VL-JEPA: Joint Embedding Predictive Architecture for Vision-language
作者: Delong Chen, Mustafa Shukor, Theo Moutakanni, Willy Chung, Jade Yu, Tejaswi Kasarla, Yejin Bang, Allen Bolourchi, Yann LeCun, Pascale Fung
分类: cs.CV
发布日期: 2025-12-11 (更新: 2026-02-02)
💡 一句话要点
VL-JEPA:面向视觉语言的联合嵌入预测架构,参数更少性能更强。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视觉语言模型 联合嵌入 预测架构 视频理解 视觉问答 跨模态检索 选择性解码
📋 核心要点
- 传统视觉语言模型依赖自回归生成token,计算成本高昂,且易受表面语言变异性的影响。
- VL-JEPA通过预测文本的连续嵌入而非token,在抽象语义空间学习,从而关注任务相关信息。
- 实验表明,VL-JEPA在参数量减少50%的情况下,在视频理解和视觉问答任务上表现出优异性能。
📝 摘要(中文)
本文提出了一种基于联合嵌入预测架构(JEPA)的视觉语言模型VL-JEPA。与传统视觉语言模型(VLM)自回归生成token不同,VL-JEPA预测目标文本的连续嵌入。通过在抽象表示空间中学习,该模型专注于任务相关的语义,同时忽略表面的语言变异性。在与使用相同视觉编码器和训练数据的标准token空间VLM训练进行严格控制的比较中,VL-JEPA在可训练参数减少50%的情况下实现了更强的性能。在推理时,仅在需要时才调用轻量级文本解码器,将VL-JEPA预测的嵌入转换为文本。我们表明,VL-JEPA原生支持选择性解码,与非自适应均匀解码相比,可将解码操作次数减少2.85倍,同时保持相似的性能。除了生成之外,VL-JEPA的嵌入空间自然支持开放词汇分类、文本到视频检索和判别式VQA,而无需任何架构修改。在八个视频分类和八个视频检索数据集上,VL-JEPA的平均性能超过了CLIP、SigLIP2和Perception Encoder。同时,该模型在四个VQA数据集(GQA、TallyQA、POPE和POPEv2)上实现了与经典VLM(InstructBLIP、QwenVL)相当的性能,尽管只有16亿参数。
🔬 方法详解
问题定义:现有视觉语言模型(VLM)通常采用自回归的方式生成文本token,这种方法计算量大,并且模型容易受到文本表面信息的影响,而忽略了深层语义信息。因此,如何设计一种更高效、更关注语义信息的视觉语言模型是一个重要的研究问题。
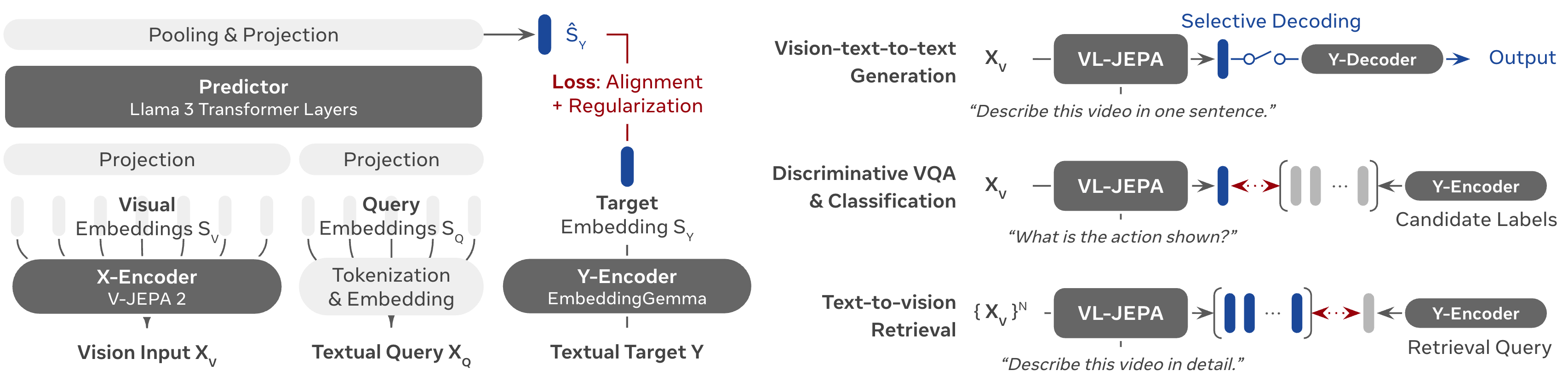
核心思路:VL-JEPA的核心思路是利用联合嵌入预测架构(JEPA),将视觉和语言信息映射到同一个连续的嵌入空间中。模型不再直接预测文本token,而是预测文本的嵌入表示。这种方式可以使模型更加关注语义信息,减少对表面语言变异性的依赖。
技术框架:VL-JEPA的整体架构包括视觉编码器、文本编码器和一个预测模块。视觉编码器负责将图像或视频转换为视觉特征表示,文本编码器负责将文本转换为文本特征表示。预测模块接收视觉特征表示,并预测对应的文本嵌入。在训练过程中,模型通过最小化预测的文本嵌入与真实文本嵌入之间的差异来学习。在推理阶段,可以使用一个轻量级的文本解码器将预测的文本嵌入转换为文本。
关键创新:VL-JEPA最重要的创新在于它采用了联合嵌入预测架构,避免了传统的token生成方式。这种架构使得模型能够更加关注语义信息,并且减少了计算量。此外,VL-JEPA还支持选择性解码,可以根据需要动态地调整解码的计算量。
关键设计:VL-JEPA的关键设计包括:1) 使用Transformer作为视觉和文本编码器;2) 使用对比学习损失函数来训练模型,使得相似的视觉和文本嵌入更加接近;3) 设计了一个轻量级的文本解码器,用于将预测的文本嵌入转换为文本;4) 实现了选择性解码,可以根据需要动态地调整解码的计算量。
🖼️ 关键图片


📊 实验亮点
VL-JEPA在多个视频分类和视频检索数据集上超越了CLIP、SigLIP2和Perception Encoder。在VQA数据集上,VL-JEPA在参数量仅为16亿的情况下,取得了与InstructBLIP、QwenVL等经典VLM模型相当的性能。选择性解码技术使得VL-JEPA在保持性能的同时,解码操作次数减少了2.85倍。
🎯 应用场景
VL-JEPA具有广泛的应用前景,包括视频理解、视觉问答、图像描述、跨模态检索等。该模型可以应用于智能客服、自动驾驶、智能监控等领域,为人们提供更加智能化的服务。此外,VL-JEPA的轻量化设计使其更易于部署在移动设备和边缘设备上,具有很高的实际应用价值。
📄 摘要(原文)
We introduce VL-JEPA, a vision-language model built on a Joint Embedding Predictive Architecture (JEPA). Instead of autoregressively generating tokens as in classical VLMs, VL-JEPA predicts continuous embeddings of the target texts. By learning in an abstract representation space, the model focuses on task-relevant semantics while abstracting away surface-level linguistic variability. In a strictly controlled comparison against standard token-space VLM training with the same vision encoder and training data, VL-JEPA achieves stronger performance while having 50% fewer trainable parameters. At inference time, a lightweight text decoder is invoked only when needed to translate VL-JEPA predicted embeddings into text. We show that VL-JEPA natively supports selective decoding that reduces the number of decoding operations by 2.85x while maintaining similar performance compared to non-adaptive uniform decoding. Beyond generation, the VL-JEPA's embedding space naturally supports open-vocabulary classification, text-to-video retrieval, and discriminative VQA without any architecture modification. On eight video classification and eight video retrieval datasets, the average performance VL-JEPA surpasses that of CLIP, SigLIP2, and Perception Encoder. At the same time, the model achieves comparable performance as classical VLMs (InstructBLIP, QwenVL) on four VQA datasets: GQA, TallyQA, POPE and POPEv2, despite only having 1.6B parameters.