Geo6DPose: Fast Zero-Shot 6D Object Pose Estimation via Geometry-Filtered Feature Matching
作者: Javier Villena Toro, Mehdi Tarkian
分类: cs.CV
发布日期: 2025-12-11
💡 一句话要点
Geo6DPose:基于几何滤波特征匹配的快速零样本6D物体姿态估计
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 6D姿态估计 零样本学习 几何滤波 机器人视觉 特征匹配
📋 核心要点
- 现有零样本6D姿态估计依赖大规模模型和云端推理,导致高延迟、高能耗,不适用于算力受限的机器人应用。
- Geo6DPose利用几何滤波策略,结合基础模型视觉特征,在本地实现快速、无需训练的零样本6D姿态估计。
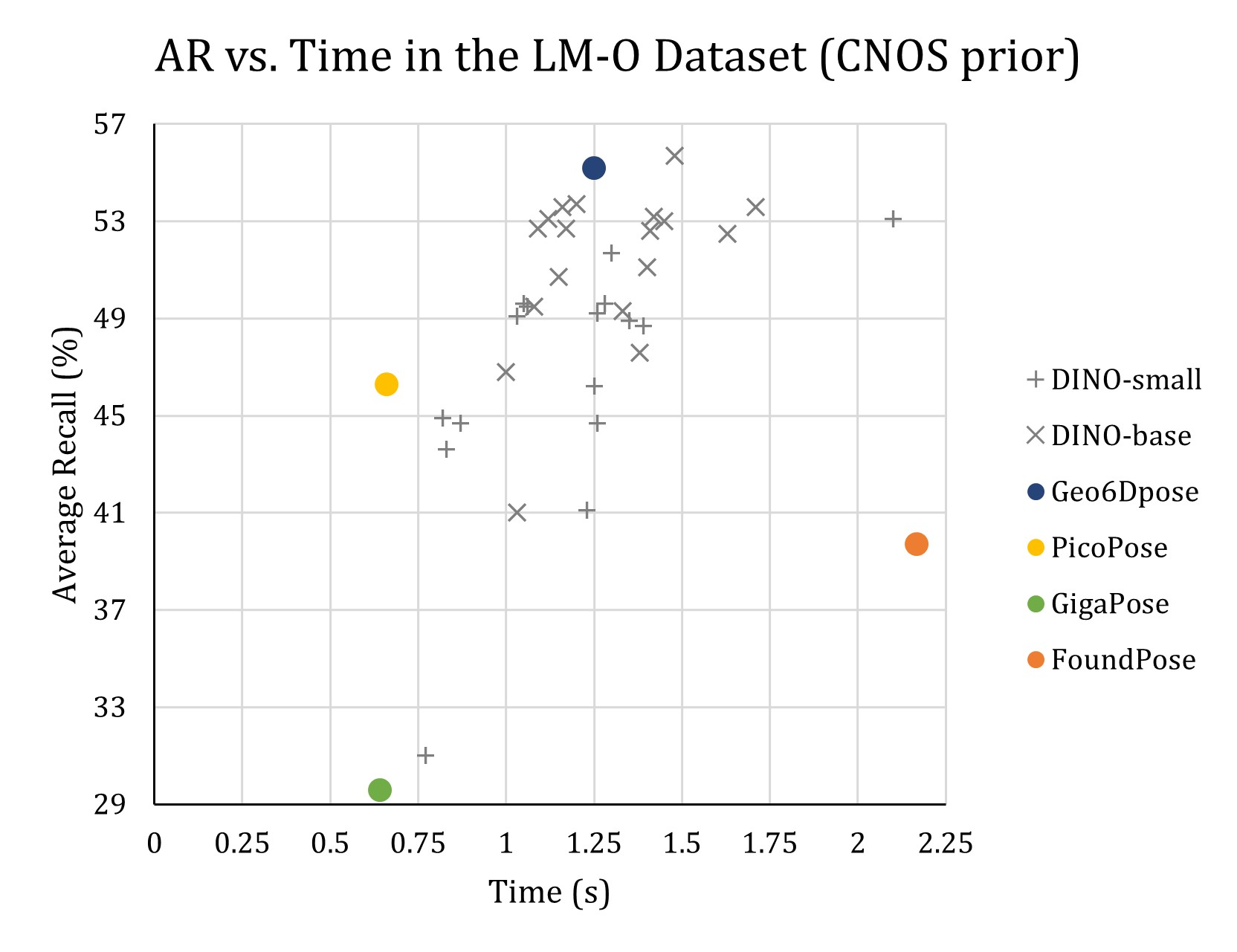
- 实验表明,Geo6DPose在单个GPU上实现亚秒级推理,且平均召回率与更大规模的零样本基线相当。
📝 摘要(中文)
本文提出Geo6DPose,一个轻量级、完全本地化且无需训练的零样本6D姿态估计流程,旨在通过几何可靠性替代模型规模。该方法结合了基础模型视觉特征和几何滤波策略:计算板载模板DINO描述符与场景块之间的相似度图,并通过将场景块中心投影到3D和模板描述符投影到物体模型坐标系来建立互对应关系。最终姿态通过对应关系驱动的RANSAC恢复,并使用加权几何对齐度量进行排序,该度量共同考虑了重投影一致性和空间支持,从而提高对噪声、杂乱和部分可见性的鲁棒性。Geo6DPose在单个商用GPU上实现了亚秒级推理,同时匹配了显著更大的零样本基线的平均召回率(53.7 AR,1.08 FPS)。它不需要训练、微调或网络访问,并且与不断发展的基础骨干网络兼容,从而推进了用于机器人部署的实用、完全本地化的6D感知。
🔬 方法详解
问题定义:现有零样本6D物体姿态估计方法依赖于大型模型和云端推理,这导致了高延迟、高能耗以及对网络连接的依赖,使其难以在资源受限的机器人应用中部署。这些方法通常无法满足实时性和本地推理的需求,限制了其在实际场景中的应用。
核心思路:Geo6DPose的核心思路是通过几何约束来提高姿态估计的准确性和效率,从而避免对大型模型的依赖。该方法利用预训练的基础模型提取视觉特征,并通过几何滤波策略来建立场景和物体模型之间的对应关系。通过这种方式,该方法能够在本地实现快速且准确的姿态估计。
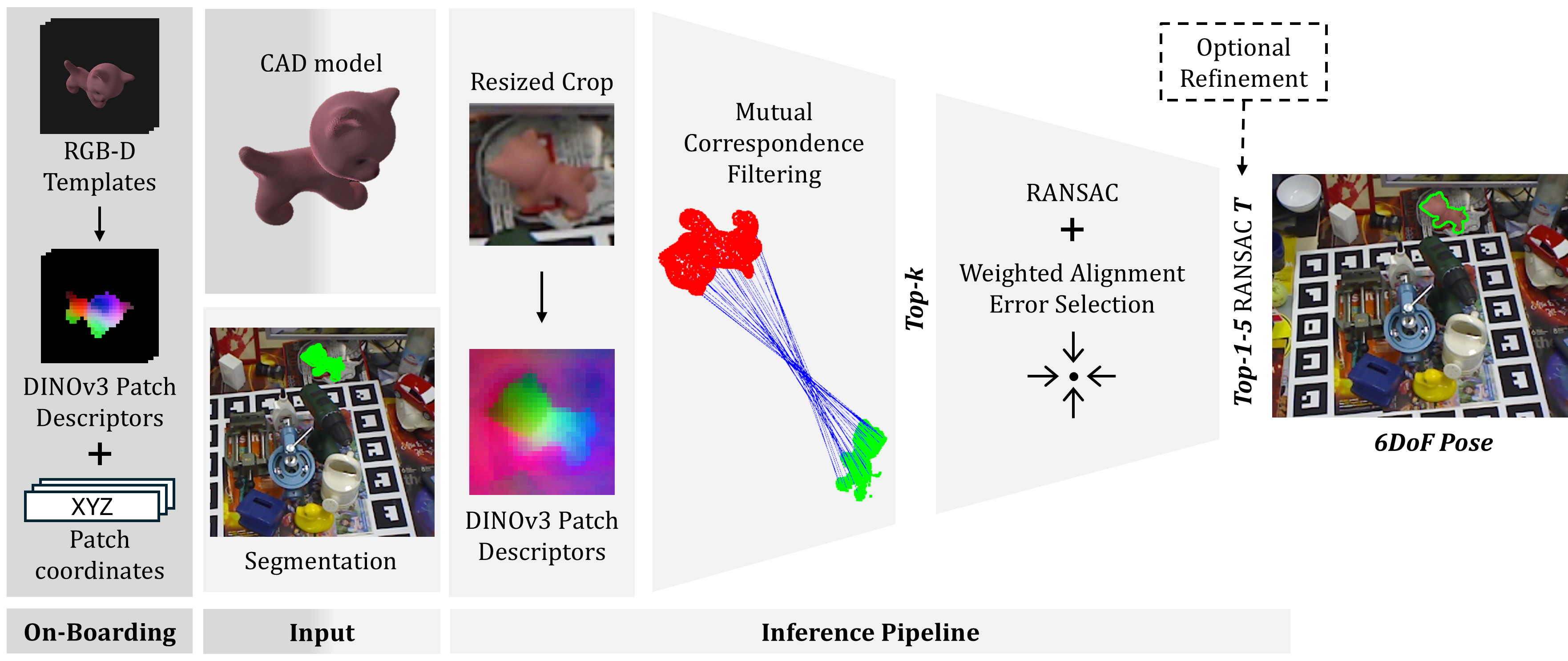
技术框架:Geo6DPose的整体流程包括以下几个主要阶段:1) 使用DINO等基础模型提取场景和物体模板的视觉特征。2) 计算场景块和模板描述符之间的相似度图。3) 将场景块中心投影到3D空间,并将模板描述符投影到物体模型坐标系,从而建立互对应关系。4) 使用RANSAC算法从对应关系中恢复姿态。5) 使用加权几何对齐度量对姿态进行排序,该度量考虑了重投影一致性和空间支持。
关键创新:Geo6DPose的关键创新在于其几何滤波策略,该策略利用几何约束来提高对应关系的准确性,从而实现更鲁棒的姿态估计。与现有方法相比,Geo6DPose不需要训练或微调,并且可以在本地运行,从而降低了延迟和能耗。此外,该方法与不断发展的基础骨干网络兼容,使其具有很强的适应性。
关键设计:Geo6DPose的关键设计包括:1) 使用DINO等预训练模型提取视觉特征,避免了从头开始训练模型的需要。2) 使用几何滤波策略来建立场景和物体模型之间的对应关系,提高了对应关系的准确性。3) 使用RANSAC算法来鲁棒地估计姿态。4) 使用加权几何对齐度量来对姿态进行排序,该度量考虑了重投影一致性和空间支持,提高了姿态估计的鲁棒性。具体的参数设置和损失函数细节未知。
🖼️ 关键图片

📊 实验亮点
Geo6DPose在单个商用GPU上实现了亚秒级推理(1.08 FPS),同时匹配了显著更大的零样本基线的平均召回率(53.7 AR)。该方法无需训练、微调或网络访问,并且与不断发展的基础骨干网络兼容。这些结果表明,Geo6DPose是一种高效且实用的零样本6D姿态估计方法。
🎯 应用场景
Geo6DPose适用于资源受限的机器人应用,例如移动机器人、无人机和协作机器人。该方法可以用于物体抓取、导航和场景理解等任务。由于其无需训练和本地推理的特性,Geo6DPose可以方便地部署在各种平台上,并能够适应不断变化的环境。该研究为机器人领域的6D姿态估计提供了一种实用且高效的解决方案,具有广阔的应用前景。
📄 摘要(原文)
Recent progress in zero-shot 6D object pose estimation has been driven largely by large-scale models and cloud-based inference. However, these approaches often introduce high latency, elevated energy consumption, and deployment risks related to connectivity, cost, and data governance; factors that conflict with the practical constraints of real-world robotics, where compute is limited and on-device inference is frequently required. We introduce Geo6DPose, a lightweight, fully local, and training-free pipeline for zero-shot 6D pose estimation that trades model scale for geometric reliability. Our method combines foundation model visual features with a geometric filtering strategy: Similarity maps are computed between onboarded template DINO descriptors and scene patches, and mutual correspondences are established by projecting scene patch centers to 3D and template descriptors to the object model coordinate system. Final poses are recovered via correspondence-driven RANSAC and ranked using a weighted geometric alignment metric that jointly accounts for reprojection consistency and spatial support, improving robustness to noise, clutter, and partial visibility. Geo6DPose achieves sub-second inference on a single commodity GPU while matching the average recall of significantly larger zero-shot baselines (53.7 AR, 1.08 FPS). It requires no training, fine-tuning, or network access, and remains compatible with evolving foundation backbones, advancing practical, fully local 6D perception for robotic deployment.