Visual Funnel: Resolving Contextual Blindness in Multimodal Large Language Models
作者: Woojun Jung, Jaehoon Go, Mingyu Jeon, Sunjae Yoon, Junyeong Kim
分类: cs.CV, cs.AI
发布日期: 2025-12-11
💡 一句话要点
提出Visual Funnel,解决多模态大语言模型中的上下文盲区问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 上下文盲区 视觉推理 注意力机制 分层上下文 图像裁剪 视觉信息结构化
📋 核心要点
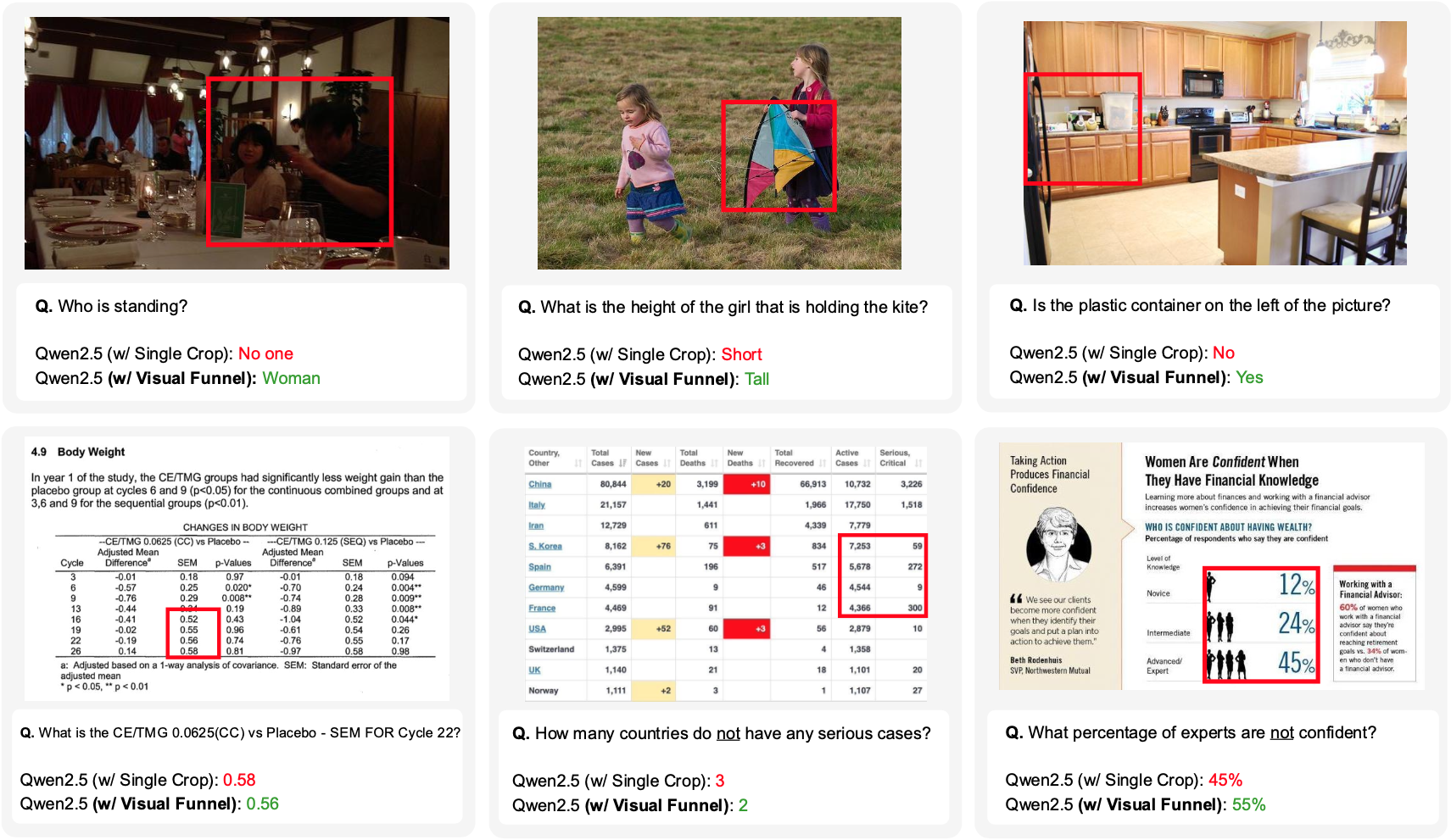
- 多模态大语言模型在感知细粒度视觉细节方面存在不足,导致“上下文盲区”问题,限制了其在需要高精度的任务中的应用。
- Visual Funnel通过上下文锚定和熵缩放的投资组合构建,保留了从焦点细节到全局环境的分层上下文信息,从而解决上下文盲区问题。
- 实验表明,Visual Funnel显著优于单裁剪和非结构化多裁剪方法,验证了分层结构对于解决上下文盲区的重要性。
📝 摘要(中文)
多模态大语言模型(MLLM)展现了强大的推理能力,但常常无法感知细粒度的视觉细节,限制了其在精度要求高的任务中的应用。裁剪图像的显著区域的方法提供了一种部分解决方案,但我们发现它们引入了一个关键的限制:“上下文盲区”。即使所有必要的视觉信息都存在,由于高保真细节(来自裁剪区域)和更广泛的全局上下文(来自原始图像)之间的结构断裂,也会发生这种失败。我们认为,这种限制并非源于信息“数量”的缺乏,而是源于模型输入中“结构多样性”的不足。为了解决这个问题,我们提出了一种无需训练的两步方法Visual Funnel。Visual Funnel首先执行上下文锚定,在一次前向传递中识别感兴趣区域。然后,它构建一个熵缩放的投资组合,通过基于注意力熵动态确定裁剪大小并细化裁剪中心,来保留从焦点细节到更广泛环境的分层上下文。通过大量的实验,我们证明了Visual Funnel明显优于朴素的单裁剪和非结构化多裁剪基线。我们的结果进一步验证了简单地添加更多非结构化裁剪提供的收益有限甚至有害,证实了我们的投资组合的分层结构是解决上下文盲区的关键。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLM)中存在的“上下文盲区”问题。现有方法,如裁剪显著区域,虽然能提供高保真细节,但破坏了图像的全局上下文信息,导致模型无法有效利用视觉信息进行推理。这种方法的痛点在于缺乏对视觉信息结构化理解,无法将局部细节与全局环境有效关联起来。
核心思路:论文的核心思路是构建一个具有分层结构的视觉信息输入,即Visual Funnel。该方法通过保留从焦点细节到全局环境的上下文信息,使模型能够同时关注局部细节和全局环境,从而克服上下文盲区。这种设计基于作者的观察,即上下文盲区并非源于信息量的不足,而是源于信息结构多样性的缺失。
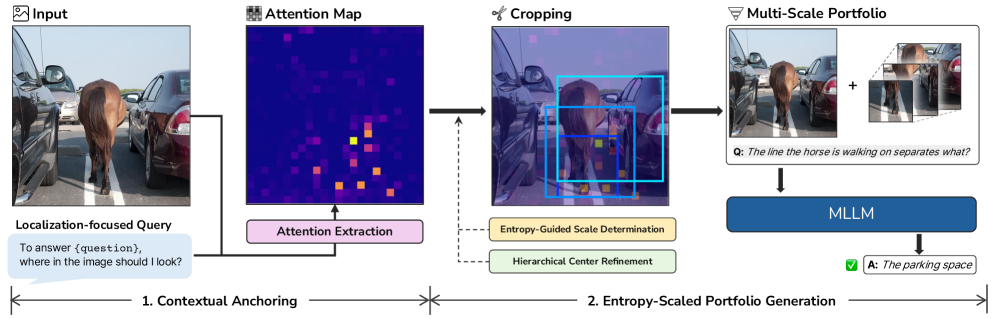
技术框架:Visual Funnel包含两个主要步骤:1) 上下文锚定(Contextual Anchoring):使用一次前向传递识别图像中的感兴趣区域。2) 熵缩放的投资组合构建(Entropy-Scaled Portfolio Construction):基于注意力熵动态确定裁剪大小并细化裁剪中心,构建一个包含不同尺度裁剪区域的集合,从而保留分层上下文信息。
关键创新:该方法最重要的创新点在于其分层上下文信息的构建方式。与简单的单裁剪或非结构化多裁剪方法不同,Visual Funnel通过注意力熵来动态调整裁剪区域的大小和位置,从而保证了裁剪区域之间的结构关系,使得模型能够更好地理解图像内容。
关键设计:Visual Funnel的关键设计包括:1) 使用注意力熵作为裁剪大小的指导信号,使得裁剪区域能够自适应地关注信息量大的区域。2) 构建熵缩放的投资组合,包含不同尺度的裁剪区域,从而保留了从焦点细节到全局环境的分层上下文信息。3) 使用一次前向传递进行上下文锚定,降低了计算复杂度。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Visual Funnel在多个视觉推理任务上显著优于单裁剪和非结构化多裁剪基线。例如,在某项实验中,Visual Funnel的性能提升了超过10%。此外,实验还验证了简单增加非结构化裁剪数量并不能有效解决上下文盲区问题,反而可能降低性能,突显了Visual Funnel分层结构的重要性。
🎯 应用场景
Visual Funnel可应用于需要精细视觉理解的多模态任务,例如医学图像诊断、自动驾驶中的场景理解、以及需要精确识别物体及其关系的机器人操作等。该方法能够提升模型在这些任务中的性能,并有望推动多模态大语言模型在实际应用中的普及。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) demonstrate impressive reasoning capabilities, but often fail to perceive fine-grained visual details, limiting their applicability in precision-demanding tasks. While methods that crop salient regions of an image offer a partial solution, we identify a critical limitation they introduce: "Contextual Blindness". This failure occurs due to structural disconnect between high-fidelity details (from the crop) and the broader global context (from the original image), even when all necessary visual information is present. We argue that this limitation stems not from a lack of information 'Quantity', but from a lack of 'Structural Diversity' in the model's input. To resolve this, we propose Visual Funnel, a training-free, two-step approach. Visual Funnel first performs Contextual Anchoring to identify the region of interest in a single forward pass. It then constructs an Entropy-Scaled Portfolio that preserves the hierarchical context - ranging from focal detail to broader surroundings - by dynamically determining crop sizes based on attention entropy and refining crop centers. Through extensive experiments, we demonstrate that Visual Funnel significantly outperforms naive single-crop and unstructured multi-crop baselines. Our results further validate that simply adding more unstructured crops provides limited or even detrimental benefits, confirming that the hierarchical structure of our portfolio is key to resolving Contextual Blindness.