PoseGAM: Robust Unseen Object Pose Estimation via Geometry-Aware Multi-View Reasoning
作者: Jianqi Chen, Biao Zhang, Xiangjun Tang, Peter Wonka
分类: cs.CV
发布日期: 2025-12-11
备注: Project page: https://windvchen.github.io/PoseGAM/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
PoseGAM:通过几何感知多视角推理实现鲁棒的未见物体姿态估计
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 6D姿态估计 未见物体 多视角推理 几何感知 深度学习 机器人视觉
📋 核心要点
- 现有方法依赖于查询图像与物体模型或模板图像之间的显式特征对应,这在处理未见物体时面临挑战。
- PoseGAM通过几何感知多视角推理,直接从查询图像和模板图像预测物体姿态,无需显式匹配。
- 实验结果表明,PoseGAM在多个基准测试中取得了显著的性能提升,尤其是在未见物体上表现出强大的泛化能力。
📝 摘要(中文)
本文提出PoseGAM,一个几何感知的多视角框架,用于直接从查询图像和多个模板图像预测物体姿态,从而避免了显式匹配的需求,解决了未见物体的6D姿态估计难题。该方法基于多视角基础模型架构,通过显式的基于点的几何信息和从几何表示网络学习到的特征,集成了物体几何信息。此外,构建了一个包含超过19万个对象的大规模合成数据集,以增强鲁棒性和泛化能力。在多个基准测试上的大量评估表明,该方法达到了最先进的性能,平均AR指标比现有方法提高了5.1%,在单个数据集上实现了高达17.6%的增益,表明其对未见物体具有很强的泛化能力。
🔬 方法详解
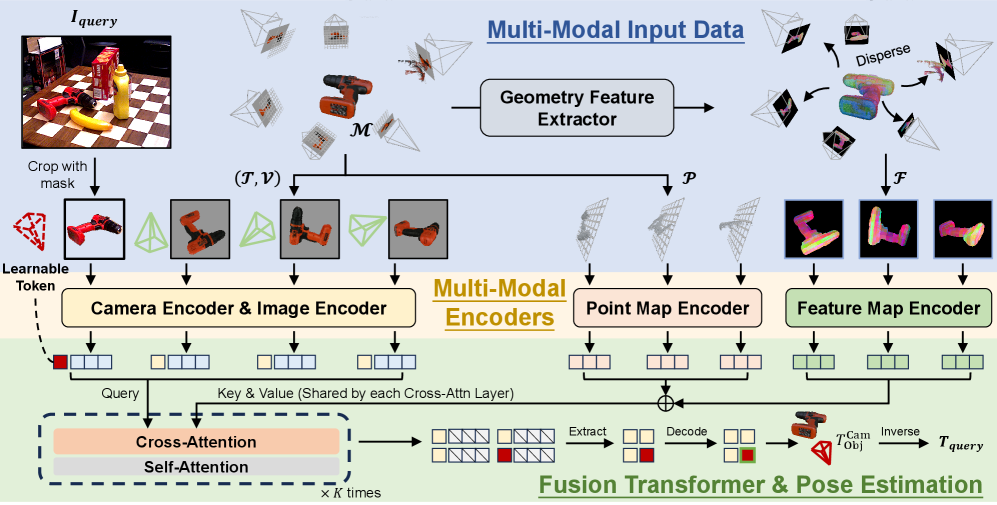
问题定义:论文旨在解决未见物体的6D姿态估计问题。现有方法通常依赖于查询图像和物体模型或模板图像之间的显式特征匹配,这种方法在处理未见物体时表现不佳,因为未见物体的特征可能与训练数据中的特征差异很大,导致匹配失败。
核心思路:PoseGAM的核心思路是利用多视角信息和几何信息,直接从查询图像和多个模板图像预测物体姿态,而无需进行显式的特征匹配。通过多视角信息,可以从不同角度观察物体,从而更全面地了解物体的形状和姿态。通过几何信息,可以约束姿态估计的结果,使其更加准确和鲁棒。
技术框架:PoseGAM的整体架构基于多视角基础模型。该框架包含以下主要模块:1) 特征提取模块,用于从查询图像和模板图像中提取特征;2) 几何表示模块,用于学习物体的几何信息;3) 多视角推理模块,用于融合多视角特征和几何信息,预测物体姿态。
关键创新:PoseGAM最重要的技术创新点在于其几何感知的多视角推理方法。该方法通过显式的基于点的几何信息和从几何表示网络学习到的特征,将物体几何信息集成到姿态估计过程中。这种方法可以有效地利用物体的几何约束,提高姿态估计的准确性和鲁棒性。与现有方法相比,PoseGAM不需要进行显式的特征匹配,因此可以更好地处理未见物体。
关键设计:PoseGAM的关键设计包括:1) 使用点云作为显式的几何表示;2) 使用几何表示网络学习物体的几何特征;3) 设计了一种多视角推理模块,用于融合多视角特征和几何信息。损失函数包括姿态损失和几何损失,用于约束姿态估计的结果和几何表示的准确性。
🖼️ 关键图片


📊 实验亮点
PoseGAM在多个基准测试中取得了显著的性能提升。例如,在平均AR指标上,PoseGAM比现有方法提高了5.1%,在单个数据集上实现了高达17.6%的增益。这些结果表明,PoseGAM对未见物体具有很强的泛化能力,并且在实际应用中具有很大的潜力。
🎯 应用场景
PoseGAM在机器人抓取、增强现实、自动驾驶等领域具有广泛的应用前景。它可以帮助机器人更好地理解周围环境,从而实现更精确的物体抓取和操作。在增强现实中,它可以用于将虚拟物体与真实场景进行精确对齐。在自动驾驶中,它可以用于准确地估计车辆周围物体的姿态,从而提高驾驶安全性。
📄 摘要(原文)
6D object pose estimation, which predicts the transformation of an object relative to the camera, remains challenging for unseen objects. Existing approaches typically rely on explicitly constructing feature correspondences between the query image and either the object model or template images. In this work, we propose PoseGAM, a geometry-aware multi-view framework that directly predicts object pose from a query image and multiple template images, eliminating the need for explicit matching. Built upon recent multi-view-based foundation model architectures, the method integrates object geometry information through two complementary mechanisms: explicit point-based geometry and learned features from geometry representation networks. In addition, we construct a large-scale synthetic dataset containing more than 190k objects under diverse environmental conditions to enhance robustness and generalization. Extensive evaluations across multiple benchmarks demonstrate our state-of-the-art performance, yielding an average AR improvement of 5.1% over prior methods and achieving up to 17.6% gains on individual datasets, indicating strong generalization to unseen objects. Project page: https://windvchen.github.io/PoseGAM/ .