Any4D: Unified Feed-Forward Metric 4D Reconstruction
作者: Jay Karhade, Nikhil Keetha, Yuchen Zhang, Tanisha Gupta, Akash Sharma, Sebastian Scherer, Deva Ramanan
分类: cs.CV, cs.AI, cs.LG, cs.RO
发布日期: 2025-12-11
备注: Project Website: https://any-4d.github.io/
💡 一句话要点
Any4D:统一前馈度量4D重建框架,支持多模态输入
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 4D重建 多视角学习 Transformer网络 多模态融合 场景流估计
📋 核心要点
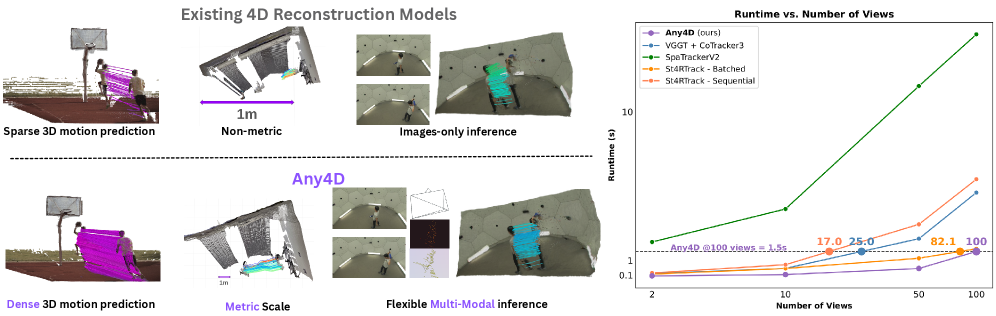
- 现有4D重建方法通常局限于双视角场景流或稀疏点跟踪,且难以融合多模态数据。
- Any4D采用模块化表示,区分自中心和场景中心因素,实现灵活的多模态数据融合和4D场景重建。
- 实验表明,Any4D在精度上提升2-3倍,计算效率提升15倍,为下游应用提供了可能。
📝 摘要(中文)
本文提出Any4D,一个可扩展的多视角Transformer,用于度量尺度下的稠密前馈4D重建。Any4D直接生成N帧的逐像素运动和几何预测,这与以往主要关注双视角稠密场景流或稀疏3D点跟踪的工作不同。此外,与其他最近的单目RGB视频4D重建方法不同,Any4D可以处理额外的模态和传感器数据,例如RGB-D帧、基于IMU的自运动和雷达多普勒测量(如果可用)。该框架的关键创新在于4D场景的模块化表示;具体来说,每个视角的4D预测使用以局部相机坐标表示的各种自中心因素(深度图和相机内参)和以全局世界坐标表示的场景中心因素(相机外参和场景流)进行编码。在各种设置中,我们在精度(误差降低2-3倍)和计算效率(速度提高15倍)方面都取得了优异的性能,为多个下游应用开辟了道路。
🔬 方法详解
问题定义:现有4D重建方法通常存在以下痛点:一是大多集中于双视角稠密场景流或稀疏3D点跟踪,难以进行多帧的稠密4D重建;二是难以有效融合来自不同模态和传感器的信息,例如RGB-D、IMU和雷达数据;三是计算效率较低,难以满足实时应用的需求。
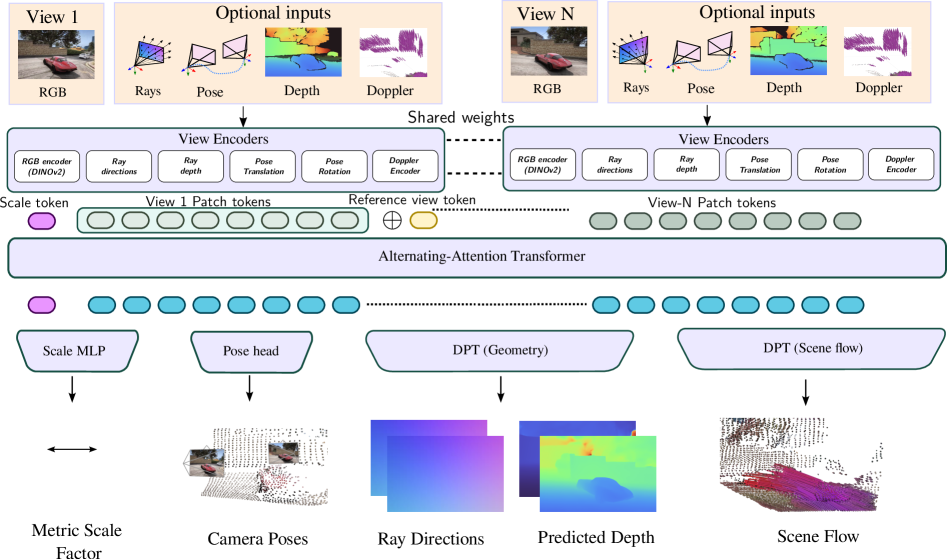
核心思路:Any4D的核心思路是采用一种模块化的4D场景表示方法,将场景信息分解为自中心因素(如深度图和相机内参,在局部相机坐标系下表示)和场景中心因素(如相机外参和场景流,在全局世界坐标系下表示)。这种解耦使得模型能够灵活地处理不同模态的输入,并进行有效的4D重建。
技术框架:Any4D的整体架构是一个多视角Transformer网络,它接收N帧图像以及可选的RGB-D数据、IMU数据和雷达数据作为输入。网络首先对每个视角的图像进行特征提取,然后利用Transformer进行跨视角的特征融合和信息传递。最后,网络预测每个像素的运动和几何信息,包括深度图、相机外参和场景流等。这些预测结果被用于构建稠密的4D场景表示。
关键创新:Any4D的关键创新在于其模块化的4D场景表示方法,它将场景信息分解为自中心和场景中心因素,并分别在不同的坐标系下表示。这种表示方法使得模型能够灵活地处理不同模态的输入,并进行有效的4D重建。此外,Any4D还采用了多视角Transformer网络,能够有效地进行跨视角的特征融合和信息传递。
关键设计:Any4D的关键设计包括:1) 使用Transformer进行跨视角特征融合;2) 采用自中心和场景中心因素的模块化表示;3) 设计了专门的损失函数来约束深度图、相机外参和场景流的预测;4) 网络结构经过优化,以提高计算效率。
🖼️ 关键图片

📊 实验亮点
Any4D在多个数据集上取得了显著的性能提升。与现有方法相比,Any4D在精度上降低了2-3倍的误差,计算效率提高了15倍。这些结果表明,Any4D是一种高效且准确的4D重建方法,具有很强的实用价值。
🎯 应用场景
Any4D具有广泛的应用前景,包括自动驾驶、机器人导航、增强现实和虚拟现实等领域。例如,在自动驾驶中,Any4D可以用于构建车辆周围环境的4D模型,从而提高车辆的感知能力和决策能力。在机器人导航中,Any4D可以用于构建机器人的运动地图,从而实现自主导航。在AR/VR中,Any4D可以用于构建逼真的虚拟场景,从而提高用户体验。
📄 摘要(原文)
We present Any4D, a scalable multi-view transformer for metric-scale, dense feed-forward 4D reconstruction. Any4D directly generates per-pixel motion and geometry predictions for N frames, in contrast to prior work that typically focuses on either 2-view dense scene flow or sparse 3D point tracking. Moreover, unlike other recent methods for 4D reconstruction from monocular RGB videos, Any4D can process additional modalities and sensors such as RGB-D frames, IMU-based egomotion, and Radar Doppler measurements, when available. One of the key innovations that allows for such a flexible framework is a modular representation of a 4D scene; specifically, per-view 4D predictions are encoded using a variety of egocentric factors (depthmaps and camera intrinsics) represented in local camera coordinates, and allocentric factors (camera extrinsics and scene flow) represented in global world coordinates. We achieve superior performance across diverse setups - both in terms of accuracy (2-3X lower error) and compute efficiency (15X faster), opening avenues for multiple downstream applications.