E-RayZer: Self-supervised 3D Reconstruction as Spatial Visual Pre-training
作者: Qitao Zhao, Hao Tan, Qianqian Wang, Sai Bi, Kai Zhang, Kalyan Sunkavalli, Shubham Tulsiani, Hanwen Jiang
分类: cs.CV
发布日期: 2025-12-11
备注: Project website: https://qitaozhao.github.io/E-RayZer
💡 一句话要点
E-RayZer:提出自监督3D重建框架,作为空间视觉预训练模型。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自监督学习 3D重建 视觉预训练 几何约束 多视图图像
📋 核心要点
- 现有自监督方法在多视图图像中学习3D感知表征方面探索不足,容易陷入捷径。
- E-RayZer通过显式几何进行自监督3D重建,直接在3D空间操作,避免了捷径。
- 引入细粒度学习课程,无监督地组织训练样本,协调异构数据,提升收敛性和可扩展性。
📝 摘要(中文)
本文提出E-RayZer,一个自监督的大型3D视觉模型,直接从无标签图像中学习具有3D感知能力的表征。与以往通过潜在空间视角合成间接推断3D的自监督方法(如RayZer)不同,E-RayZer直接在3D空间中操作,通过显式几何进行自监督3D重建。这种方法消除了捷径解决方案,并产生了具有几何基础的表征。为了确保收敛性和可扩展性,我们引入了一种新颖的细粒度学习课程,以完全无监督的方式组织从易到难的样本训练,并协调异构数据源。实验表明,E-RayZer在姿态估计方面显著优于RayZer,在重建方面达到甚至超过了完全监督的模型(如VGGT)。此外,其学习到的表征在迁移到3D下游任务时,优于领先的视觉预训练模型(如DINOv3、CroCo v2、VideoMAE V2和RayZer),从而将E-RayZer确立为3D感知视觉预训练的新范例。
🔬 方法详解
问题定义:现有自监督方法,如RayZer,通过潜在空间视角合成间接推断3D,容易学习到与几何无关的捷径特征,导致泛化能力不足。缺乏直接在3D空间进行操作的自监督预训练方法。
核心思路:E-RayZer的核心思路是直接在3D空间中进行自监督重建,利用显式几何信息作为约束,避免模型学习到捷径特征。通过这种方式,模型能够学习到更具有几何意义和泛化能力的3D表征。
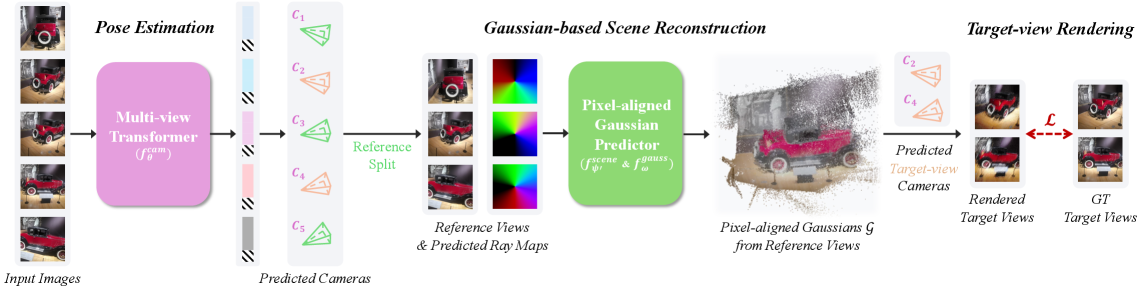
技术框架:E-RayZer的整体框架包含以下几个主要模块:1) 多视图图像输入;2) 3D场景重建模块,该模块直接在3D空间中进行操作,利用显式几何信息进行自监督重建;3) 表征学习模块,负责从重建的3D场景中学习3D-aware的表征;4) 细粒度学习课程模块,用于组织训练样本,协调异构数据源。
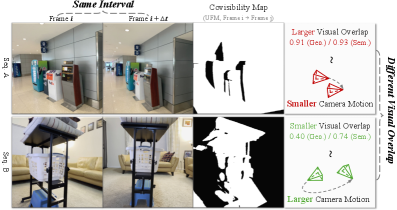
关键创新:E-RayZer的关键创新在于直接在3D空间中进行自监督重建,并引入了细粒度学习课程。与RayZer等方法相比,E-RayZer避免了通过潜在空间进行间接推断,而是直接利用显式几何信息进行约束,从而学习到更具有几何意义的3D表征。细粒度学习课程则保证了模型在训练过程中的收敛性和可扩展性。
关键设计:E-RayZer的关键设计包括:1) 3D场景重建模块的具体实现方式,例如使用体素网格或神经辐射场等;2) 细粒度学习课程的具体策略,例如如何根据样本的难度进行排序,以及如何协调不同数据源之间的差异;3) 损失函数的设计,例如使用重建误差、几何一致性损失等来约束模型的学习。
🖼️ 关键图片
📊 实验亮点
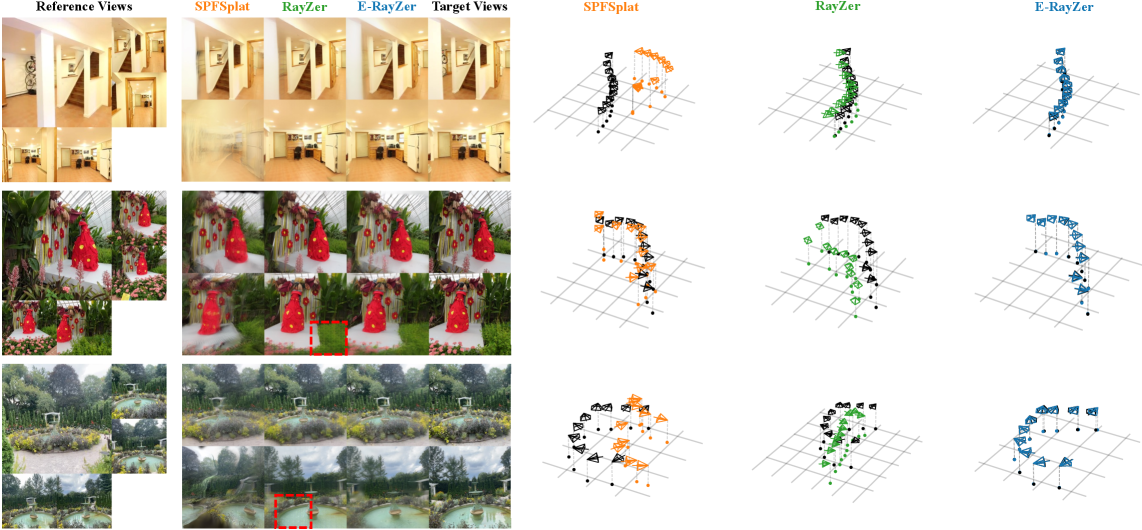
E-RayZer在姿态估计方面显著优于RayZer,在重建方面达到甚至超过了完全监督的模型(如VGGT)。在迁移到3D下游任务时,E-RayZer学习到的表征优于领先的视觉预训练模型(如DINOv3、CroCo v2、VideoMAE V2和RayZer)。这些结果表明E-RayZer在3D感知表征学习方面具有显著优势。
🎯 应用场景
E-RayZer的潜在应用领域包括机器人导航、自动驾驶、三维场景理解、虚拟现实/增强现实等。通过学习具有几何意义的3D表征,E-RayZer可以提升这些应用在复杂环境中的感知和决策能力。未来,E-RayZer有望成为3D视觉领域的基础模型,推动相关技术的发展。
📄 摘要(原文)
Self-supervised pre-training has revolutionized foundation models for languages, individual 2D images and videos, but remains largely unexplored for learning 3D-aware representations from multi-view images. In this paper, we present E-RayZer, a self-supervised large 3D Vision model that learns truly 3D-aware representations directly from unlabeled images. Unlike prior self-supervised methods such as RayZer that infer 3D indirectly through latent-space view synthesis, E-RayZer operates directly in 3D space, performing self-supervised 3D reconstruction with Explicit geometry. This formulation eliminates shortcut solutions and yields representations that are geometrically grounded. To ensure convergence and scalability, we introduce a novel fine-grained learning curriculum that organizes training from easy to hard samples and harmonizes heterogeneous data sources in an entirely unsupervised manner. Experiments demonstrate that E-RayZer significantly outperforms RayZer on pose estimation, matches or sometimes surpasses fully supervised reconstruction models such as VGGT. Furthermore, its learned representations outperform leading visual pre-training models (e.g., DINOv3, CroCo v2, VideoMAE V2, and RayZer) when transferring to 3D downstream tasks, establishing E-RayZer as a new paradigm for 3D-aware visual pre-training.