Reading or Reasoning? Format Decoupled Reinforcement Learning for Document OCR
作者: Yufeng Zhong, Lei Chen, Zhixiong Zeng, Xuanle Zhao, Deyang Jiang, Liming Zheng, Jing Huang, Haibo Qiu, Peng Shi, Siqi Yang, Lin Ma
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-12-11
备注: technical report
💡 一句话要点
提出格式解耦强化学习(FD-RL)以提升文档OCR模型在复杂格式文本上的识别能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 文档OCR 强化学习 格式解耦 高熵数据 OmniDocBench
📋 核心要点
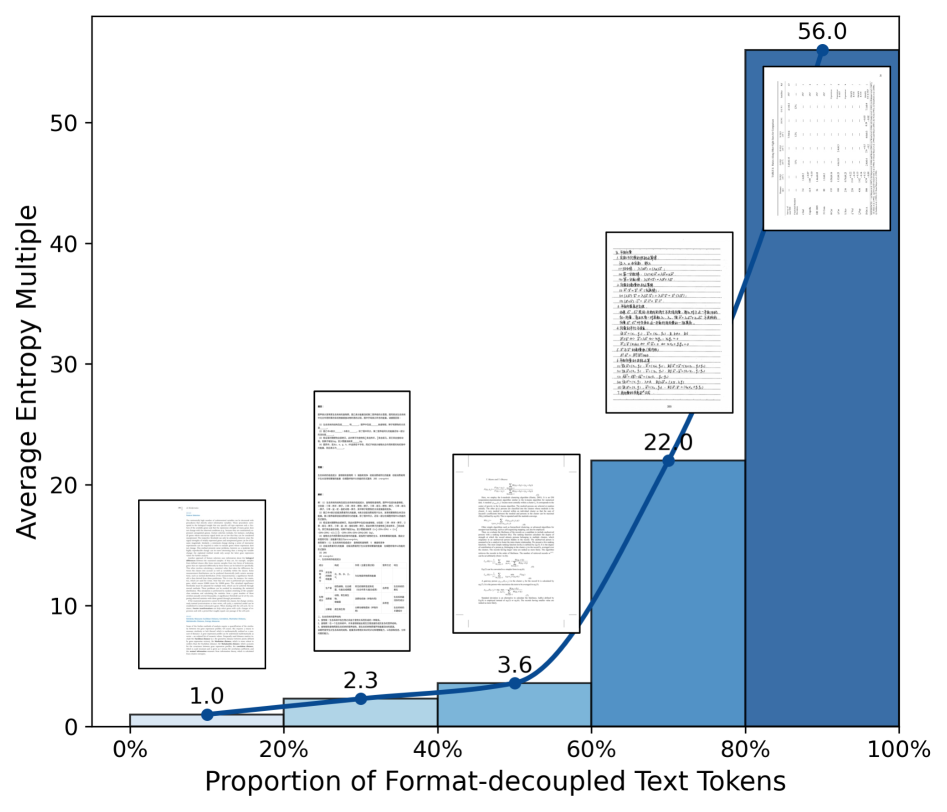
- 现有OCR模型在处理格式化文本时,存在输出熵较高的问题,表明模型难以有效推理不同阅读路径。
- 提出格式解耦强化学习(FD-RL),通过熵过滤和格式解耦奖励,针对性地优化模型对格式化文本的识别。
- FD-RL在OmniDocBench上取得了新的SOTA结果,并通过消融实验验证了数据过滤和奖励策略的有效性。
📝 摘要(中文)
本文针对OCR模型在格式化文本(如公式、表格等)中表现出的高熵问题,提出了一种格式解耦强化学习(FD-RL)方法。观察发现,即使是先进的OCR模型在处理格式敏感文档时,其输出不确定性也显著高于纯文本。FD-RL利用高熵模式进行有针对性的优化,采用基于熵的数据过滤策略来识别格式密集型实例,并采用针对不同格式类型定制的格式解耦奖励,从而实现格式级别的验证而非token级别的记忆。FD-RL在OmniDocBench上取得了90.41的平均分,为端到端模型树立了新的记录。此外,通过对数据、训练、过滤和奖励策略的全面消融研究,验证了其有效性。
🔬 方法详解
问题定义:论文旨在解决OCR模型在处理包含复杂格式(如公式、表格)的文档时,识别准确率显著下降的问题。现有方法主要侧重于通过数据增强来提升模型的感知能力,但忽略了格式化文本带来的推理挑战,导致模型在格式敏感区域表现出较高的输出不确定性(高熵)。
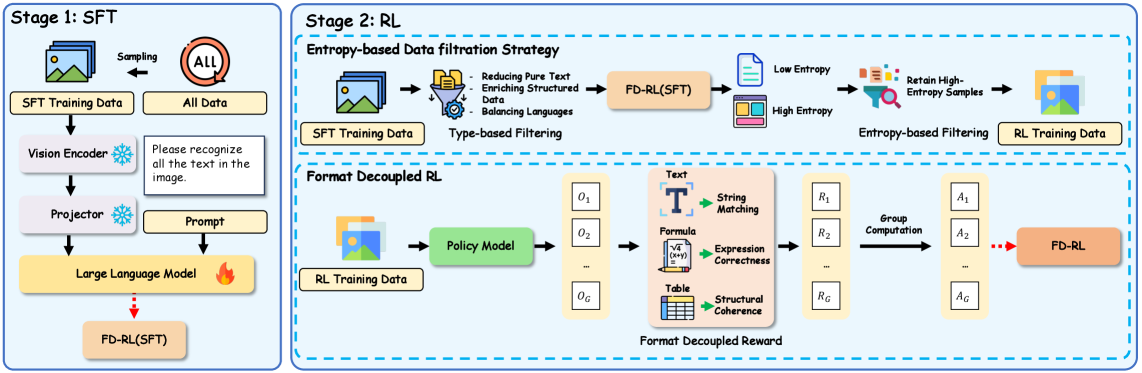
核心思路:论文的核心思路是利用强化学习,通过奖励机制引导模型学习针对不同格式的阅读策略。通过解耦不同格式的奖励,使得模型能够更好地理解和处理各种格式化文本,从而降低输出的不确定性。这种方法避免了模型简单地记忆token序列,而是鼓励模型进行格式级别的推理。
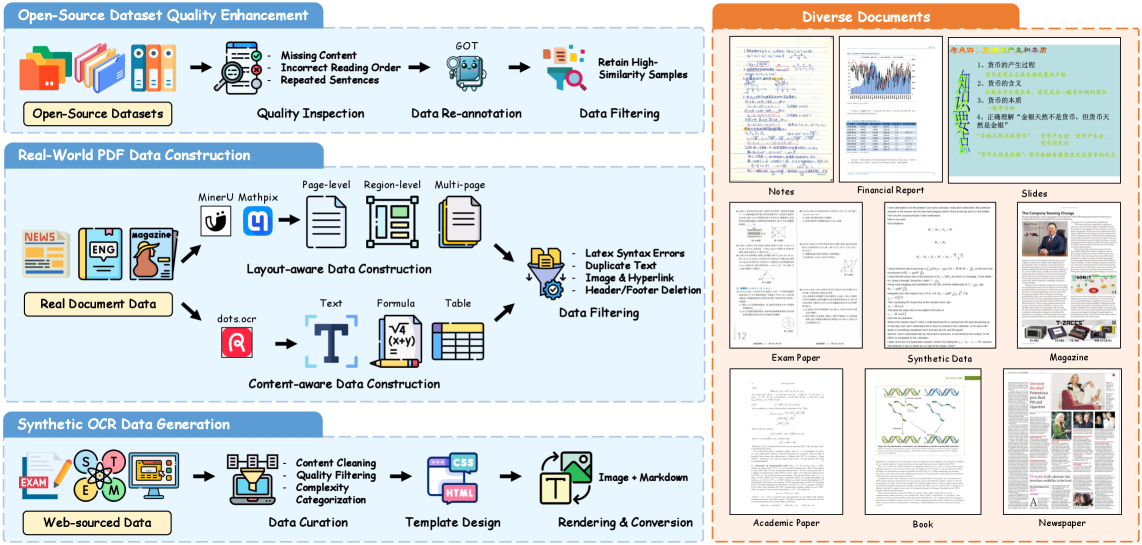
技术框架:FD-RL框架主要包含以下几个阶段:1) 数据过滤:使用基于熵的策略筛选出包含大量格式化文本的样本。2) 策略学习:使用强化学习训练OCR模型,使其能够根据不同的格式选择合适的阅读路径。3) 奖励设计:针对不同的格式类型(如公式、表格)设计不同的奖励函数,以鼓励模型正确识别这些格式。整体流程是,OCR模型作为Agent,在文档图像环境中进行探索,根据当前状态(图像内容)选择动作(阅读路径),并根据动作的结果获得奖励,从而不断优化自身的策略。
关键创新:论文的关键创新在于提出了格式解耦的强化学习方法。与传统的强化学习方法不同,FD-RL针对不同的格式类型设计了不同的奖励函数,使得模型能够更好地学习和区分不同的格式。此外,基于熵的数据过滤策略能够有效地筛选出包含大量格式化文本的样本,从而提高训练效率。
关键设计:在数据过滤阶段,使用熵作为指标来衡量样本中格式化文本的比例。在奖励函数设计方面,针对不同的格式类型,设计不同的奖励信号,例如,对于公式,如果模型能够正确识别公式中的符号和结构,则给予较高的奖励;对于表格,如果模型能够正确识别表格中的行和列,则给予较高的奖励。具体的网络结构和参数设置在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
FD-RL在OmniDocBench数据集上取得了90.41的平均分,刷新了端到端模型的SOTA记录。消融实验表明,基于熵的数据过滤策略和格式解耦的奖励函数均能显著提升模型的性能。例如,移除数据过滤策略会导致性能下降,而使用统一的奖励函数也会降低模型的识别准确率。
🎯 应用场景
该研究成果可广泛应用于文档数字化、自动化办公、学术文献处理等领域。通过提高OCR模型对格式化文本的识别准确率,可以有效提升文档处理的效率和质量,例如自动提取财务报表中的数据、识别科学论文中的公式等。未来,该技术有望进一步拓展到更复杂的文档场景,例如手写文档识别、多语言文档识别等。
📄 摘要(原文)
Reading text from images or scanned documents via OCR models has been a longstanding focus of researchers. Intuitively, text reading is perceived as a straightforward perceptual task, and existing work primarily focuses on constructing enriched data engineering to enhance SFT capabilities. In this work, we observe that even advanced OCR models exhibit significantly higher entropy in formatted text (\emph{e.g.}, formula, table, etc.) compared to plain text, often by an order of magnitude. These statistical patterns reveal that advanced OCR models struggle with high output uncertainty when dealing with format sensitive document, suggesting that reasoning over diverse reading pathways may improve OCR performance. To address this, we propose format decoupled reinforcement learning (FD-RL), which leverages high-entropy patterns for targeted optimization. Our approach employs entropy-based data filtration strategy to identify format-intensive instances, and adopt format decoupled rewards tailored to different format types, enabling format-level validation rather than token-level memorization. FD-RL achieves an average score of 90.41 on OmniDocBench, setting a new record for end-to-end models on this highly popular benchmark. More importantly, we conduct comprehensive ablation studies over data, training, filtering, and rewarding strategies, thoroughly validating their effectiveness.