Hierarchy-Aware Multimodal Unlearning for Medical AI
作者: Fengli Wu, Vaidehi Patil, Jaehong Yoon, Yue Zhang, Mohit Bansal
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-12-10 (更新: 2026-01-23)
备注: Dataset and Code: https://github.com/fengli-wu/MedForget
💡 一句话要点
提出MedForget基准和CHIP方法,解决医学AI中层级多模态数据的不可学习问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器不可学习 多模态学习 医学AI 层级结构 隐私保护
📋 核心要点
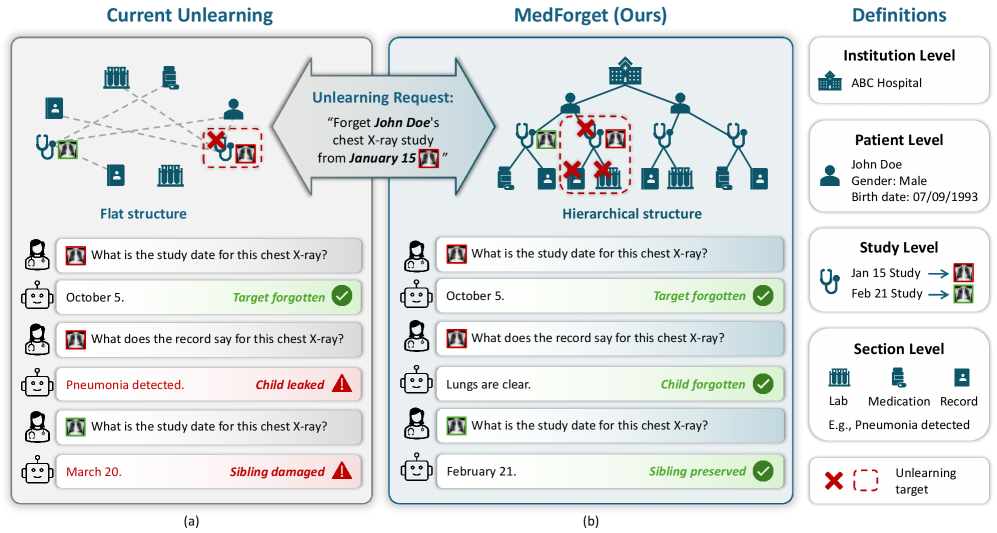
- 现有不可学习基准难以处理医学数据的层级和多模态结构,无法有效评估实际应用中的不可学习能力。
- 提出CHIP方法,通过选择性移除目标数据相关的权重子空间,同时保留层级结构中的共享信息,实现高效遗忘。
- MedForget基准和CHIP方法在实验中表现出优越的遗忘-保留性能,并在下游任务中保持了良好的效用。
📝 摘要(中文)
预训练多模态大语言模型(MLLM)越来越多地应用于医疗AI等敏感领域,这些领域受到HIPAA和GDPR等隐私法规的约束,要求能够选择性地移除个人或机构的数据。这推动了机器不可学习的研究,旨在消除目标数据对已训练模型的影响。然而,现有的不可学习基准无法反映真实世界医疗数据的层级和多模态结构,限制了其在实践中正确评估不可学习能力。因此,我们引入了MedForget,这是一个层级感知的多模态不可学习基准,它将医院数据建模为嵌套结构,从而能够对保留和遗忘分割之间的多模态不可学习进行细粒度评估。使用当前不可学习方法的实验表明,现有方法难以在不降低下游医疗效用的情况下实现有效的层级感知遗忘。为了解决这个限制,我们提出了一种用于不可学习的跨模态层级信息投影(CHIP),这是一种无需训练、层级感知的多模态不可学习方法,它通过选择性地移除特定于目标的权重子空间,同时保留兄弟姐妹共享的信息来删除信息。实验表明,与现有方法相比,CHIP在所有层级上实现了最高的遗忘-保留性能差距,同时保持了具有竞争力的下游效用。总的来说,MedForget为评估医学数据的结构化多模态不可学习提供了一个实用的、符合HIPAA的基准,而CHIP为层级感知遗忘提供了一个有效且通用的解决方案,可以在删除和效用之间取得平衡。
🔬 方法详解
问题定义:论文旨在解决医学AI领域中,如何安全有效地从预训练多模态模型中移除特定层级和模态的数据影响,同时保持模型在其他任务上的性能。现有方法无法很好地处理医学数据的层级结构和多模态特性,导致遗忘效果不佳或下游任务性能显著下降。
核心思路:论文的核心思路是利用层级结构信息,在模型参数空间中找到与目标数据相关的子空间,并选择性地移除这些子空间,从而实现对目标数据的遗忘。同时,保留层级结构中共享的信息,以减少对下游任务性能的影响。这种方法避免了对整个模型进行重新训练,提高了效率。
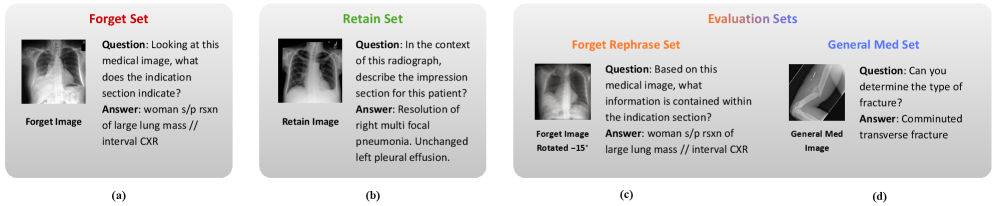
技术框架:CHIP方法主要包含以下几个阶段:1) 数据准备:构建符合层级结构的多模态医学数据集,并划分遗忘集和保留集。2) 权重子空间识别:利用遗忘集数据,识别模型中与目标数据相关的权重子空间。这可以通过计算权重对遗忘集数据的敏感度来实现。3) 权重子空间移除:选择性地移除识别出的权重子空间,可以使用剪枝或正则化等方法。4) 模型评估:评估模型在遗忘集上的遗忘效果和在保留集上的性能。
关键创新:CHIP方法的关键创新在于其层级感知的权重子空间选择性移除策略。与现有方法相比,CHIP能够更精确地定位和移除与目标数据相关的信息,同时保留层级结构中的共享信息,从而在遗忘效果和下游任务性能之间取得更好的平衡。此外,CHIP是一种无需重新训练的方法,具有更高的效率。
关键设计:CHIP方法的关键设计包括:1) 层级结构建模:将医学数据建模为嵌套结构,例如医院-科室-患者。2) 权重敏感度计算:使用遗忘集数据计算模型权重对目标数据的敏感度,例如可以使用梯度或激活值等指标。3) 权重子空间选择:根据权重敏感度选择需要移除的权重子空间,可以使用阈值或剪枝比例等参数。4) 跨模态信息融合:在多模态数据中,需要考虑不同模态之间的信息融合,例如可以使用注意力机制或跨模态对齐等方法。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CHIP方法在MedForget基准上取得了显著的遗忘效果,同时保持了良好的下游任务性能。具体来说,CHIP在所有层级上实现了最高的遗忘-保留性能差距,并且在多个下游医学任务上取得了与现有方法相当甚至更好的性能。这表明CHIP能够在保护隐私的同时,保持模型的实用性。
🎯 应用场景
该研究成果可应用于医疗影像分析、电子病历处理等多个领域,有助于保护患者隐私,满足HIPAA等法规要求。通过选择性地移除特定患者或机构的数据,可以避免模型泄露敏感信息,同时保持模型在其他患者数据上的诊断能力。未来,该技术还可推广到其他涉及敏感数据的领域,如金融、法律等。
📄 摘要(原文)
Pretrained Multimodal Large Language Models (MLLMs) are increasingly used in sensitive domains such as medical AI, where privacy regulations like HIPAA and GDPR require specific removal of individuals' or institutions' data. This motivates machine unlearning, which aims to remove the influence of target data from a trained model. However, existing unlearning benchmarks fail to reflect the hierarchical and multimodal structure of real-world medical data, limiting their ability to properly evaluate unlearning in practice. Therefore, we introduce MedForget, a hierarchy-aware multimodal unlearning benchmark that models hospital data as a nested structure, enabling fine-grained evaluation of multimodal unlearning across retain and forget splits. Experiments with current unlearning methods show that existing approaches struggle to achieve effective hierarchy-aware forgetting without degrading downstream medical utility. To address this limitation, we propose Cross-modal Hierarchy-Informed Projection for unlearning (CHIP), a training-free, hierarchy-aware multimodal unlearning method that deletes information by selectively removing target-specific weight subspaces while preserving sibling-shared information. Experiments show that CHIP achieves the highest forget-retain performance gap across all hierarchy levels while maintaining competitive downstream utility compared to existing methods. Overall, MedForget provides a practical, HIPAA-aligned benchmark for evaluating structured multimodal unlearning for medical data, and CHIP offers an effective and general solution for hierarchy-aware forgetting that balances deletion with utility.