VGent: Visual Grounding via Modular Design for Disentangling Reasoning and Prediction
作者: Weitai Kang, Jason Kuen, Mengwei Ren, Zijun Wei, Yan Yan, Kangning Liu
分类: cs.CV
发布日期: 2025-12-11
备注: 8 pages
💡 一句话要点
提出VGent,通过解耦推理和预测的模块化设计实现高效视觉定位。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉定位 多模态学习 大型语言模型 模块化设计 目标检测
📋 核心要点
- 现有视觉定位模型存在推理速度慢、易产生幻觉或削弱LLM推理能力等问题。
- VGent采用模块化设计,解耦推理和预测,利用冻结的MLLM进行推理,解码器选择目标框。
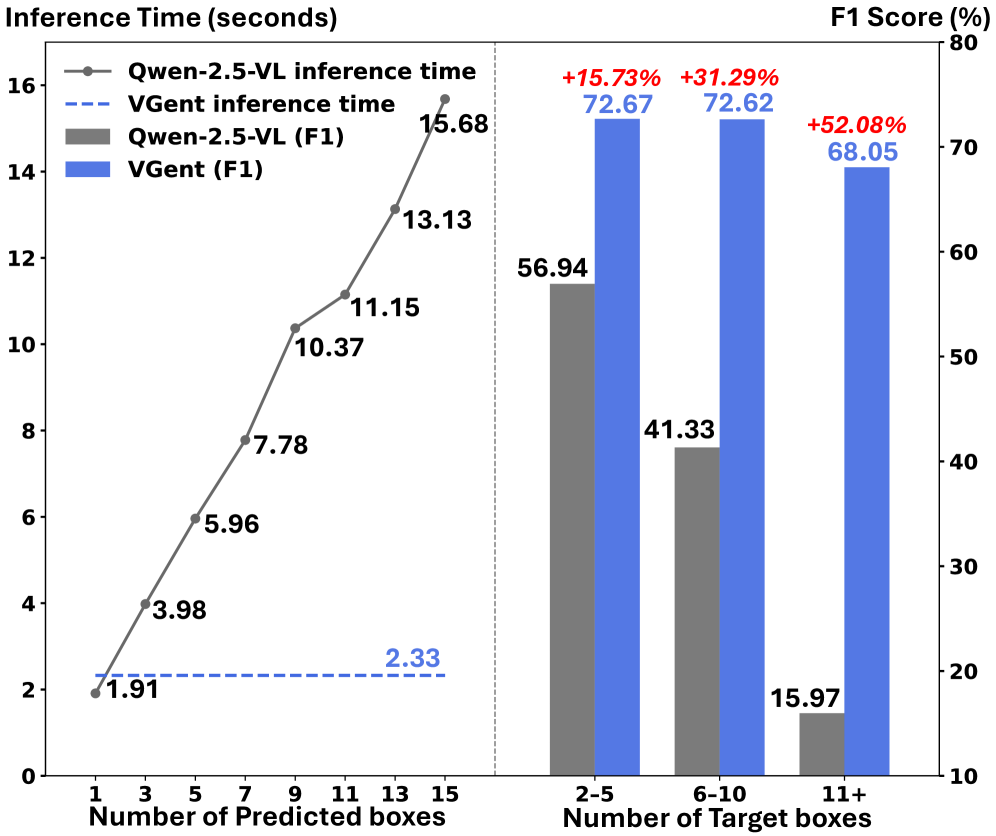
- 实验表明,VGent在多目标视觉定位任务上取得了显著的性能提升,并保持了快速推理速度。
📝 摘要(中文)
现有的视觉定位模型要么基于自回归解码的多模态大型语言模型(MLLM),速度慢且容易产生幻觉;要么通过重新对齐LLM与视觉特征来学习新的特殊或对象tokens进行定位,这可能会削弱LLM的预训练推理能力。为了解决这些问题,我们提出了VGent,一种模块化的编码器-解码器架构,它显式地解耦了高层次的推理和低层次的边界框预测。具体来说,一个冻结的MLLM作为编码器,提供未经修改的强大推理能力,而解码器将检测器提出的高质量框作为查询,并通过交叉注意力机制选择目标框。这种设计充分利用了对象检测和MLLM的进步,避免了自回归解码的缺陷,并实现了快速推理。此外,它支持编码器和解码器的模块化升级,从而使整个系统受益:我们引入了(i)QuadThinker,一种基于强化学习的训练范式,用于增强编码器的多目标推理能力;(ii)mask-aware标签,用于解决检测-分割的歧义性;以及(iii)全局目标识别,以提高所有目标的识别率,从而有利于增强提案的选择。在多目标视觉定位基准测试中,实验表明VGent实现了新的state-of-the-art,F1指标比现有方法提高了+20.6%,并且在视觉参考挑战下,gIoU提高了+8.2%,cIoU提高了+5.8%,同时保持了恒定的快速推理延迟。
🔬 方法详解
问题定义:现有视觉定位方法主要存在两个痛点:一是基于自回归解码的MLLM速度慢且易产生幻觉;二是将LLM与视觉特征对齐,学习新的tokens,可能损害LLM的预训练推理能力。因此,需要一种既能充分利用MLLM的推理能力,又能实现快速准确视觉定位的方法。
核心思路:VGent的核心思路是将视觉定位任务分解为高层次的推理和低层次的边界框预测两个模块,并分别由MLLM和解码器负责。通过解耦推理和预测,可以避免自回归解码的缺陷,并充分利用对象检测和MLLM的优势。
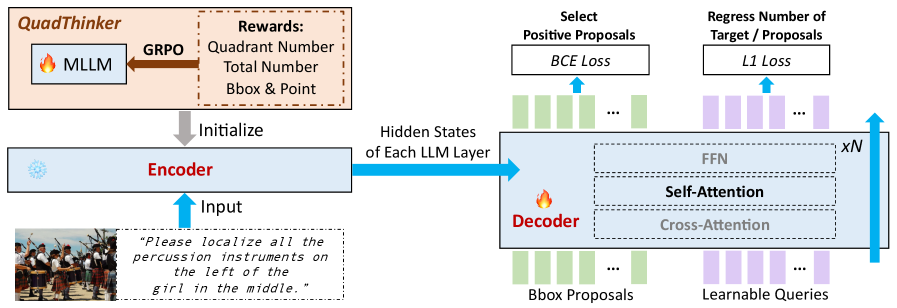
技术框架:VGent的整体架构是一个模块化的编码器-解码器结构。编码器是一个冻结的MLLM,负责对输入文本和图像进行推理,提取高层次的语义信息。解码器以检测器提出的候选框作为查询,通过交叉注意力机制在编码器的隐藏状态中选择目标框。整个流程包括:1. 对象检测器生成候选框;2. MLLM编码器进行推理;3. 解码器选择目标框。
关键创新:VGent的关键创新在于其模块化设计,显式地解耦了推理和预测。此外,还提出了以下创新点:(1) QuadThinker:一种基于强化学习的训练范式,用于增强编码器的多目标推理能力。(2) mask-aware标签:用于解决检测-分割的歧义性。(3) 全局目标识别:提高所有目标的识别率,从而有利于增强提案的选择。与现有方法相比,VGent避免了自回归解码和对LLM的微调,从而更好地利用了MLLM的预训练知识。
关键设计:(1) 冻结MLLM的参数,保证其推理能力不受影响。(2) 使用交叉注意力机制,使解码器能够根据编码器的隐藏状态选择目标框。(3) QuadThinker使用强化学习训练编码器,使其能够更好地处理多目标推理任务。(4) mask-aware标签通过考虑像素级别的分割信息,解决了检测和分割之间的歧义性。(5) 全局目标识别通过学习所有目标的表示,提高了目标识别的准确率。
🖼️ 关键图片

📊 实验亮点
VGent在多目标视觉定位基准测试中取得了显著的性能提升。与现有方法相比,VGent的F1指标提高了+20.6%,gIoU提高了+8.2%,cIoU提高了+5.8%,同时保持了恒定的快速推理延迟。这些结果表明,VGent在视觉定位任务上具有显著的优势。
🎯 应用场景
VGent具有广泛的应用前景,例如在智能客服、自动驾驶、机器人导航等领域。它可以用于理解用户指令,并在图像中定位目标对象,从而实现人机交互和智能决策。此外,VGent还可以应用于图像搜索、视频分析等领域,提高搜索和分析的准确性和效率。
📄 摘要(原文)
Current visual grounding models are either based on a Multimodal Large Language Model (MLLM) that performs auto-regressive decoding, which is slow and risks hallucinations, or on re-aligning an LLM with vision features to learn new special or object tokens for grounding, which may undermine the LLM's pretrained reasoning ability. In contrast, we propose VGent, a modular encoder-decoder architecture that explicitly disentangles high-level reasoning and low-level bounding box prediction. Specifically, a frozen MLLM serves as the encoder to provide untouched powerful reasoning capabilities, while a decoder takes high-quality boxes proposed by detectors as queries and selects target box(es) via cross-attending on encoder's hidden states. This design fully leverages advances in both object detection and MLLM, avoids the pitfalls of auto-regressive decoding, and enables fast inference. Moreover, it supports modular upgrades of both the encoder and decoder to benefit the whole system: we introduce (i) QuadThinker, an RL-based training paradigm for enhancing multi-target reasoning ability of the encoder; (ii) mask-aware label for resolving detection-segmentation ambiguity; and (iii) global target recognition to improve the recognition of all the targets which benefits the selection among augmented proposals. Experiments on multi-target visual grounding benchmarks show that VGent achieves a new state-of-the-art with +20.6% F1 improvement over prior methods, and further boosts gIoU by +8.2% and cIoU by +5.8% under visual reference challenges, while maintaining constant, fast inference latency.