Latent Chain-of-Thought World Modeling for End-to-End Driving
作者: Shuhan Tan, Kashyap Chitta, Yuxiao Chen, Ran Tian, Yurong You, Yan Wang, Wenjie Luo, Yulong Cao, Philipp Krahenbuhl, Marco Pavone, Boris Ivanovic
分类: cs.CV, cs.RO
发布日期: 2025-12-11
备注: Technical Report
💡 一句话要点
提出Latent-CoT-Drive,利用隐空间思维链进行端到端自动驾驶决策。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 思维链 隐空间模型 端到端学习 强化学习
📋 核心要点
- 现有VLA模型依赖自然语言进行CoT推理,但文本可能并非最高效的推理表示。
- LCDrive在隐空间中表达CoT,通过动作提议和世界模型tokens交替推理,统一推理与决策。
- 实验表明,LCDrive在推理速度、轨迹质量和强化学习效果上均优于传统方法。
📝 摘要(中文)
本文提出了一种名为Latent-CoT-Drive (LCDrive) 的模型,用于端到端自动驾驶。该模型使用隐空间中的思维链 (CoT) 来提升驾驶性能和安全性。与以往使用自然语言进行CoT推理的方法不同,LCDrive 使用一种隐式语言来表达CoT,这种语言能够捕捉所考虑的驾驶行为的可能结果。通过在与动作对齐的隐空间中表示CoT推理和决策,该方法统一了两者。模型通过交替使用动作提议 tokens(与模型输出动作使用相同的词汇表)和世界模型 tokens(基于学习到的隐式世界模型,表达这些动作的未来结果)来进行推理。模型首先通过监督动作提议和世界模型 tokens,使其基于场景的真实未来轨迹进行冷启动。然后,通过闭环强化学习进行后训练,以增强推理能力。在大型端到端驾驶基准测试中,LCDrive 实现了更快的推理速度、更好的轨迹质量,并且相比于非推理和文本推理基线,从交互式强化学习中获得了更大的提升。
🔬 方法详解
问题定义:现有端到端自动驾驶模型,特别是Vision-Language-Action (VLA) 模型,在进行复杂场景决策时,依赖自然语言进行思维链 (CoT) 推理。然而,自然语言可能不是表达推理过程的最有效方式,存在信息冗余和推理效率低下的问题。此外,文本推理与最终的动作决策之间存在gap,难以直接优化。
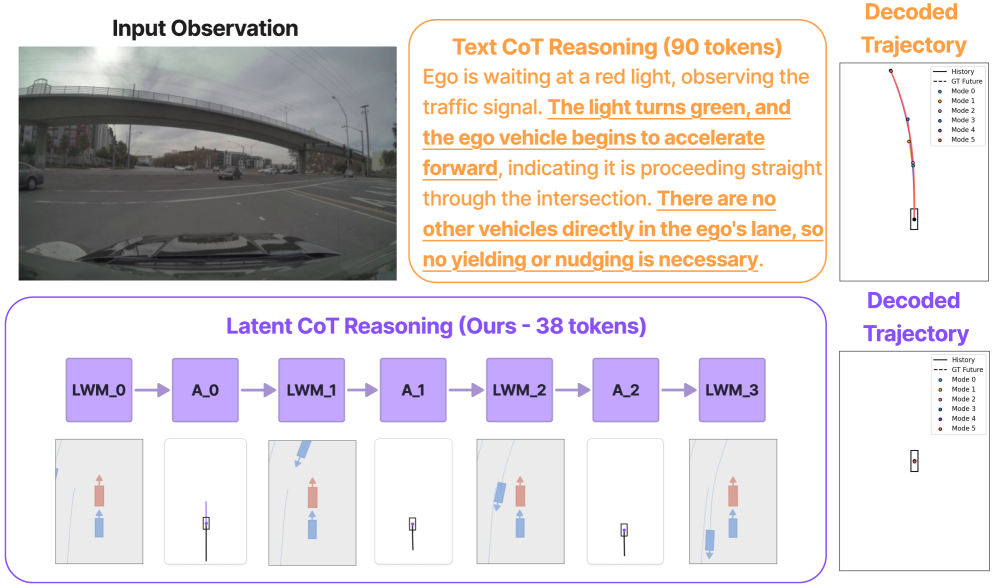
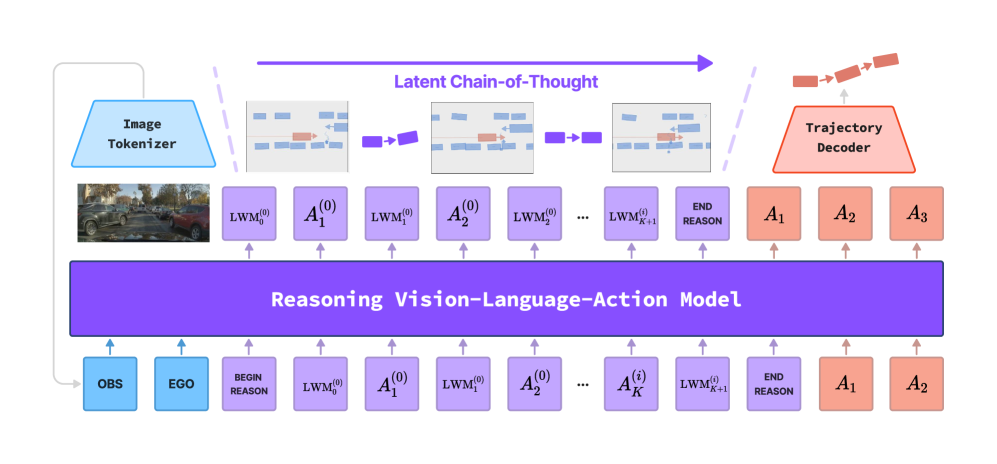
核心思路:LCDrive的核心思路是使用一个与动作对齐的隐空间来表示思维链。在这个隐空间中,模型通过交替生成“动作提议”和“世界模型”tokens来进行推理。动作提议直接对应于模型可以执行的动作,而世界模型tokens则预测这些动作可能导致的未来场景状态。这种设计将推理过程与动作决策紧密结合,避免了自然语言带来的效率瓶颈。
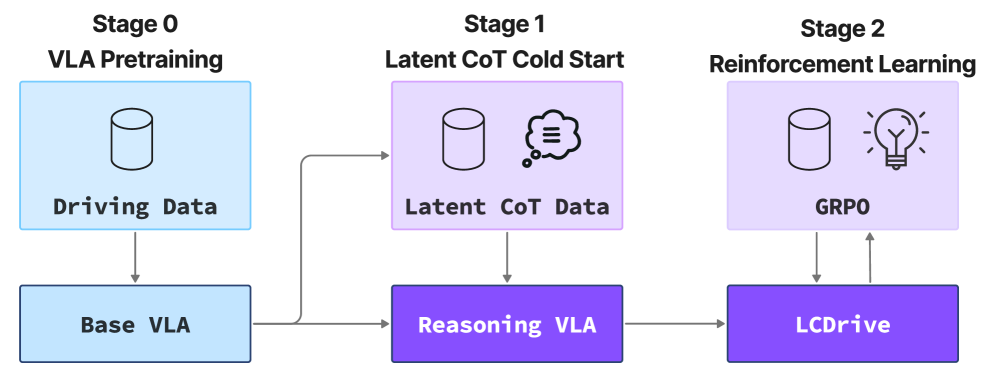
技术框架:LCDrive的整体框架包含以下几个主要部分:1) 感知模块:用于从输入图像中提取场景特征;2) 隐空间CoT模块:交替生成动作提议tokens和世界模型tokens,进行推理;3) 动作解码器:将隐空间CoT的输出解码为最终的驾驶动作。模型首先通过模仿学习进行预训练,然后通过强化学习进行微调,以优化长期驾驶性能。
关键创新:LCDrive最重要的创新在于使用隐空间来表示思维链。与传统的文本CoT方法相比,隐空间CoT更加紧凑、高效,并且能够更好地与动作决策相结合。此外,通过动作提议和世界模型tokens的交替生成,模型能够更好地探索和评估不同的驾驶策略。
关键设计:LCDrive的关键设计包括:1) 动作提议tokens:使用与模型输出动作相同的词汇表,确保推理过程与动作决策的一致性;2) 世界模型tokens:基于学习到的隐式世界模型,预测动作的未来结果;3) 冷启动策略:通过监督动作提议和世界模型tokens,使其基于真实未来轨迹进行初始化;4) 强化学习微调:使用闭环强化学习来优化模型的长期驾驶性能。
🖼️ 关键图片
📊 实验亮点
LCDrive 在大规模端到端驾驶基准测试中表现出色,实现了更快的推理速度、更好的轨迹质量,并且相比于非推理和文本推理基线,从交互式强化学习中获得了更大的提升。具体性能数据未知,但强调了优于现有方法的显著进步。
🎯 应用场景
LCDrive 技术可应用于各种自动驾驶场景,尤其是在复杂和不确定性高的环境中。通过提升推理效率和决策质量,该技术有望提高自动驾驶系统的安全性、可靠性和泛化能力。此外,该方法也可以推广到其他需要复杂推理和决策的机器人应用中。
📄 摘要(原文)
Recent Vision-Language-Action (VLA) models for autonomous driving explore inference-time reasoning as a way to improve driving performance and safety in challenging scenarios. Most prior work uses natural language to express chain-of-thought (CoT) reasoning before producing driving actions. However, text may not be the most efficient representation for reasoning. In this work, we present Latent-CoT-Drive (LCDrive): a model that expresses CoT in a latent language that captures possible outcomes of the driving actions being considered. Our approach unifies CoT reasoning and decision making by representing both in an action-aligned latent space. Instead of natural language, the model reasons by interleaving (1) action-proposal tokens, which use the same vocabulary as the model's output actions; and (2) world model tokens, which are grounded in a learned latent world model and express future outcomes of these actions. We cold start latent CoT by supervising the model's action proposals and world model tokens based on ground-truth future rollouts of the scene. We then post-train with closed-loop reinforcement learning to strengthen reasoning capabilities. On a large-scale end-to-end driving benchmark, LCDrive achieves faster inference, better trajectory quality, and larger improvements from interactive reinforcement learning compared to both non-reasoning and text-reasoning baselines.