Video Depth Propagation
作者: Luigi Piccinelli, Thiemo Wandel, Christos Sakaridis, Wim Abbeloos, Luc Van Gool
分类: cs.CV
发布日期: 2025-12-11
🔗 代码/项目: GITHUB
💡 一句话要点
VeloDepth:提出一种高效鲁棒的视频深度传播方法,用于实时深度估计。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱八:物理动画 (Physics-based Animation)
关键词: 视频深度估计 深度传播 时间一致性 光流估计 实时深度估计
📋 核心要点
- 现有视频深度估计方法在时间一致性和计算效率上存在不足,难以满足实时应用需求。
- VeloDepth利用时空先验和深度特征传播,通过光流扭曲和残差校正实现深度估计。
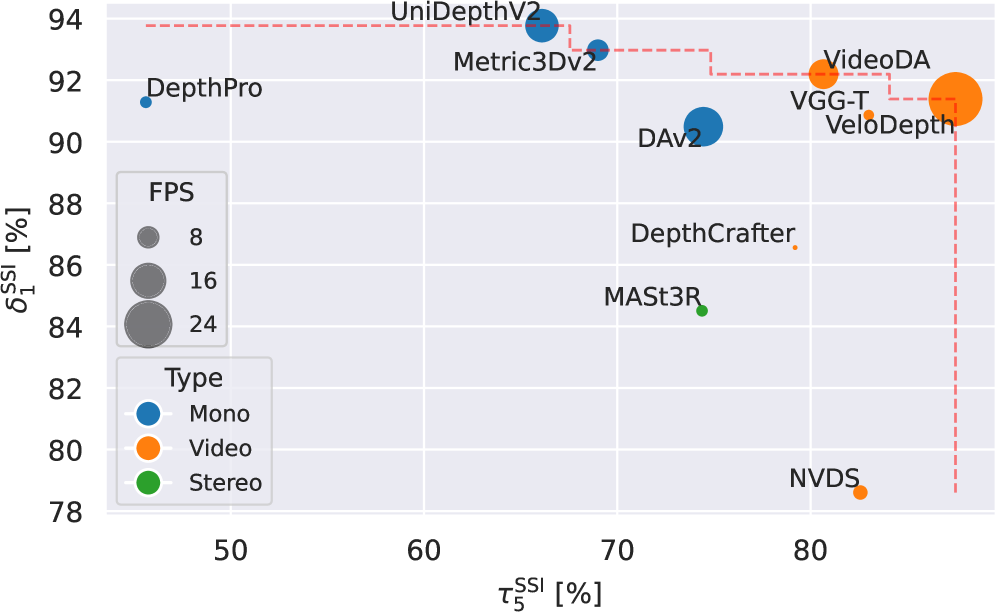
- 实验表明,VeloDepth在时间一致性方面达到SOTA,精度具有竞争力,且推理速度显著提升。
📝 摘要(中文)
视频深度估计对于现实世界应用中的视觉感知至关重要。然而,现有方法要么依赖于简单的逐帧单目模型,导致时间不一致和不准确,要么使用计算量大的时间建模,不适合实时应用。这些限制严重制约了实际应用中的通用性和性能。为了解决这个问题,我们提出VeloDepth,一种高效且鲁棒的在线视频深度估计流程,它有效地利用了先前深度预测的时空先验,并执行深度特征传播。我们的方法引入了一个新的传播模块,该模块使用基于光流的扭曲以及学习到的残差校正来细化和传播深度特征和预测。此外,我们的设计在结构上强制执行时间一致性,从而在连续帧之间产生稳定的深度预测,并提高了效率。在多个基准测试上的全面零样本评估表明,VeloDepth具有最先进的时间一致性和具有竞争力的准确性,同时与现有的基于视频的深度估计器相比,其推理速度明显更快。因此,VeloDepth为各种感知任务提供了一种实用、高效且准确的实时深度估计解决方案。代码和模型可在https://github.com/lpiccinelli-eth/velodepth获得。
🔬 方法详解
问题定义:现有视频深度估计方法主要面临两个挑战:一是基于单帧图像的深度估计方法缺乏时间一致性,导致视频帧之间的深度信息不稳定;二是基于时间建模的方法计算复杂度高,难以满足实时性要求。因此,如何在保证时间一致性的前提下,实现高效的视频深度估计是一个亟待解决的问题。
核心思路:VeloDepth的核心思路是利用视频帧之间的时间相关性,通过传播先前帧的深度信息来辅助当前帧的深度估计。具体来说,该方法通过光流估计来建立帧之间的对应关系,并将先前帧的深度特征和预测结果传播到当前帧,从而利用时空先验信息来提高深度估计的准确性和时间一致性。同时,为了弥补光流估计的误差,该方法还学习残差校正,进一步提升深度估计的鲁棒性。
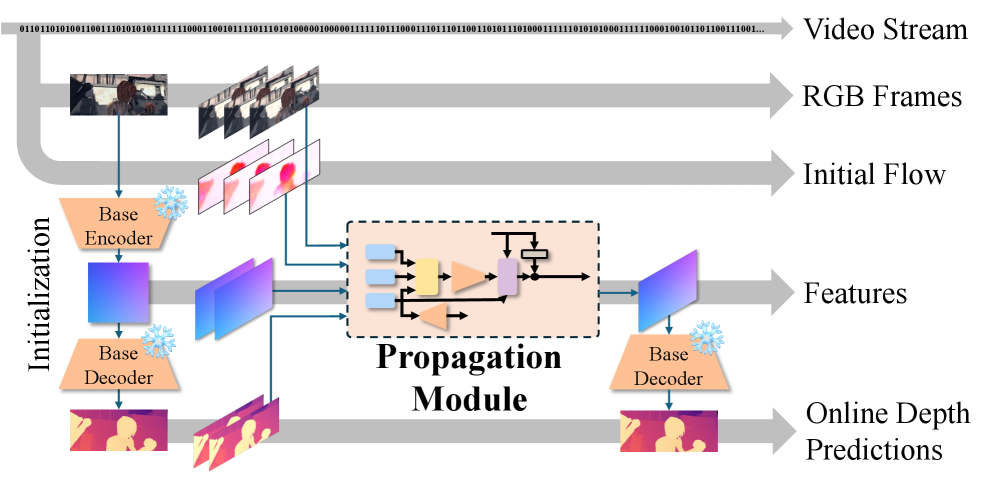
技术框架:VeloDepth的整体架构是一个在线视频深度估计流程,主要包含以下几个模块:1) 单帧深度估计模块:用于初始化第一帧的深度估计;2) 光流估计模块:用于估计相邻帧之间的光流;3) 传播模块:这是VeloDepth的核心模块,它利用光流将先前帧的深度特征和预测结果传播到当前帧,并进行残差校正;4) 深度融合模块:将传播的深度信息与当前帧的深度特征进行融合,得到最终的深度估计结果。整个流程以在线方式进行,即逐帧处理视频,并不断更新深度信息。
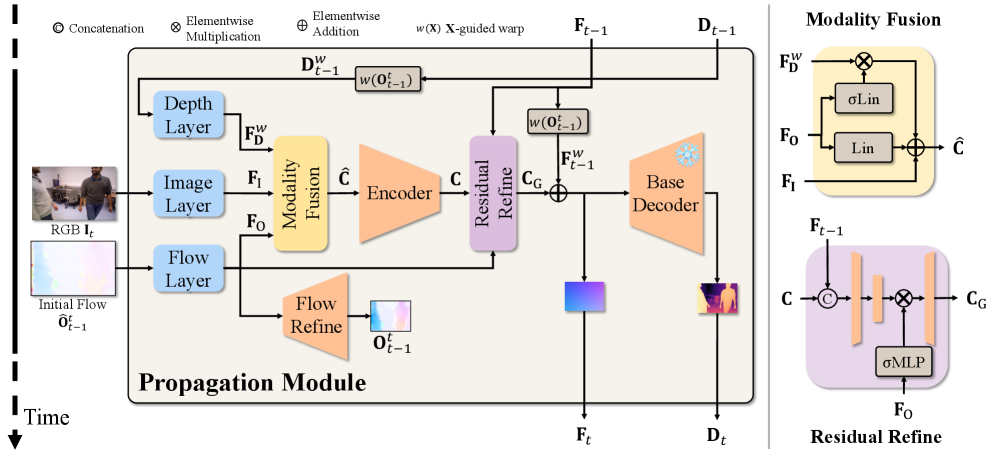
关键创新:VeloDepth的关键创新在于其提出的传播模块。该模块通过光流扭曲和残差校正相结合的方式,有效地利用了时空先验信息,从而在保证时间一致性的前提下,实现了高效的视频深度估计。与现有方法相比,VeloDepth不需要复杂的时序建模,因此计算复杂度更低,更适合实时应用。此外,VeloDepth的传播模块还具有一定的鲁棒性,能够应对光流估计的误差。
关键设计:传播模块的关键设计包括:1) 使用光流进行深度特征和预测的扭曲;2) 学习残差校正,以弥补光流估计的误差;3) 结构上强制执行时间一致性,例如,通过损失函数约束相邻帧之间的深度差异。具体的网络结构和损失函数细节在论文中进行了详细描述。此外,论文还对光流估计模块和深度融合模块进行了优化,以提高整体性能。
🖼️ 关键图片
📊 实验亮点
VeloDepth在多个基准测试上进行了零样本评估,结果表明其在时间一致性方面达到了最先进水平,并且在深度估计精度方面也具有竞争力。更重要的是,VeloDepth的推理速度明显快于现有的基于视频的深度估计器,使其更适合实时应用。具体而言,VeloDepth在保持较高精度的同时,能够以更高的帧率进行深度估计,从而提高了系统的响应速度和用户体验。
🎯 应用场景
VeloDepth在自动驾驶、机器人导航、增强现实等领域具有广泛的应用前景。它可以为这些应用提供准确、稳定的深度信息,从而提高系统的感知能力和决策能力。例如,在自动驾驶中,VeloDepth可以用于障碍物检测、场景理解和路径规划;在机器人导航中,它可以用于构建地图、定位和避障;在增强现实中,它可以用于虚拟物体的放置和交互。
📄 摘要(原文)
Depth estimation in videos is essential for visual perception in real-world applications. However, existing methods either rely on simple frame-by-frame monocular models, leading to temporal inconsistencies and inaccuracies, or use computationally demanding temporal modeling, unsuitable for real-time applications. These limitations significantly restrict general applicability and performance in practical settings. To address this, we propose VeloDepth, an efficient and robust online video depth estimation pipeline that effectively leverages spatiotemporal priors from previous depth predictions and performs deep feature propagation. Our method introduces a novel Propagation Module that refines and propagates depth features and predictions using flow-based warping coupled with learned residual corrections. In addition, our design structurally enforces temporal consistency, resulting in stable depth predictions across consecutive frames with improved efficiency. Comprehensive zero-shot evaluation on multiple benchmarks demonstrates the state-of-the-art temporal consistency and competitive accuracy of VeloDepth, alongside its significantly faster inference compared to existing video-based depth estimators. VeloDepth thus provides a practical, efficient, and accurate solution for real-time depth estimation suitable for diverse perception tasks. Code and models are available at https://github.com/lpiccinelli-eth/velodepth