Lang3D-XL: Language Embedded 3D Gaussians for Large-scale Scenes
作者: Shai Krakovsky, Gal Fiebelman, Sagie Benaim, Hadar Averbuch-Elor
分类: cs.CV, cs.GR
发布日期: 2025-12-08
备注: Accepted to SIGGRAPH Asia 2025. Project webpage: https://tau-vailab.github.io/Lang3D-XL
💡 一句话要点
Lang3D-XL:通过语言嵌入3D高斯模型实现大规模场景的语义理解
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D高斯模型 语言嵌入 大规模场景 语义理解 特征蒸馏
📋 核心要点
- 现有方法在大规模场景下进行语言嵌入3D表示时,面临语义特征不对齐和效率低下的挑战。
- 论文提出利用低维语义瓶颈特征和衰减下采样模块,结合正则化方法,解决语义不对齐和效率问题。
- 实验表明,提出的Lang3D-XL方法在性能和效率上均优于现有方法,尤其是在大规模场景下。
📝 摘要(中文)
本文提出了一种将语言场嵌入3D表示的方法,旨在通过将几何结构与描述性语义联系起来,从而实现对空间环境更丰富的语义理解。这种方法能够实现更直观的人机交互,支持使用自然语言查询或编辑场景,并有可能改进场景检索、导航和多模态推理等任务。针对大规模场景下现有特征蒸馏方法在语义特征不对齐以及内存和运行时效率方面的挑战,本文提出了一种新颖的方法。该方法引入了极低维的语义瓶颈特征作为底层3D高斯表示的一部分,并通过渲染和多分辨率、基于特征的哈希编码器处理这些特征,从而显著提高运行时和GPU内存的效率。此外,本文还引入了一个衰减下采样模块,并提出了几种正则化方法,以解决ground truth 2D特征的语义不对齐问题。在真实场景数据集HolyScenes上的评估表明,该方法在性能和效率方面均优于现有方法。
🔬 方法详解
问题定义:现有方法在处理大规模场景时,由于互联网数据的复杂性和规模,容易出现语义特征不对齐的问题,导致语言嵌入3D表示的效果不佳。同时,现有方法在内存和运行时效率方面存在瓶颈,难以应用于大规模场景。
核心思路:论文的核心思路是通过引入低维语义瓶颈特征来压缩语义信息,并利用多分辨率哈希编码器来提高效率。此外,通过衰减下采样模块和正则化方法来解决语义不对齐问题,从而提升整体性能。
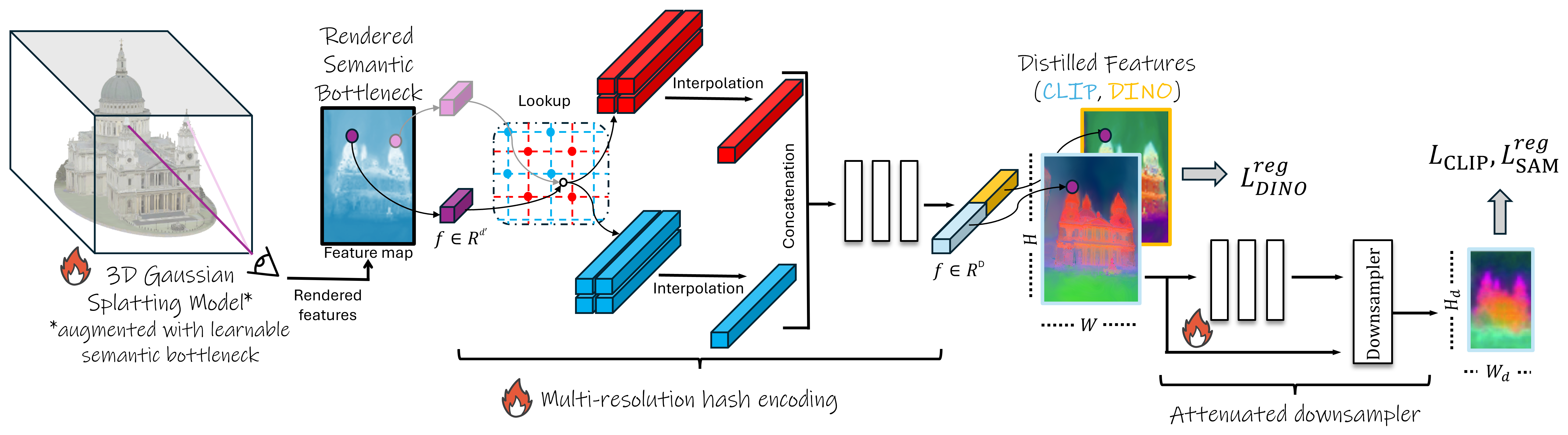
技术框架:Lang3D-XL的整体框架包括以下几个主要模块:1) 3D高斯表示:使用3D高斯模型来表示场景的几何结构。2) 语义瓶颈特征:将语言信息嵌入到低维语义瓶颈特征中。3) 多分辨率哈希编码器:通过渲染语义瓶颈特征,并使用多分辨率哈希编码器进行处理,提高效率。4) 衰减下采样模块:用于解决语义不对齐问题。5) 正则化:引入多种正则化方法,进一步提升性能。
关键创新:该方法最重要的创新点在于引入了极低维的语义瓶颈特征,并结合多分辨率哈希编码器,显著提高了大规模场景下的效率。同时,衰减下采样模块和正则化方法有效地解决了语义不对齐问题。
关键设计:语义瓶颈特征的维度需要仔细选择,以在信息压缩和表达能力之间取得平衡。多分辨率哈希编码器的具体结构和参数设置需要根据数据集进行调整。衰减下采样模块的设计需要考虑如何有效地减少语义不对齐的影响。损失函数的设计需要综合考虑几何重建、语义一致性和效率等因素。
🖼️ 关键图片


📊 实验亮点
Lang3D-XL在HolyScenes数据集上取得了显著的性能提升,超越了现有的特征蒸馏方法。实验结果表明,该方法在保持较高语义理解能力的同时,显著降低了内存占用和运行时间,使其能够有效地应用于大规模场景。具体的性能数据和提升幅度在论文中有详细展示。
🎯 应用场景
该研究成果可应用于虚拟现实、增强现实、机器人导航、场景理解和三维场景编辑等领域。通过自然语言交互,用户可以更方便地查询、编辑和理解三维场景,从而提高人机交互的效率和体验。该技术还有潜力应用于自动驾驶、智能家居等领域,实现更智能化的环境感知和交互。
📄 摘要(原文)
Embedding a language field in a 3D representation enables richer semantic understanding of spatial environments by linking geometry with descriptive meaning. This allows for a more intuitive human-computer interaction, enabling querying or editing scenes using natural language, and could potentially improve tasks like scene retrieval, navigation, and multimodal reasoning. While such capabilities could be transformative, in particular for large-scale scenes, we find that recent feature distillation approaches cannot effectively learn over massive Internet data due to challenges in semantic feature misalignment and inefficiency in memory and runtime. To this end, we propose a novel approach to address these challenges. First, we introduce extremely low-dimensional semantic bottleneck features as part of the underlying 3D Gaussian representation. These are processed by rendering and passing them through a multi-resolution, feature-based, hash encoder. This significantly improves efficiency both in runtime and GPU memory. Second, we introduce an Attenuated Downsampler module and propose several regularizations addressing the semantic misalignment of ground truth 2D features. We evaluate our method on the in-the-wild HolyScenes dataset and demonstrate that it surpasses existing approaches in both performance and efficiency.