Rethinking Chain-of-Thought Reasoning for Videos
作者: Yiwu Zhong, Zi-Yuan Hu, Yin Li, Liwei Wang
分类: cs.CV, cs.AI, cs.CL, cs.LG
发布日期: 2025-12-10
备注: Technical report
🔗 代码/项目: GITHUB
💡 一句话要点
提出一种高效视频推理框架,通过精简推理链和视觉tokens提升多模态大模型的效率和性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频推理 思维链 多模态大模型 视觉tokens压缩 高效推理
📋 核心要点
- 现有视频多模态大模型推理依赖冗长的思维链和大量视觉tokens,效率较低。
- 提出一种高效的后训练和推理框架,通过压缩视觉tokens和生成简短推理轨迹来提升效率。
- 实验表明,该框架在多个基准测试中实现了具有竞争力的性能,同时显著提高了推理效率。
📝 摘要(中文)
本文重新思考了用于视频推理的思维链(Chain-of-Thought, CoT)推理方法。尽管CoT在自然语言处理中取得了巨大成功,并且多模态大语言模型(MLLMs)已将其扩展到视频推理,但这些模型通常依赖于冗长的推理链和大量的输入视觉tokens。通过基准研究的经验观察,我们假设简洁的推理与减少的视觉tokens集足以实现有效的视频推理。为了验证这一假设,我们设计并验证了一个高效的后训练和推理框架,该框架增强了视频MLLM的推理能力。我们的框架使模型能够处理压缩的视觉tokens,并在回答问题之前生成简短的推理轨迹。由此产生的模型显著提高了推理效率,在不同的基准测试中提供了具有竞争力的性能,并且避免了依赖人工CoT注释或监督微调。总而言之,我们的结果表明,对于一般的视频推理来说,冗长、类人的CoT推理可能不是必需的,而简洁的推理既有效又高效。代码将在https://github.com/LaVi-Lab/Rethink_CoT_Video发布。
🔬 方法详解
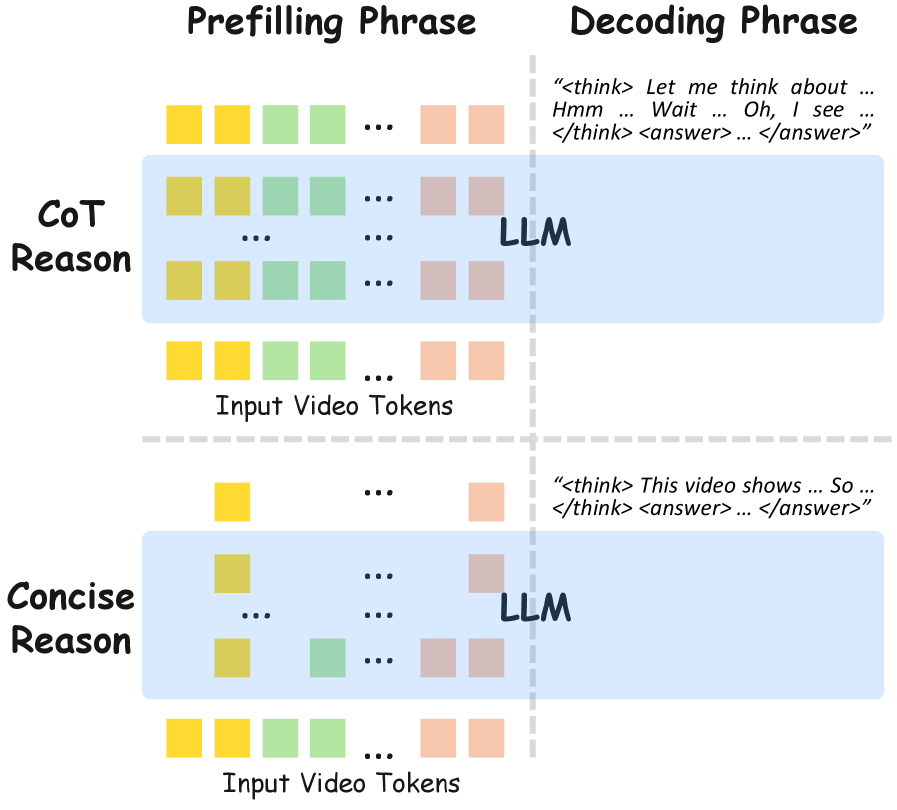
问题定义:现有视频多模态大语言模型在进行视频推理时,通常采用类似于人类的思维链(Chain-of-Thought, CoT)方式,即通过生成一系列中间推理步骤来逐步解决问题。然而,这种方法需要处理大量的视觉tokens和冗长的推理链,导致计算成本高昂,推理效率低下。现有方法的痛点在于效率和资源消耗,限制了其在实际应用中的部署。
核心思路:论文的核心思路是,对于视频推理任务,并不一定需要像人类一样进行冗长而复杂的思考过程。通过精简推理链,减少视觉tokens的数量,仍然可以达到甚至超过现有方法的性能。关键在于找到一种更有效率的推理方式,避免不必要的计算和信息冗余。
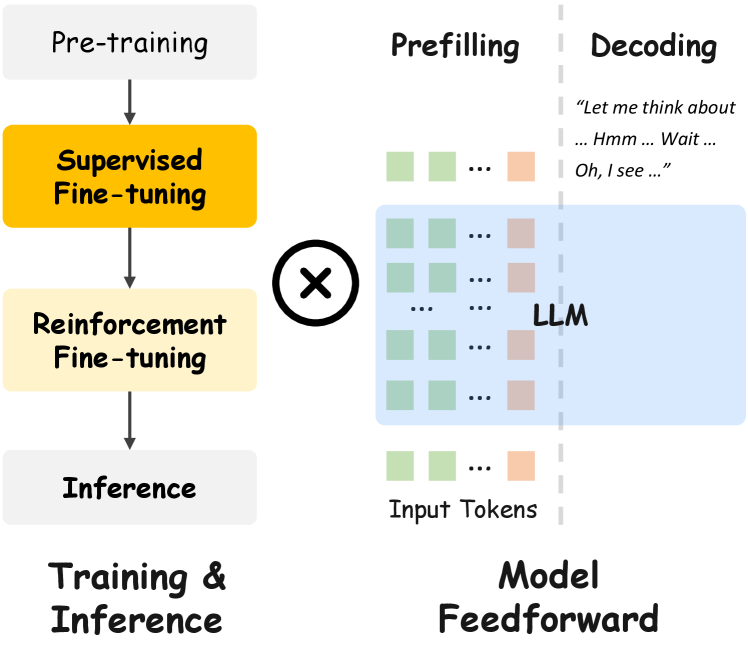
技术框架:该框架主要包含两个阶段:后训练阶段和推理阶段。在后训练阶段,模型学习如何使用压缩的视觉tokens,并生成简短的推理轨迹。在推理阶段,模型首先对输入视频进行视觉tokens压缩,然后基于压缩后的tokens生成简短的推理链,最后根据推理链给出答案。整个框架旨在减少计算量,提高推理速度。
关键创新:最重要的技术创新点在于,它挑战了传统CoT推理的必要性,证明了简洁推理在视频理解任务中的有效性。通过减少视觉tokens的数量和缩短推理链的长度,显著提高了推理效率,同时保持了甚至提升了性能。这种方法避免了对人工标注的CoT数据的依赖,也无需进行监督微调。
关键设计:论文设计了一个后训练流程,鼓励模型生成更简洁的推理轨迹。具体来说,可能涉及到对损失函数的修改,例如引入正则化项来惩罚过长的推理链。视觉tokens的压缩可能通过聚类、降维或选择关键帧等方式实现。具体的网络结构和参数设置在论文中应该有详细描述,但摘要中未提及。
🖼️ 关键图片
📊 实验亮点
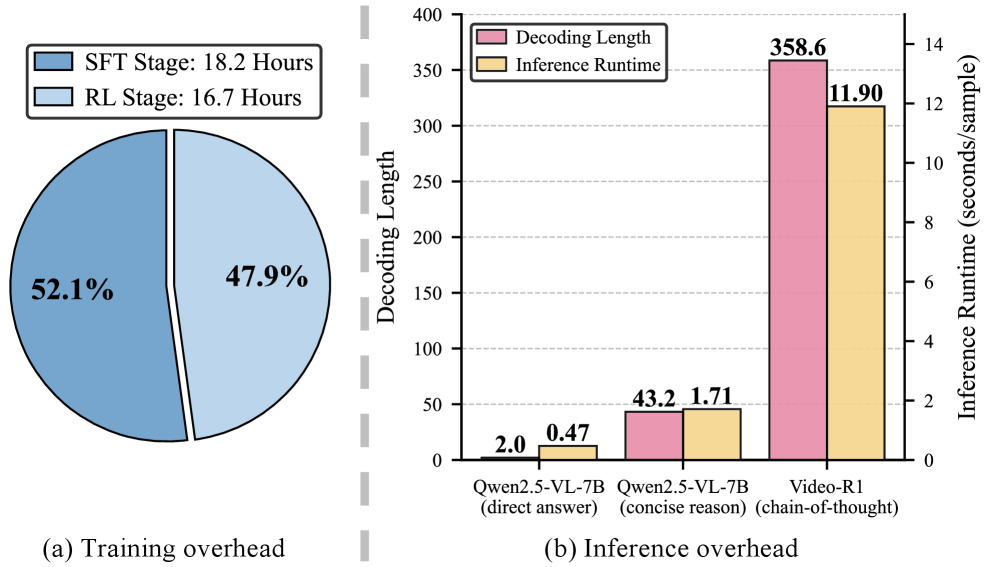
该研究表明,精简的推理链和压缩的视觉tokens足以实现高效的视频推理。实验结果显示,该框架在多个视频推理基准测试中取得了具有竞争力的性能,同时显著提高了推理效率,避免了对人工标注数据的依赖。具体的性能提升数据需要在论文中查找。
🎯 应用场景
该研究成果可应用于智能监控、视频搜索、自动驾驶等领域。通过提高视频推理的效率,可以更快地从海量视频数据中提取有价值的信息,例如快速识别异常事件、准确理解视频内容、辅助驾驶决策等。未来,该方法有望推动视频理解技术在资源受限设备上的应用,例如移动设备和嵌入式系统。
📄 摘要(原文)
Chain-of-thought (CoT) reasoning has been highly successful in solving complex tasks in natural language processing, and recent multimodal large language models (MLLMs) have extended this paradigm to video reasoning. However, these models typically build on lengthy reasoning chains and large numbers of input visual tokens. Motivated by empirical observations from our benchmark study, we hypothesize that concise reasoning combined with a reduced set of visual tokens can be sufficient for effective video reasoning. To evaluate this hypothesis, we design and validate an efficient post-training and inference framework that enhances a video MLLM's reasoning capability. Our framework enables models to operate on compressed visual tokens and generate brief reasoning traces prior to answering. The resulting models achieve substantially improved inference efficiency, deliver competitive performance across diverse benchmarks, and avoid reliance on manual CoT annotations or supervised fine-tuning. Collectively, our results suggest that long, human-like CoT reasoning may not be necessary for general video reasoning, and that concise reasoning can be both effective and efficient. Our code will be released at https://github.com/LaVi-Lab/Rethink_CoT_Video.