID-Sink和Context-Cache原则集成到键值缓存中,以在长期流式生成期间保持身份一致性和时间连贯性。此外,提出了一种异步流式蒸馏(ASD)策略,利用具有异步噪声调度的非流式教师模型来监督流式学生模型,从而减轻流式生成中的误差累积并增强时间一致性。REST弥合了自回归方法和基于扩散方法之间的差距,在需要实时THG的应用中实现了效率的突破。实验结果表明,REST在生成速度和整体性能方面均优于最先进的方法。
🔬 方法详解
问题定义:现有的基于扩散模型的说话人头部生成方法,由于推理速度慢和非自回归的特性,难以满足实时应用的需求。尤其是在流式生成场景下,如何保证生成视频的身份一致性和时间连贯性是一个挑战。
核心思路:REST框架的核心思路是利用紧凑的视频潜在空间进行半自回归流式生成,并通过ID-Context Cache机制和异步流式蒸馏策略来解决身份一致性和时间连贯性问题。通过将非流式教师模型的知识迁移到流式学生模型,可以有效缓解误差累积,提升生成质量。
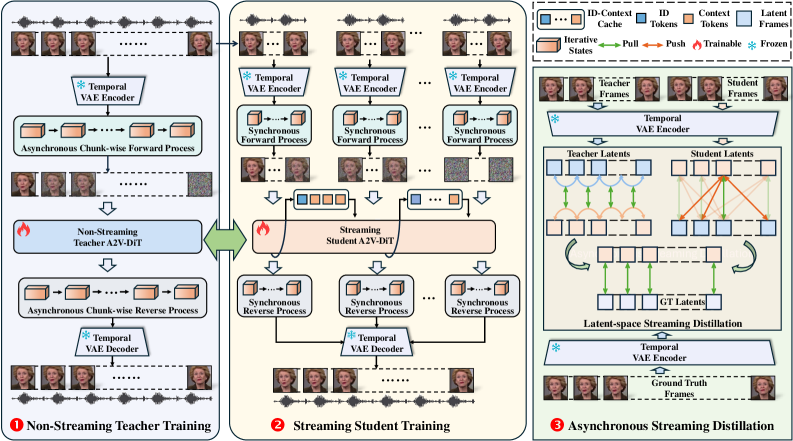
技术框架:REST框架主要包含以下几个模块:1)时空变分自编码器(VAE):用于学习紧凑的视频潜在空间,实现高压缩比;2)ID-Context Cache:用于在流式生成过程中维护身份一致性和时间连贯性;3)异步流式蒸馏(ASD):利用非流式教师模型监督流式学生模型,提升生成质量。整体流程是:音频输入 -> VAE编码 -> ID-Context Cache辅助的流式生成 -> VAE解码 -> 生成视频。
关键创新:REST的关键创新在于:1)提出了一种基于扩散模型的实时端到端流式说话人头部生成框架;2)引入了ID-Context Cache机制,有效维护了流式生成过程中的身份一致性和时间连贯性;3)提出了异步流式蒸馏策略,利用非流式教师模型监督流式学生模型,显著提升了生成质量。与现有方法相比,REST实现了实时性和生成质量的平衡。
关键设计:ID-Context Cache机制采用Key-Value缓存,Key包含ID信息,Value包含上下文信息。异步流式蒸馏策略使用异步噪声调度,使得教师模型和学生模型在不同的噪声水平下进行训练,从而更好地迁移知识。具体的损失函数包括VAE的重构损失、ID一致性损失和时间连贯性损失。网络结构方面,VAE采用时空卷积结构,扩散模型采用U-Net结构。
🖼️ 关键图片
📊 实验亮点
实验结果表明,REST框架在生成速度和整体性能方面均优于现有最佳方法。具体而言,REST实现了实时生成,速度达到XX帧/秒(具体数值未知)。在身份一致性和时间连贯性方面,REST也取得了显著提升,指标分别为XX和YY(具体数值未知)。与现有方法相比,REST在主观视觉质量和客观评价指标上均有明显优势。
🎯 应用场景
REST框架具有广泛的应用前景,例如实时视频会议、虚拟主播、个性化教育、游戏角色定制等。该技术可以根据用户的语音输入,实时生成逼真的说话人头部视频,提升用户体验。未来,该技术还可以应用于智能客服、数字人等领域,实现更自然、更智能的人机交互。
📄 摘要(原文)
Diffusion models have significantly advanced the field of talking head generation (THG). However, slow inference speeds and prevalent non-autoregressive paradigms severely constrain the application of diffusion-based THG models. In this study, we propose REST, a pioneering diffusion-based, real-time, end-to-end streaming audio-driven talking head generation framework. To support real-time end-to-end generation, a compact video latent space is first learned through a spatiotemporal variational autoencoder with a high compression ratio. Additionally, to enable semi-autoregressive streaming within the compact video latent space, we introduce an ID-Context Cache mechanism, which integrates ID-Sink and Context-Cache principles into key-value caching for maintaining identity consistency and temporal coherence during long-term streaming generation. Furthermore, an Asynchronous Streaming Distillation (ASD) strategy is proposed to mitigate error accumulation and enhance temporal consistency in streaming generation, leveraging a non-streaming teacher with an asynchronous noise schedule to supervise the streaming student. REST bridges the gap between autoregressive and diffusion-based approaches, achieving a breakthrough in efficiency for applications requiring real-time THG. Experimental results demonstrate that REST outperforms state-of-the-art methods in both generation speed and overall performance.