AlcheMinT: Fine-grained Temporal Control for Multi-Reference Consistent Video Generation
作者: Sharath Girish, Viacheslav Ivanov, Tsai-Shien Chen, Hao Chen, Aliaksandr Siarohin, Sergey Tulyakov
分类: cs.CV, cs.AI
发布日期: 2025-12-11
备注: Project page: https://snap-research.github.io/Video-AlcheMinT/snap-research.github.io/Video-AlcheMinT
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
AlcheMinT:用于多参考一致视频生成的细粒度时间控制方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频生成 时间控制 主题驱动 位置编码 多主体 扩散模型 视频个性化
📋 核心要点
- 现有主题驱动的视频生成方法缺乏对主题出现和消失的细粒度时间控制,限制了其应用。
- AlcheMinT通过引入显式时间戳条件和新颖的位置编码机制,实现对视频生成中主题时间控制。
- 实验表明,AlcheMinT在保持视觉质量的同时,首次实现了对视频中多主题生成的精确时间控制。
📝 摘要(中文)
本文提出AlcheMinT,一个统一的框架,为主题驱动的视频生成引入显式的时间戳条件。该方法引入了一种新颖的位置编码机制,能够解锁时间间隔的编码,在本例中,时间间隔与主题身份相关联,同时无缝地与预训练的视频生成模型位置嵌入集成。此外,我们还加入了主题描述性文本token,以加强视觉身份和视频字幕之间的绑定,从而减轻生成过程中的歧义。通过token级的连接,AlcheMinT避免了任何额外的交叉注意力模块,并且参数开销可以忽略不计。我们建立了一个基准,用于评估多个主题身份保持、视频保真度和时间一致性。实验结果表明,AlcheMinT实现了与最先进的视频个性化方法相匹配的视觉质量,同时首次实现了对视频中多主题生成的精确时间控制。
🔬 方法详解
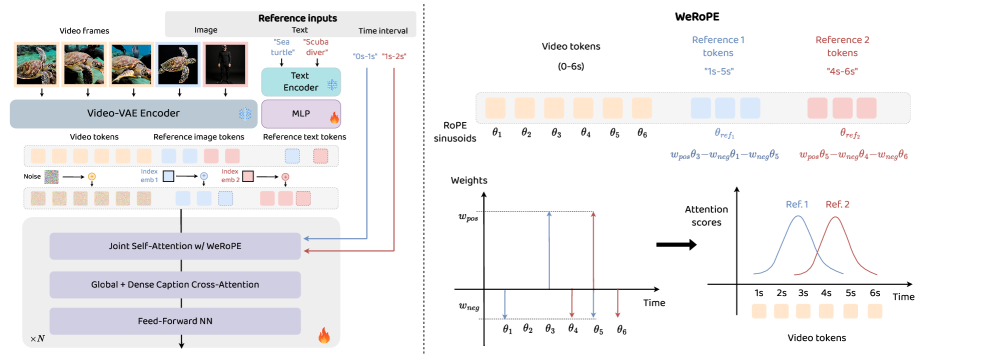
问题定义:现有主题驱动的视频生成方法无法精确控制视频中不同主体的出现和消失时间,这限制了其在组合视频合成、故事板制作和可控动画等领域的应用。现有方法难以在时间维度上对多个主体进行精细化管理,导致主体身份混淆或时间轴上的不一致性。
核心思路:AlcheMinT的核心思路是通过引入显式的时间戳信息,并将其与主体身份绑定,从而实现对视频生成过程的细粒度时间控制。该方法利用一种新颖的位置编码机制来表示时间间隔,并结合主题描述性文本token来增强视觉身份和视频字幕之间的关联。
技术框架:AlcheMinT的整体框架包括以下几个主要步骤:首先,对输入的主体图像和描述性文本进行编码。然后,利用新颖的位置编码机制对时间戳信息进行编码,并将其与主体身份信息关联。接下来,将编码后的信息输入到预训练的视频生成模型中,生成视频。最后,通过损失函数对生成的视频进行优化,以提高其视觉质量和时间一致性。
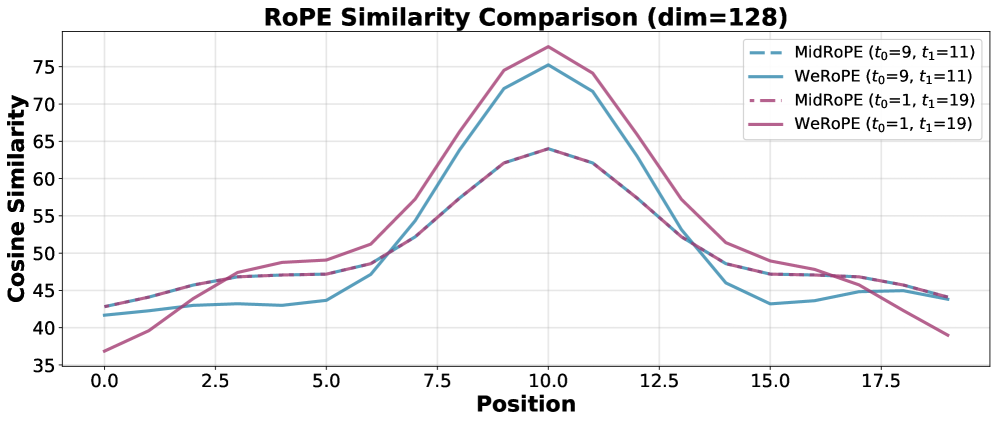
关键创新:AlcheMinT的关键创新在于引入了显式的时间戳条件,并设计了一种新颖的位置编码机制来表示时间间隔。这种方法能够有效地将时间信息融入到视频生成过程中,从而实现对主体出现和消失时间的精确控制。此外,通过token-wise concatenation,避免了额外的交叉注意力模块,降低了参数开销。
关键设计:AlcheMinT的关键设计包括:1) 新颖的位置编码机制,用于编码时间间隔;2) 主题描述性文本token,用于加强视觉身份和视频字幕之间的绑定;3) token-wise concatenation,用于避免额外的交叉注意力模块。具体参数设置和损失函数细节在论文中未明确给出,属于未知信息。
🖼️ 关键图片

📊 实验亮点
AlcheMinT在多主体身份保持、视频保真度和时间一致性方面取得了显著的成果。实验结果表明,AlcheMinT在视觉质量上与最先进的视频个性化方法相匹配,并且首次实现了对视频中多主体生成的精确时间控制。具体的性能数据和提升幅度在论文中未明确给出,属于未知信息。
🎯 应用场景
AlcheMinT在多个领域具有广泛的应用前景,包括组合视频合成、故事板制作、可控动画、视频编辑和个性化内容创作。该方法能够帮助用户更精确地控制视频中不同主体的出现和消失时间,从而实现更具创意和表现力的视频内容。
📄 摘要(原文)
Recent advances in subject-driven video generation with large diffusion models have enabled personalized content synthesis conditioned on user-provided subjects. However, existing methods lack fine-grained temporal control over subject appearance and disappearance, which are essential for applications such as compositional video synthesis, storyboarding, and controllable animation. We propose AlcheMinT, a unified framework that introduces explicit timestamps conditioning for subject-driven video generation. Our approach introduces a novel positional encoding mechanism that unlocks the encoding of temporal intervals, associated in our case with subject identities, while seamlessly integrating with the pretrained video generation model positional embeddings. Additionally, we incorporate subject-descriptive text tokens to strengthen binding between visual identity and video captions, mitigating ambiguity during generation. Through token-wise concatenation, AlcheMinT avoids any additional cross-attention modules and incurs negligible parameter overhead. We establish a benchmark evaluating multiple subject identity preservation, video fidelity, and temporal adherence. Experimental results demonstrate that AlcheMinT achieves visual quality matching state-of-the-art video personalization methods, while, for the first time, enabling precise temporal control over multi-subject generation within videos. Project page is at https://snap-research.github.io/Video-AlcheMinT