CoSPlan: Corrective Sequential Planning via Scene Graph Incremental Updates
作者: Shresth Grover, Priyank Pathak, Akash Kumar, Vibhav Vineet, Yogesh S Rawat
分类: cs.CV
发布日期: 2025-12-11 (更新: 2025-12-27)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出基于场景图增量更新的纠错序列规划方法CoSPlan,提升VLM在复杂任务中的推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 序列规划 场景图 增量更新 纠错 机器人 人工智能
📋 核心要点
- 现有视觉-语言模型在视觉序列规划中,难以有效检测和纠正错误步骤,导致性能不佳。
- 提出场景图增量更新(SGI)方法,通过引入中间推理步骤,增强模型对序列的推理能力。
- 实验表明,SGI在CoSPlan基准上平均性能提升5.2%,并能推广到传统规划任务。
📝 摘要(中文)
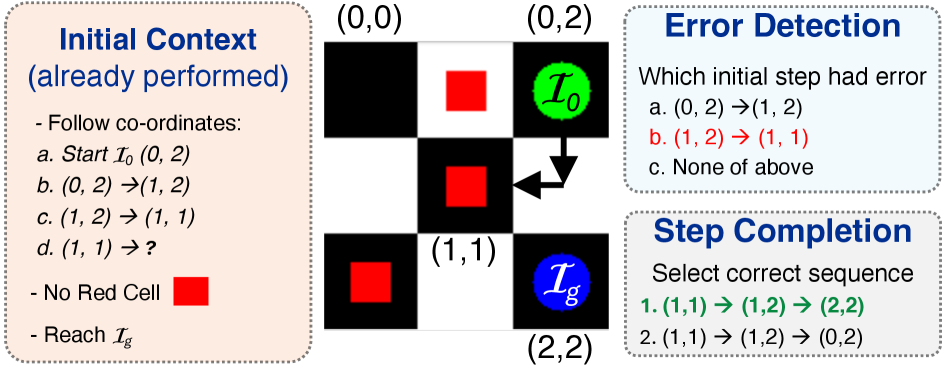
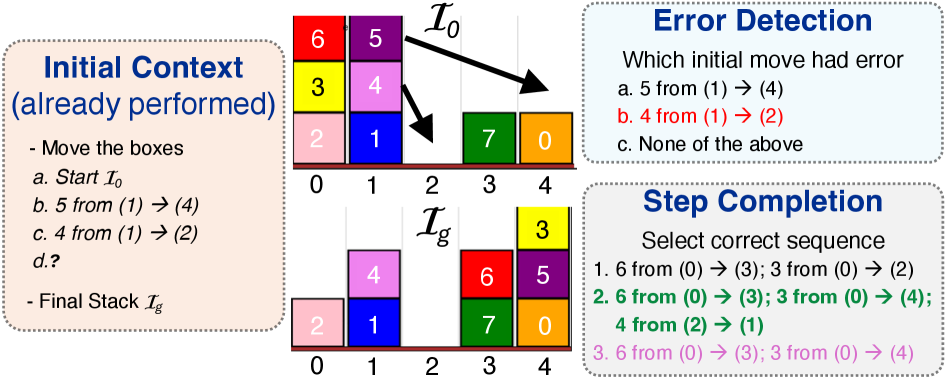
大规模视觉-语言模型(VLMs)在复杂推理方面表现出令人印象深刻的能力,但在视觉序列规划(即执行多步骤动作以达到目标)方面的探索仍然不足。此外,实际的序列规划通常涉及非最优(错误)步骤,这给VLMs提出了检测和纠正此类步骤的挑战。我们提出了纠错序列规划基准(CoSPlan),以评估VLMs在易出错的、基于视觉的序列规划任务中的表现,涵盖四个领域:迷宫导航、方块重排、图像重建和对象重组。CoSPlan评估两个关键能力:错误检测(识别非最优动作)和步骤完成(纠正并完成动作序列以达到目标)。尽管使用了最先进的推理技术,如思维链和场景图,但VLMs(例如Intern-VLM和Qwen2)在CoSPlan上表现不佳,未能利用上下文线索来达到目标。为了解决这个问题,我们提出了一种新颖的无训练方法,即场景图增量更新(SGI),它在初始状态和目标状态之间引入中间推理步骤。SGI帮助VLMs推理序列,平均性能提升5.2%。除了提高纠错序列规划的可靠性外,SGI还推广到传统的规划任务,如Plan-Bench和VQA。
🔬 方法详解
问题定义:论文旨在解决视觉序列规划中,视觉-语言模型难以处理错误步骤的问题。现有方法在面对非最优动作时,无法有效检测并纠正,导致最终无法达到目标。这限制了VLMs在实际复杂任务中的应用。
核心思路:论文的核心思路是通过在初始状态和目标状态之间引入中间推理步骤,逐步更新场景图,从而帮助VLMs更好地理解序列中的依赖关系,并纠正错误。这种增量式的推理方式模拟了人类解决问题的过程,使得模型能够更好地利用上下文信息。
技术框架:整体框架包括以下几个阶段:1) 输入初始状态和目标状态的视觉信息;2) 使用VLM生成初步的动作序列;3) 在执行动作序列的过程中,使用场景图表示当前状态;4) 通过场景图增量更新模块,逐步更新场景图,并生成中间状态;5) VLM基于更新后的场景图,重新评估并纠正动作序列;6) 重复步骤3-5,直到达到目标状态或达到最大迭代次数。
关键创新:最重要的创新点在于场景图增量更新(SGI)模块。SGI通过逐步更新场景图,为VLM提供更丰富的上下文信息,使其能够更好地理解序列中的依赖关系,并纠正错误。与传统的端到端方法相比,SGI更具可解释性,并且能够更好地处理复杂任务。
关键设计:SGI的关键设计包括:1) 使用图神经网络(GNN)来表示和更新场景图;2) 设计了一种新的损失函数,用于鼓励模型生成更准确的中间状态;3) 使用注意力机制来融合视觉信息和语言信息,从而更好地理解场景。
🖼️ 关键图片

📊 实验亮点
实验结果表明,提出的SGI方法在CoSPlan基准上取得了显著的性能提升,平均性能提升5.2%。此外,SGI方法还能够推广到传统的规划任务,如Plan-Bench和VQA,表明其具有良好的泛化能力。与Intern-VLM和Qwen2等基线模型相比,SGI能够更有效地利用上下文信息,从而更好地完成序列规划任务。
🎯 应用场景
该研究成果可应用于机器人导航、自动化装配、智能家居等领域。通过提升视觉-语言模型在序列规划中的纠错能力,可以使机器人更好地理解人类指令,并在复杂环境中完成任务。此外,该方法还可以应用于虚拟现实和游戏开发等领域,提升用户体验。
📄 摘要(原文)
Large-scale Vision-Language Models (VLMs) exhibit impressive complex reasoning capabilities but remain largely unexplored in visual sequential planning, i.e., executing multi-step actions towards a goal. Additionally, practical sequential planning often involves non-optimal (erroneous) steps, challenging VLMs to detect and correct such steps. We propose Corrective Sequential Planning Benchmark (CoSPlan) to evaluate VLMs in error-prone, vision-based sequential planning tasks across 4 domains: maze navigation, block rearrangement, image reconstruction,and object reorganization. CoSPlan assesses two key abilities: Error Detection (identifying non-optimal action) and Step Completion (correcting and completing action sequences to reach the goal). Despite using state-of-the-art reasoning techniques such as Chain-of-Thought and Scene Graphs, VLMs (e.g. Intern-VLM and Qwen2) struggle on CoSPlan, failing to leverage contextual cues to reach goals. Addressing this, we propose a novel training-free method, Scene Graph Incremental updates (SGI), which introduces intermediate reasoning steps between the initial and goal states. SGI helps VLMs reason about sequences, yielding an average performance gain of 5.2%. In addition to enhancing reliability in corrective sequential planning, SGI generalizes to traditional planning tasks such as Plan-Bench and VQA. Project Page : https://shroglck.github.io/cos_plan/