Beyond Real Weights: Hypercomplex Representations for Stable Quantization
作者: Jawad Ibn Ahad, Maisha Rahman, Amrijit Biswas, Muhammad Rafsan Kabir, Robin Krambroeckers, Sifat Momen, Nabeel Mohammed, Shafin Rahman
分类: cs.CV, cs.CL
发布日期: 2025-12-09
备注: Accepted in Winter Conference on Applications of Computer Vision (WACV) 2026
💡 一句话要点
提出基于超复数表示的渐进式重参数化方法,实现多模态大模型的高效量化。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 模型压缩 超复数表示 参数化乘法 知识蒸馏
📋 核心要点
- 多模态大模型参数量巨大,部署困难,需要高效的压缩方法。
- 论文提出渐进式重参数化策略,用参数化超复数乘法(PHM)层逐步替换密集层。
- 实验表明,该方法在显著减少参数和FLOP的同时,保持了与基线模型相当的性能。
📝 摘要(中文)
多模态语言模型(MLLM)需要大量的参数来对齐高维视觉特征和语言表示,这使得它们计算量大且难以高效部署。本文提出了一种渐进式重参数化策略,通过逐步用紧凑的参数化超复数乘法(PHM)层替换密集前馈网络块来压缩这些模型。残差插值计划,以及轻量级的重建和知识蒸馏损失,确保PHM模块在训练期间继承其密集对应物的功能行为。这种转换在保持强大的多模态对齐的同时,显著减少了参数和FLOP,从而在不降低输出质量的情况下实现更快的推理。我们在多个视觉语言模型(VLM)上评估了该方法。我们的方法保持了与基础模型相当的性能,同时显著减少了模型大小和推理延迟。因此,渐进式PHM替换为更高效的多模态推理提供了一条架构兼容的路径,并补充了现有的低比特量化技术。
🔬 方法详解
问题定义:多模态语言模型(MLLMs)为了对齐高维视觉特征和语言表示,需要大量的参数,导致模型体积庞大,计算复杂度高,难以高效部署。现有的量化方法虽然可以减小模型体积,但通常会带来性能下降。因此,如何在保证性能的前提下,有效压缩多模态大模型是一个重要的挑战。
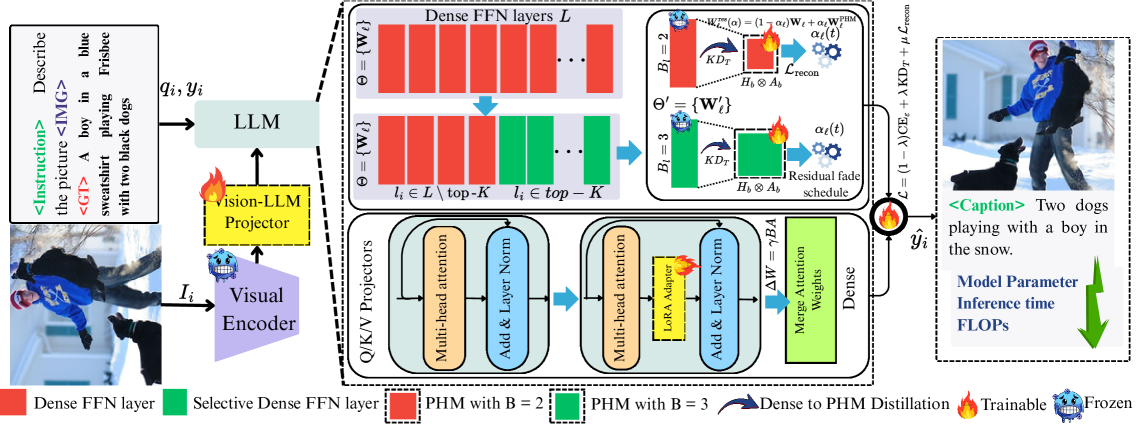
核心思路:论文的核心思路是利用参数化超复数乘法(Parameterized Hypercomplex Multiplication, PHM)层来替代传统的密集前馈网络层。PHM层具有更少的参数量,从而可以有效压缩模型。通过渐进式地替换密集层,并结合残差插值、重建损失和知识蒸馏等技术,保证PHM模块可以学习到密集层的功能,从而在压缩模型的同时保持性能。
技术框架:整体框架包含以下几个主要步骤:1) 渐进式替换:从模型的浅层开始,逐步用PHM层替换密集前馈网络层。2) 残差插值:在PHM层的输出和原始密集层的输出之间进行残差连接,以保证信息的平滑过渡。3) 重建损失:使用重建损失来约束PHM层的输出,使其尽可能接近原始密集层的输出。4) 知识蒸馏:使用知识蒸馏技术,将原始密集模型的知识迁移到压缩后的模型中。
关键创新:最重要的技术创新点在于使用超复数表示来压缩模型。与传统的实数表示相比,超复数表示可以更紧凑地表示高维数据,从而减少参数量。此外,渐进式替换策略和残差插值技术也保证了模型压缩过程的稳定性,避免了性能的急剧下降。
关键设计:1) PHM层结构:PHM层使用超复数矩阵进行乘法运算,具体结构未知,但关键在于其参数量远小于等价的密集层。2) 残差插值系数:残差插值系数控制了PHM层输出和原始密集层输出的融合比例,需要仔细调整。3) 重建损失函数:重建损失函数用于衡量PHM层输出和原始密集层输出之间的差异,常用的损失函数包括L1损失和L2损失。4) 知识蒸馏损失函数:知识蒸馏损失函数用于衡量压缩后模型的输出和原始模型的输出之间的差异,常用的损失函数包括KL散度。
🖼️ 关键图片

📊 实验亮点
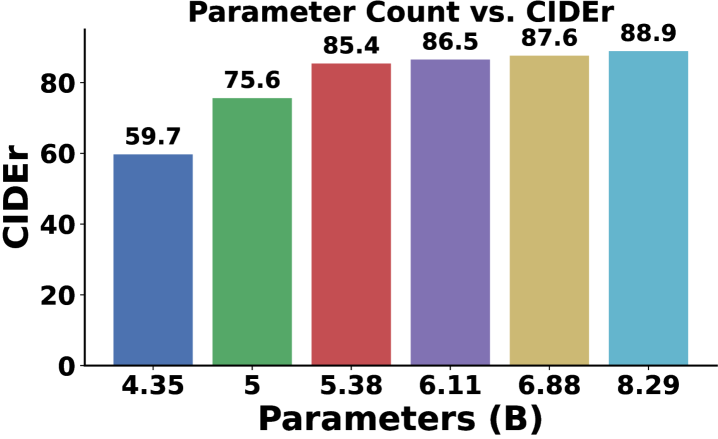
实验结果表明,该方法可以在保持与基线模型相当的性能的同时,显著减少模型大小和推理延迟。具体的性能数据未知,但摘要中强调了“significant reductions in model size and inference latency”,表明压缩效果显著。该方法在多个视觉语言模型(VLMs)上进行了评估,证明了其通用性。
🎯 应用场景
该研究成果可应用于各种需要高效部署的多模态语言模型,例如移动设备上的视觉问答、图像字幕生成等。通过减小模型体积和降低计算复杂度,可以使这些模型在资源受限的环境中运行,从而扩展其应用范围。此外,该方法还可以作为一种通用的模型压缩技术,应用于其他类型的深度学习模型。
📄 摘要(原文)
Multimodal language models (MLLMs) require large parameter capacity to align high-dimensional visual features with linguistic representations, making them computationally heavy and difficult to deploy efficiently. We introduce a progressive reparameterization strategy that compresses these models by gradually replacing dense feed-forward network blocks with compact Parameterized Hypercomplex Multiplication (PHM) layers. A residual interpolation schedule, together with lightweight reconstruction and knowledge distillation losses, ensures that the PHM modules inherit the functional behavior of their dense counterparts during training. This transition yields substantial parameter and FLOP reductions while preserving strong multimodal alignment, enabling faster inference without degrading output quality. We evaluate the approach on multiple vision-language models (VLMs). Our method maintains performance comparable to the base models while delivering significant reductions in model size and inference latency. Progressive PHM substitution thus offers an architecture-compatible path toward more efficient multimodal reasoning and complements existing low-bit quantization techniques.