Hybrid Transformer-Mamba Architecture for Weakly Supervised Volumetric Medical Segmentation
作者: Yiheng Lyu, Lian Xu, Mohammed Bennamoun, Farid Boussaid, Coen Arrow, Girish Dwivedi
分类: cs.CV
发布日期: 2025-12-11
🔗 代码/项目: GITHUB
💡 一句话要点
提出TranSamba,一种混合Transformer-Mamba架构,用于弱监督体积医学图像分割。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 弱监督学习 医学图像分割 Transformer Mamba 体积数据 3D上下文建模 状态空间模型
📋 核心要点
- 现有弱监督医学图像分割方法忽略了体积数据的3D特性,限制了分割性能。
- TranSamba利用Transformer和Mamba的优势,通过跨平面信息交换增强3D上下文建模能力。
- 实验表明,TranSamba在多个数据集上超越现有方法,实现了最先进的弱监督分割性能。
📝 摘要(中文)
本文提出TranSamba,一种混合Transformer-Mamba架构,旨在捕获3D上下文信息,用于弱监督体积医学图像分割。现有方法通常依赖于2D编码器,忽略了数据的固有体积特性。TranSamba通过Cross-Plane Mamba块增强了标准的Vision Transformer主干网络,利用状态空间模型的线性复杂度,实现相邻切片之间的高效信息交换。这种信息交换增强了Transformer块计算的切片内成对自注意力,直接促进了对象定位的注意力图生成。TranSamba实现了有效的体积建模,其时间复杂度随输入体积深度线性缩放,并保持批量处理的恒定内存使用。在三个数据集上的大量实验表明,TranSamba建立了新的state-of-the-art性能,在不同的模态和病理条件下始终优于现有方法。源代码和训练模型已公开。
🔬 方法详解
问题定义:论文旨在解决弱监督体积医学图像分割问题。现有方法主要采用2D编码器,无法充分利用体积数据的3D上下文信息,导致分割精度受限。此外,直接应用3D卷积或Transformer计算成本高昂,难以处理大规模体积数据。
核心思路:论文的核心思路是结合Transformer的全局建模能力和Mamba状态空间模型的线性复杂度,设计一种混合架构TranSamba。通过Cross-Plane Mamba块实现相邻切片间的高效信息交换,增强Transformer的自注意力机制,从而提升3D上下文建模能力。
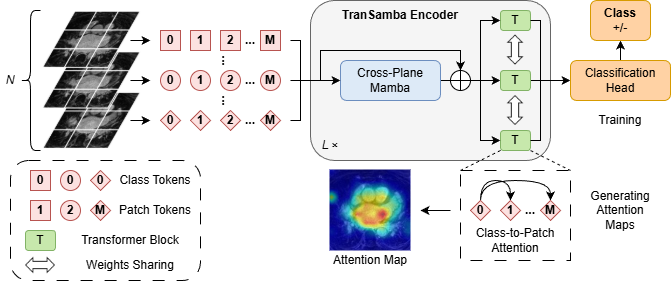
技术框架:TranSamba的整体架构基于Vision Transformer (ViT)。首先,将输入体积数据分割成一系列切片。然后,ViT处理每个切片,提取特征。关键在于,在ViT的某些层中,插入Cross-Plane Mamba块,用于在相邻切片之间传递信息。最后,利用解码器将特征映射恢复到原始分辨率,进行像素级别的分割预测。
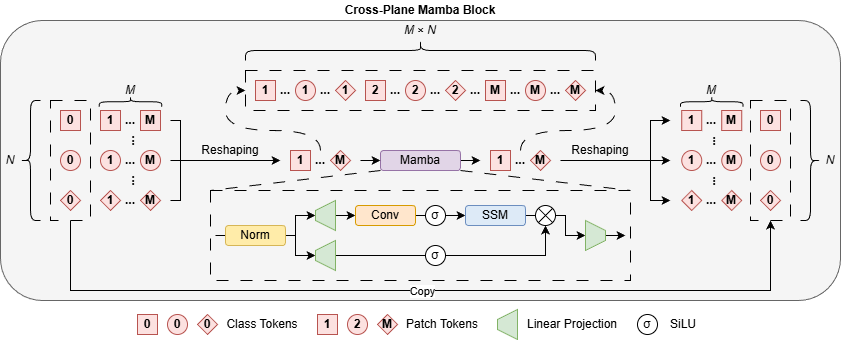
关键创新:TranSamba的关键创新在于Cross-Plane Mamba块的设计。它利用Mamba模型的线性复杂度,高效地在相邻切片之间交换信息,弥补了传统Transformer在处理长序列时的计算瓶颈。这种跨平面信息交换增强了Transformer的自注意力机制,使其能够更好地捕捉3D上下文信息。
关键设计:Cross-Plane Mamba块的具体实现包括线性投影、状态空间模型和残差连接。Mamba模型的参数是可学习的,可以自适应地调整信息交换的强度。损失函数通常采用Dice loss或Cross-Entropy loss,用于优化分割结果。具体的网络层数、Mamba块的插入位置等超参数需要根据具体数据集进行调整。
🖼️ 关键图片
📊 实验亮点
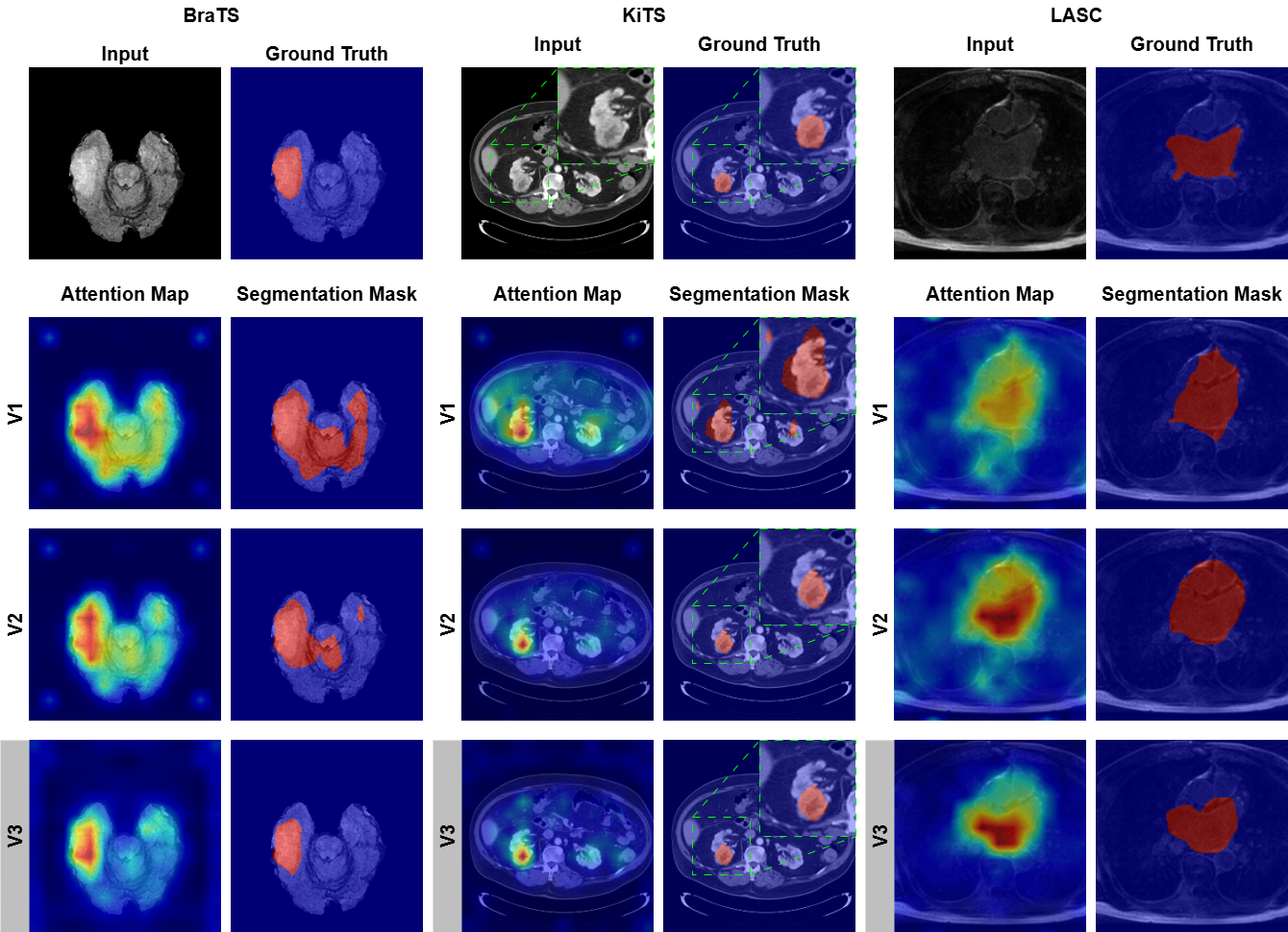
TranSamba在三个不同的医学图像数据集上进行了评估,包括不同模态(如CT、MRI)和不同病理(如肿瘤、器官)。实验结果表明,TranSamba在所有数据集上都取得了state-of-the-art的性能,显著优于现有的弱监督分割方法。具体性能提升幅度未知,但论文强调了其一致性和优越性。
🎯 应用场景
TranSamba在医学影像分析领域具有广泛的应用前景,可用于辅助医生进行疾病诊断、治疗计划制定和疗效评估。例如,可以应用于肿瘤分割、器官分割、病灶检测等任务。该方法能够有效利用弱监督数据,降低标注成本,加速医学影像分析的自动化进程,提高诊断效率和准确性。
📄 摘要(原文)
Weakly supervised semantic segmentation offers a label-efficient solution to train segmentation models for volumetric medical imaging. However, existing approaches often rely on 2D encoders that neglect the inherent volumetric nature of the data. We propose TranSamba, a hybrid Transformer-Mamba architecture designed to capture 3D context for weakly supervised volumetric medical segmentation. TranSamba augments a standard Vision Transformer backbone with Cross-Plane Mamba blocks, which leverage the linear complexity of state space models for efficient information exchange across neighboring slices. The information exchange enhances the pairwise self-attention within slices computed by the Transformer blocks, directly contributing to the attention maps for object localization. TranSamba achieves effective volumetric modeling with time complexity that scales linearly with the input volume depth and maintains constant memory usage for batch processing. Extensive experiments on three datasets demonstrate that TranSamba establishes new state-of-the-art performance, consistently outperforming existing methods across diverse modalities and pathologies. Our source code and trained models are openly accessible at: https://github.com/YihengLyu/TranSamba.