Robust Shape from Focus via Multiscale Directional Dilated Laplacian and Recurrent Network
作者: Khurram Ashfaq, Muhammad Tariq Mahmood
分类: cs.CV
发布日期: 2025-12-11
备注: Accepted to IJCV
💡 一句话要点
提出基于多尺度方向扩张拉普拉斯和循环网络的稳健Shape-from-Focus方法
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: Shape-from-Focus 深度估计 方向扩张拉普拉斯 循环神经网络 多尺度学习 深度学习 焦点堆栈
📋 核心要点
- 现有基于深度学习的SFF方法依赖复杂特征编码器和简单聚合,易引入伪影和噪声。
- 提出混合框架,利用手工DDL核提取鲁棒焦点体积,再用轻量级GRU网络迭代优化深度。
- 实验表明,该方法在合成和真实数据集上优于现有方法,提升了准确性和泛化能力。
📝 摘要(中文)
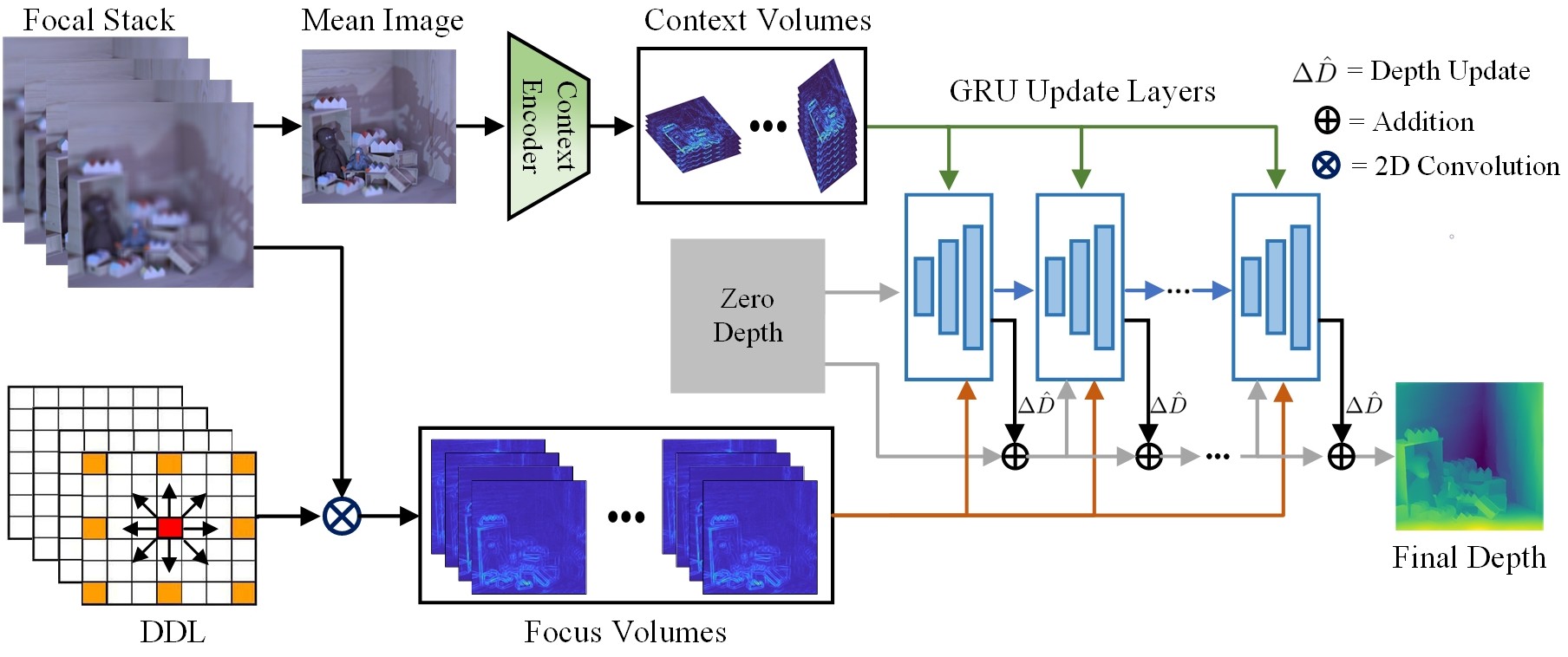
Shape-from-Focus (SFF) 是一种被动深度估计技术,它通过分析焦点堆栈中的焦点变化来推断场景深度。目前基于深度学习的SFF方法通常分两个阶段进行:首先,使用复杂的特征编码器提取焦点体积(焦点堆栈中每个像素的焦点可能性表示);然后,通过简单的一步聚合技术估计深度,但这种方法通常会引入伪影并放大深度图中的噪声。为了解决这些问题,我们提出了一种混合框架。我们的方法传统上使用手工制作的方向扩张拉普拉斯 (DDL) 核计算多尺度焦点体积,这些核捕获远距离和方向焦点变化以形成稳健的焦点体积。然后,将这些焦点体积输入到轻量级的、基于多尺度GRU的深度提取模块中,该模块以较低的分辨率迭代地细化初始深度估计,从而提高计算效率。最后,我们循环网络中学习到的凸上采样模块重建高分辨率深度图,同时保留精细的场景细节和清晰的边界。在合成和真实世界数据集上的大量实验表明,我们的方法优于最先进的深度学习和传统方法,在不同的焦点条件下实现了卓越的准确性和泛化能力。
🔬 方法详解
问题定义:Shape-from-Focus (SFF) 旨在从一系列不同焦点的图像中恢复场景的深度信息。现有基于深度学习的SFF方法通常依赖于复杂的特征编码器来提取焦点体积,然后使用简单的聚合技术来估计深度。这种方法的痛点在于,复杂的特征编码器计算量大,而简单聚合容易引入伪影,并放大深度图中的噪声,导致深度估计精度下降。
核心思路:本文的核心思路是结合传统方法和深度学习的优势。首先,利用手工设计的方向扩张拉普拉斯 (DDL) 核提取多尺度焦点体积,这种方法能够有效地捕捉长距离和方向性的焦点变化,从而形成更鲁棒的焦点体积。然后,使用轻量级的、基于多尺度GRU的循环神经网络来迭代地细化深度估计,从而提高深度估计的精度和鲁棒性。
技术框架:该方法的技术框架主要包括三个阶段:1) 使用DDL核提取多尺度焦点体积;2) 使用多尺度GRU网络进行深度提取和迭代优化;3) 使用学习到的凸上采样模块重建高分辨率深度图。首先,输入一系列不同焦点的图像,然后使用DDL核提取多尺度焦点体积。接着,将这些焦点体积输入到多尺度GRU网络中,该网络以较低的分辨率迭代地细化初始深度估计。最后,使用学习到的凸上采样模块将低分辨率的深度图重建为高分辨率的深度图。
关键创新:该方法最重要的技术创新点在于结合了传统的手工特征提取方法和深度学习的优势。传统的手工特征提取方法能够有效地捕捉图像中的局部特征,而深度学习方法能够学习到图像中的全局特征。通过将这两种方法结合起来,可以有效地提高深度估计的精度和鲁棒性。此外,使用多尺度GRU网络进行深度提取和迭代优化也是一个重要的创新点,它可以有效地提高深度估计的精度。
关键设计:DDL核的设计考虑了方向性和尺度信息,能够有效地捕捉长距离和方向性的焦点变化。多尺度GRU网络采用了GRU单元作为基本单元,能够有效地处理序列数据。学习到的凸上采样模块采用了凸优化的方法,能够有效地保留图像的细节信息。损失函数方面,可能采用了L1损失或L2损失来衡量预测深度图与真实深度图之间的差异。
🖼️ 关键图片


📊 实验亮点
该方法在合成和真实世界数据集上进行了广泛的实验,结果表明该方法优于最先进的深度学习和传统方法。具体而言,该方法在多个数据集上取得了state-of-the-art的性能,并且在不同的焦点条件下表现出良好的泛化能力。实验结果表明,该方法能够有效地提高深度估计的精度和鲁棒性。
🎯 应用场景
该研究成果可应用于机器人导航、三维重建、自动驾驶、医学成像等领域。通过准确估计场景深度,机器人可以更好地理解周围环境,实现自主导航;三维重建可以生成更逼真的三维模型;自动驾驶系统可以更安全地行驶;医学成像可以提供更清晰的图像,辅助医生进行诊断。未来,该方法有望进一步提升深度估计的精度和效率,推动相关领域的发展。
📄 摘要(原文)
Shape-from-Focus (SFF) is a passive depth estimation technique that infers scene depth by analyzing focus variations in a focal stack. Most recent deep learning-based SFF methods typically operate in two stages: first, they extract focus volumes (a per pixel representation of focus likelihood across the focal stack) using heavy feature encoders; then, they estimate depth via a simple one-step aggregation technique that often introduces artifacts and amplifies noise in the depth map. To address these issues, we propose a hybrid framework. Our method computes multi-scale focus volumes traditionally using handcrafted Directional Dilated Laplacian (DDL) kernels, which capture long-range and directional focus variations to form robust focus volumes. These focus volumes are then fed into a lightweight, multi-scale GRU-based depth extraction module that iteratively refines an initial depth estimate at a lower resolution for computational efficiency. Finally, a learned convex upsampling module within our recurrent network reconstructs high-resolution depth maps while preserving fine scene details and sharp boundaries. Extensive experiments on both synthetic and real-world datasets demonstrate that our approach outperforms state-of-the-art deep learning and traditional methods, achieving superior accuracy and generalization across diverse focal conditions.