Selfi: Self Improving Reconstruction Engine via 3D Geometric Feature Alignment
作者: Youming Deng, Songyou Peng, Junyi Zhang, Kathryn Heal, Tiancheng Sun, John Flynn, Steve Marschner, Lucy Chai
分类: cs.CV, cs.GR
发布日期: 2025-12-09 (更新: 2025-12-21)
备注: Project Page: https://denghilbert.github.io/selfi/
💡 一句话要点
Selfi:通过3D几何特征对齐实现自提升的新视角合成引擎
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 新视角合成 3D重建 特征对齐 几何一致性 自监督学习
📋 核心要点
- 现有新视角合成方法依赖显式3D先验和精确相机参数,而视觉基础模型虽灵活但缺乏多视角几何一致性。
- Selfi通过特征对齐,将视觉基础模型VGGT转化为高保真3D重建引擎,利用自身输出作为伪真值进行自提升。
- 实验表明,Selfi在NVS和相机姿态估计任务上均达到SOTA性能,验证了特征对齐对3D推理的有效性。
📝 摘要(中文)
新视角合成(NVS)传统上依赖于具有显式3D归纳偏置的模型,并结合来自运动结构恢复(SfM)的已知相机参数。最近的视觉基础模型,如VGGT,采用了一种正交的方法——3D知识通过训练数据和损失目标隐式地获得,从而能够直接从一组未校准的图像中进行相机参数和3D表示的前馈预测。虽然VGGT具有灵活性,但其特征缺乏显式的多视角几何一致性,我们发现提高这种3D特征一致性有利于NVS和姿态估计任务。我们引入Selfi,一个通过特征对齐实现自提升的3D重建流程,通过利用VGGT自身的输出作为伪真值,将其骨干网络转换为高保真3D重建引擎。具体来说,我们使用基于重投影一致性的损失训练一个轻量级的特征适配器,将VGGT输出提炼到一个新的几何对齐特征空间,该空间捕获3D中的空间邻近性。这使得NVS和相机姿态估计都达到了最先进的性能,表明特征对齐是下游3D推理非常有益的一步。
🔬 方法详解
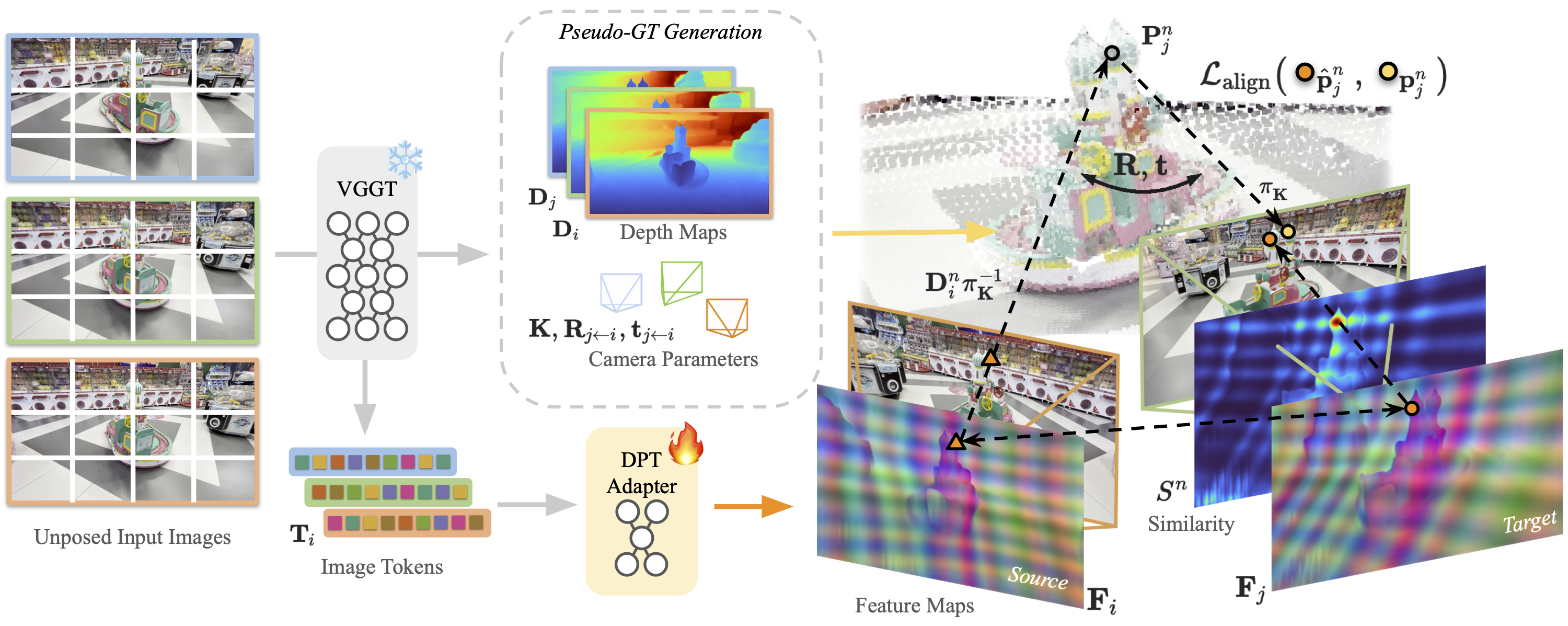
问题定义:论文旨在解决新视角合成中,现有方法对精确相机参数的依赖以及视觉基础模型缺乏多视角几何一致性的问题。现有方法要么依赖于SfM等技术预先获得精确的相机参数,限制了其应用场景;要么虽然能够直接从图像中预测相机参数和3D表示,但由于缺乏显式的几何约束,导致重建质量和姿态估计精度不高。
核心思路:论文的核心思路是利用视觉基础模型(如VGGT)的强大表征能力,并通过特征对齐的方式,显式地增强其多视角几何一致性。具体来说,就是将VGGT的输出作为伪真值,训练一个特征适配器,将原始特征映射到一个新的、几何对齐的特征空间。这样,模型就可以在没有精确相机参数的情况下,实现高保真的3D重建和精确的姿态估计。
技术框架:Selfi的整体框架包含以下几个主要步骤:1) 使用VGGT等视觉基础模型从输入图像中提取特征;2) 使用一个轻量级的特征适配器,将这些特征映射到一个新的特征空间,该空间具有更好的几何一致性;3) 使用重投影一致性损失,训练特征适配器,使其输出的特征能够更好地反映3D空间中的几何关系;4) 使用对齐后的特征进行新视角合成和相机姿态估计。
关键创新:论文的关键创新在于提出了一个自提升的3D重建流程,通过特征对齐的方式,将视觉基础模型转化为高保真3D重建引擎。与现有方法相比,Selfi不需要预先知道精确的相机参数,也不需要复杂的3D建模过程,而是通过学习的方式,显式地增强了特征的几何一致性,从而提高了重建质量和姿态估计精度。
关键设计:Selfi的关键设计包括:1) 特征适配器的网络结构,需要足够轻量级,以保证训练效率;2) 重投影一致性损失的设计,需要能够有效地约束特征的几何一致性;3) 训练策略,如何有效地利用VGGT的输出作为伪真值,训练特征适配器。具体而言,特征适配器可以使用简单的MLP结构,重投影一致性损失可以使用L1或L2损失,训练策略可以使用自监督学习的方式。
🖼️ 关键图片


📊 实验亮点
Selfi在NVS和相机姿态估计任务上均取得了显著的性能提升。例如,在NVS任务上,Selfi相比于VGGT等基线方法,在PSNR、SSIM等指标上均有明显提升。在相机姿态估计任务上,Selfi的姿态估计精度也显著高于其他方法,证明了特征对齐的有效性。
🎯 应用场景
Selfi在机器人导航、自动驾驶、增强现实等领域具有广泛的应用前景。它可以用于在未知环境中进行3D重建和姿态估计,从而实现自主导航和环境感知。此外,Selfi还可以用于生成逼真的虚拟场景,为用户提供沉浸式的AR/VR体验。未来,Selfi有望成为各种3D视觉应用的基础技术。
📄 摘要(原文)
Novel View Synthesis (NVS) has traditionally relied on models with explicit 3D inductive biases combined with known camera parameters from Structure-from-Motion (SfM) beforehand. Recent vision foundation models like VGGT take an orthogonal approach -- 3D knowledge is gained implicitly through training data and loss objectives, enabling feed-forward prediction of both camera parameters and 3D representations directly from a set of uncalibrated images. While flexible, VGGT features lack explicit multi-view geometric consistency, and we find that improving such 3D feature consistency benefits both NVS and pose estimation tasks. We introduce Selfi, a self-improving 3D reconstruction pipeline via feature alignment, transforming a VGGT backbone into a high-fidelity 3D reconstruction engine by leveraging its own outputs as pseudo-ground-truth. Specifically, we train a lightweight feature adapter using a reprojection-based consistency loss, which distills VGGT outputs into a new geometrically-aligned feature space that captures spatial proximity in 3D. This enables state-of-the-art performance in both NVS and camera pose estimation, demonstrating that feature alignment is a highly beneficial step for downstream 3D reasoning.