FoundationMotion: Auto-Labeling and Reasoning about Spatial Movement in Videos
作者: Yulu Gan, Ligeng Zhu, Dandan Shan, Baifeng Shi, Hongxu Yin, Boris Ivanovic, Song Han, Trevor Darrell, Jitendra Malik, Marco Pavone, Boyi Li
分类: cs.CV
发布日期: 2025-12-11
备注: Code is available at https://github.com/Wolfv0/FoundationMotion/tree/main
💡 一句话要点
FoundationMotion:提出自动标注与推理框架,提升视频空间运动理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 运动理解 视频分析 自动标注 大型语言模型 数据生成 空间推理 目标跟踪
📋 核心要点
- 现有运动数据集规模小、标注成本高,限制了模型在运动理解方面的性能。
- FoundationMotion提出全自动数据生成流程,利用对象轨迹和大型语言模型生成细粒度标注。
- 实验表明,使用FoundationMotion生成的数据集微调的模型,在运动理解任务上显著优于现有模型。
📝 摘要(中文)
本文提出FoundationMotion,一个全自动的数据生成流程,用于构建大规模运动数据集。该流程首先检测并跟踪视频中的对象,提取其轨迹,然后利用这些轨迹和视频帧,结合大型语言模型(LLMs)生成关于运动和空间推理的细粒度描述和多样化的问答对。利用该流程生成的数据集,可以对开源模型(如NVILA-Video-15B和Qwen2.5-7B)进行微调,从而显著提高运动理解能力,同时不影响其他任务的性能。实验表明,微调后的模型在各种运动理解数据集和基准测试中,优于Gemini-2.5 Flash等强大的闭源基线,以及Qwen2.5-VL-72B等大型开源模型。FoundationMotion为构建细粒度运动数据集提供了一种可扩展的解决方案,能够有效微调各种模型,从而增强运动理解和空间推理能力。
🔬 方法详解
问题定义:现有运动理解模型在处理复杂运动场景时表现不佳,主要原因是缺乏大规模、细粒度的运动数据集。人工标注成本高昂,难以扩展数据集规模,限制了模型性能的提升。因此,需要一种自动化的数据生成方法,以低成本构建大规模运动数据集,从而提升模型的运动理解能力。
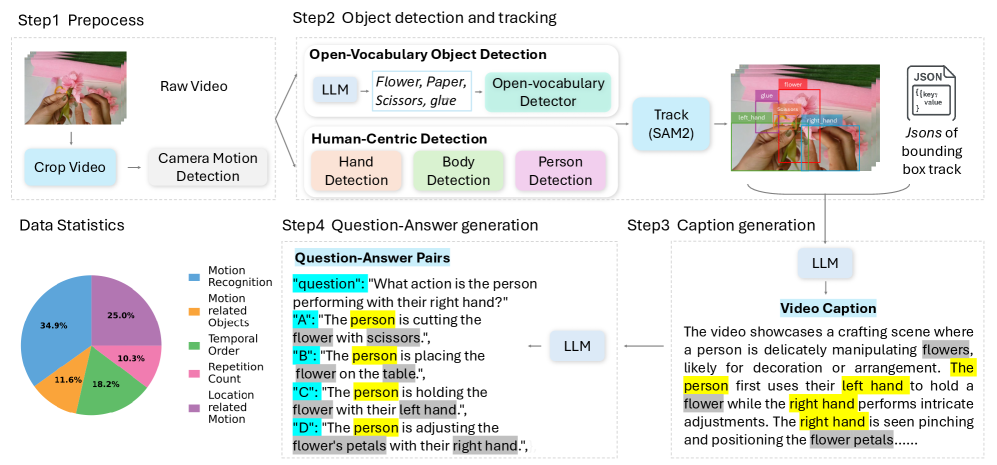
核心思路:FoundationMotion的核心思路是利用对象轨迹和大型语言模型(LLMs)自动生成细粒度的运动描述和问答对。通过对象检测和跟踪提取轨迹信息,然后利用LLMs的强大语言生成能力,将轨迹信息转化为自然语言描述和问答对,从而实现自动标注。这种方法可以显著降低数据标注成本,并生成多样化的运动数据。
技术框架:FoundationMotion的整体框架包含以下几个主要模块:1) 对象检测与跟踪模块:用于检测和跟踪视频中的对象,提取对象的运动轨迹。2) 轨迹分析模块:分析对象的运动轨迹,提取运动特征,如速度、加速度、方向等。3) LLM生成模块:利用大型语言模型,根据对象的运动轨迹和视频帧,生成细粒度的运动描述和问答对。4) 数据过滤与清洗模块:对生成的数据进行过滤和清洗,去除噪声数据,保证数据质量。
关键创新:FoundationMotion的关键创新在于提出了一种全自动的数据生成流程,将对象检测、跟踪和大型语言模型相结合,实现了低成本、大规模的运动数据生成。与传统的人工标注方法相比,该方法可以显著降低数据标注成本,并生成更加多样化的运动数据。此外,利用LLMs生成细粒度的运动描述和问答对,可以更好地训练模型理解运动的细节和上下文信息。
关键设计:在对象检测与跟踪模块中,可以使用现有的目标检测和跟踪算法,如YOLO、DeepSORT等。在LLM生成模块中,可以使用各种大型语言模型,如GPT-3、T5等。关键的设计在于如何将对象的运动轨迹信息有效地输入到LLM中,并指导LLM生成高质量的运动描述和问答对。可以使用各种prompt engineering技巧,例如,将对象的运动轨迹转化为自然语言描述,然后将这些描述作为LLM的输入,引导LLM生成更加准确和详细的运动描述和问答对。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用FoundationMotion生成的数据集微调后的模型,在多个运动理解数据集和基准测试中取得了显著的性能提升。例如,在某些数据集上,微调后的模型优于Gemini-2.5 Flash等强大的闭源基线,以及Qwen2.5-VL-72B等大型开源模型。这表明FoundationMotion能够有效地提升模型的运动理解能力。
🎯 应用场景
FoundationMotion的研究成果可广泛应用于机器人导航、自动驾驶、视频监控、体育分析等领域。通过提升模型对视频中物体运动的理解能力,可以实现更智能的机器人控制、更安全的自动驾驶系统、更高效的视频监控和更精准的体育赛事分析。未来,该技术有望推动人工智能在物理世界中的应用。
📄 摘要(原文)
Motion understanding is fundamental to physical reasoning, enabling models to infer dynamics and predict future states. However, state-of-the-art models still struggle on recent motion benchmarks, primarily due to the scarcity of large-scale, fine-grained motion datasets. Existing motion datasets are often constructed from costly manual annotation, severely limiting scalability. To address this challenge, we introduce FoundationMotion, a fully automated data curation pipeline that constructs large-scale motion datasets. Our approach first detects and tracks objects in videos to extract their trajectories, then leverages these trajectories and video frames with Large Language Models (LLMs) to generate fine-grained captions and diverse question-answer pairs about motion and spatial reasoning. Using datasets produced by this pipeline, we fine-tune open-source models including NVILA-Video-15B and Qwen2.5-7B, achieving substantial improvements in motion understanding without compromising performance on other tasks. Notably, our models outperform strong closed-source baselines like Gemini-2.5 Flash and large open-source models such as Qwen2.5-VL-72B across diverse motion understanding datasets and benchmarks. FoundationMotion thus provides a scalable solution for curating fine-grained motion datasets that enable effective fine-tuning of diverse models to enhance motion understanding and spatial reasoning capabilities.