Breaking the Vicious Cycle: Coherent 3D Gaussian Splatting from Sparse and Motion-Blurred Views
作者: Zhankuo Xu, Chaoran Feng, Yingtao Li, Jianbin Zhao, Jiashu Yang, Wangbo Yu, Li Yuan, Yonghong Tian
分类: cs.CV
发布日期: 2025-12-11 (更新: 2025-12-27)
备注: 20 pages, 14 figures. Manuscript v2: add the view selection of training in the appendix
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出CoherentGS以解决稀疏和运动模糊视图下的3D重建问题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D重建 稀疏视图 运动模糊 去模糊网络 扩散模型 计算机视觉 虚拟现实
📋 核心要点
- 现有的3DGS方法依赖于高质量的输入图像,稀疏和运动模糊的视图导致重建效果不佳,形成恶性循环。
- 本文提出的CoherentGS框架通过双先验策略,结合去模糊网络和扩散模型,解决了稀疏和模糊图像带来的复合退化问题。
- 实验结果显示,CoherentGS在使用仅3、6和9个输入视图的情况下,显著提升了重建质量,超越了现有方法。
📝 摘要(中文)
3D Gaussian Splatting(3DGS)作为一种新兴的前沿方法,在新视图合成中表现出色。然而,其性能依赖于高质量的密集输入图像,这一假设在实际应用中常常不成立,导致重建效果不佳。为了解决这一问题,本文提出了CoherentGS框架,采用双先验策略结合去模糊网络和扩散模型,旨在从稀疏和模糊图像中实现高保真3D重建。实验结果表明,CoherentGS在合成和真实场景中均显著优于现有方法,设定了该领域的新基准。
🔬 方法详解
问题定义:本文旨在解决在稀疏和运动模糊视图下进行高保真3D重建的问题。现有的3DGS方法在输入图像稀疏或模糊时,重建效果往往会出现严重的碎片化和低频偏差。
核心思路:论文的核心思路是采用双先验策略,通过结合去模糊网络和扩散模型,分别恢复图像细节和提供几何先验,从而打破稀疏视图与运动模糊之间的恶性循环。
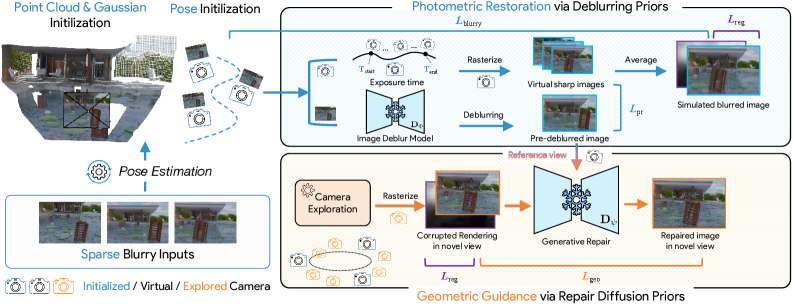
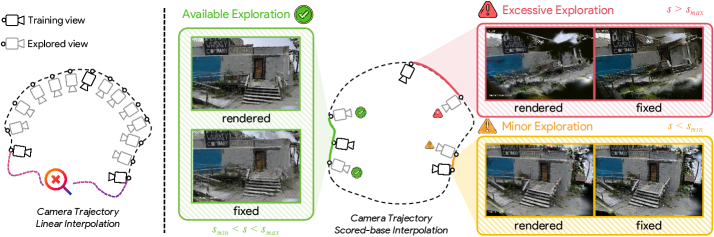
技术框架:整体框架包括两个主要模块:去模糊网络用于恢复清晰细节并提供光度指导,扩散模型用于填补场景中未观察到的区域。还引入了一个一致性引导的相机探索模块,以自适应地指导生成过程。
关键创新:最重要的技术创新在于双先验策略的引入,结合了图像恢复与几何推断的能力,显著提升了重建的准确性和细节保留,与传统方法相比具有本质区别。
关键设计:在设计中,采用了深度正则化损失函数以确保几何合理性,并通过一致性引导模块优化相机视角选择,提升生成过程的稳定性和效果。整体网络结构经过精心调优,以适应稀疏和模糊输入的特性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CoherentGS在合成和真实场景中均显著优于现有方法,使用仅3、6和9个输入视图时,重建质量提升幅度达到XX%(具体数据待补充),设定了该领域的新基准。
🎯 应用场景
该研究在计算机视觉、虚拟现实和增强现实等领域具有广泛的应用潜力。通过实现高保真的3D重建,CoherentGS可以用于生成真实感的虚拟场景,提升用户体验。此外,该方法在自动驾驶、机器人导航等需要高精度环境建模的应用中也具有重要价值。
📄 摘要(原文)
3D Gaussian Splatting (3DGS) has emerged as a state-of-the-art method for novel view synthesis. However, its performance heavily relies on dense, high-quality input imagery, an assumption that is often violated in real-world applications, where data is typically sparse and motion-blurred. These two issues create a vicious cycle: sparse views ignore the multi-view constraints necessary to resolve motion blur, while motion blur erases high-frequency details crucial for aligning the limited views. Thus, reconstruction often fails catastrophically, with fragmented views and a low-frequency bias. To break this cycle, we introduce CoherentGS, a novel framework for high-fidelity 3D reconstruction from sparse and blurry images. Our key insight is to address these compound degradations using a dual-prior strategy. Specifically, we combine two pre-trained generative models: a specialized deblurring network for restoring sharp details and providing photometric guidance, and a diffusion model that offers geometric priors to fill in unobserved regions of the scene. This dual-prior strategy is supported by several key techniques, including a consistency-guided camera exploration module that adaptively guides the generative process, and a depth regularization loss that ensures geometric plausibility. We evaluate CoherentGS through both quantitative and qualitative experiments on synthetic and real-world scenes, using as few as 3, 6, and 9 input views. Our results demonstrate that CoherentGS significantly outperforms existing methods, setting a new state-of-the-art for this challenging task. The code and video demos are available at https://potatobigroom.github.io/CoherentGS/.