Weakly Supervised Tuberculosis Localization in Chest X-rays through Knowledge Distillation
作者: Marshal Ashif Shawkat, Moidul Hasan, Taufiq Hasan
分类: cs.CV
发布日期: 2025-12-11
备注: 18 pages, 9 figures, 4 tables
💡 一句话要点
利用知识蒸馏进行胸部X光片中弱监督肺结核定位
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 肺结核定位 胸部X光片 知识蒸馏 弱监督学习 ResNet50
📋 核心要点
- 现有肺结核检测模型依赖于虚假相关性,泛化能力差,且依赖大量精确标注数据,标注成本高昂。
- 提出一种基于知识蒸馏的弱监督方法,利用师生框架,无需边界框标注即可定位肺结核相关异常。
- 实验表明,学生模型在TBX11k数据集上取得了0.2428 mIOU,且性能优于教师模型,提升了鲁棒性。
📝 摘要(中文)
肺结核(TB)仍然是全球主要的死亡原因之一,尤其是在资源有限的国家。胸部X光片(CXR)是一种易于获取且经济高效的诊断工具,但需要专家解读,而这往往是无法获得的。尽管机器学习模型在肺结核分类方面表现出高性能,但它们通常依赖于虚假的相关性,并且无法泛化。此外,构建包含高质量医学图像标注的大型数据集需要大量的资源和领域专家的投入,并且通常涉及多个标注者达成一致,这导致巨大的财务和后勤费用。本研究重新利用知识蒸馏技术来训练CNN模型,减少虚假相关性,并在不需要边界框标注的情况下定位与肺结核相关的异常。通过利用具有ResNet50架构的师生框架,该方法在TBX11k数据集上训练后实现了令人印象深刻的0.2428 mIOU分数。实验结果进一步表明,学生模型始终优于教师模型,突出了改进的鲁棒性和在不同环境中更广泛的临床部署的潜力。
🔬 方法详解
问题定义:论文旨在解决在胸部X光片中进行肺结核定位的问题,但面临着缺乏高质量标注数据和现有模型泛化能力差的挑战。现有方法通常需要大量的边界框标注,这需要耗费大量时间和专家资源。此外,现有模型容易受到虚假相关性的影响,导致在不同数据集上的性能下降。
核心思路:论文的核心思路是利用知识蒸馏技术,通过一个预训练的教师模型指导学生模型学习,从而在不需要边界框标注的情况下实现肺结核的定位。这种方法可以减少对大量标注数据的依赖,并提高模型的泛化能力。
技术框架:整体框架是一个师生学习框架。教师模型是一个预训练的ResNet50模型,它在包含边界框标注的数据集上进行训练。学生模型也是一个ResNet50模型,但它在没有边界框标注的数据集上进行训练。学生模型通过最小化其预测与教师模型预测之间的差异来学习。该框架包含两个主要阶段:教师模型训练和学生模型训练。
关键创新:该论文的关键创新在于将知识蒸馏技术应用于弱监督肺结核定位。与传统的监督学习方法相比,该方法不需要边界框标注,从而大大降低了标注成本。此外,通过知识蒸馏,学生模型可以学习到教师模型的泛化能力,从而提高其在不同数据集上的性能。
关键设计:论文使用了ResNet50作为教师和学生模型的骨干网络。损失函数包括分类损失和蒸馏损失。分类损失用于确保学生模型能够正确分类胸部X光片。蒸馏损失用于最小化学生模型和教师模型之间的预测差异。具体来说,使用了KL散度作为蒸馏损失。此外,还使用了数据增强技术来提高模型的鲁棒性。参数设置方面,采用了Adam优化器,学习率设置为0.001,batch size设置为32。
🖼️ 关键图片
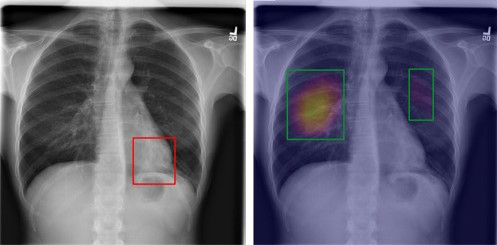
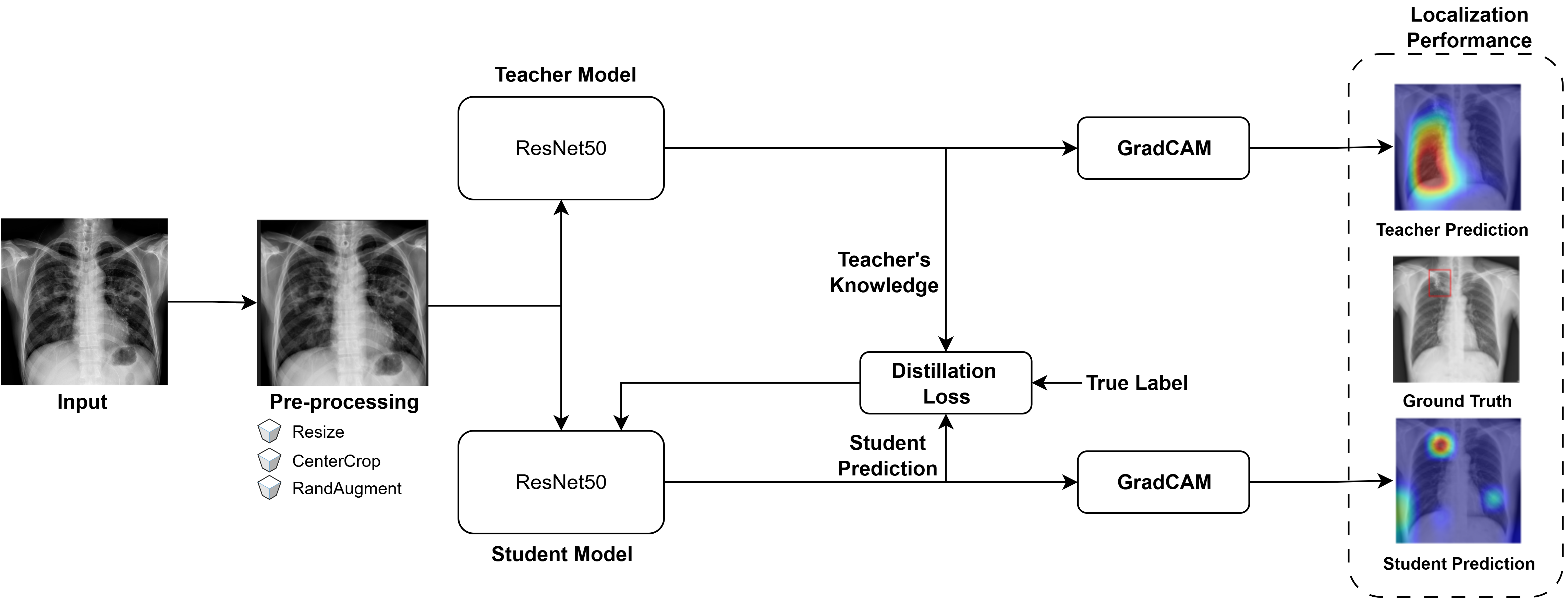
📊 实验亮点
实验结果表明,基于知识蒸馏的学生模型在TBX11k数据集上取得了0.2428的mIOU分数,并且性能优于教师模型。这表明该方法能够有效地利用知识蒸馏技术,在弱监督条件下实现肺结核的定位,并提高模型的鲁棒性。
🎯 应用场景
该研究成果可应用于肺结核的辅助诊断,尤其是在资源匮乏的地区,可以帮助医生快速准确地识别肺结核病灶,提高诊断效率。未来,该技术可扩展到其他医学影像分析任务,例如肺炎、肺癌等疾病的诊断,具有广阔的应用前景。
📄 摘要(原文)
Tuberculosis (TB) remains one of the leading causes of mortality worldwide, particularly in resource-limited countries. Chest X-ray (CXR) imaging serves as an accessible and cost-effective diagnostic tool but requires expert interpretation, which is often unavailable. Although machine learning models have shown high performance in TB classification, they often depend on spurious correlations and fail to generalize. Besides, building large datasets featuring high-quality annotations for medical images demands substantial resources and input from domain specialists, and typically involves several annotators reaching agreement, which results in enormous financial and logistical expenses. This study repurposes knowledge distillation technique to train CNN models reducing spurious correlations and localize TB-related abnormalities without requiring bounding-box annotations. By leveraging a teacher-student framework with ResNet50 architecture, the proposed method trained on TBX11k dataset achieve impressive 0.2428 mIOU score. Experimental results further reveal that the student model consistently outperforms the teacher, underscoring improved robustness and potential for broader clinical deployment in diverse settings.