Less Is More, but Where? Dynamic Token Compression via LLM-Guided Keyframe Prior
作者: Yulin Li, Haokun Gui, Ziyang Fan, Junjie Wang, Bin Kang, Bin Chen, Zhuotao Tian
分类: cs.CV, cs.AI, cs.CL, cs.LG
发布日期: 2025-12-07
备注: Accepted by NeurIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出DyToK以解决长视频理解中的动态令牌压缩问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长视频理解 动态令牌压缩 视频大型语言模型 关键帧选择 效率优化
📋 核心要点
- 现有视频理解方法在处理长视频时面临计算复杂度高的问题,导致效率低下。
- DyToK通过利用VLLMs的注意力机制,实现动态令牌压缩,优化关键帧的选择与保留。
- 实验结果显示,DyToK在多个VLLMs上实现了4.3倍的推理速度提升,同时保持了准确性。
📝 摘要(中文)
近年来,视频大型语言模型(VLLMs)在视频理解方面取得了显著进展,但由于长视频的视觉令牌序列导致的计算复杂度呈二次增长,效率面临瓶颈。现有的关键帧采样方法虽然能提高时间建模效率,但在特征编码前引入了额外的计算成本,且二进制帧选择范式被发现并不理想。因此,本文提出了一种基于VLLMs固有注意力机制的动态令牌压缩方法DyToK,能够动态调整每帧的令牌保留比例,优先保留语义丰富的帧,同时抑制冗余。大量实验表明,DyToK在效率与准确性之间达到了最先进的平衡,并与现有压缩方法兼容,显著提升推理速度。
🔬 方法详解
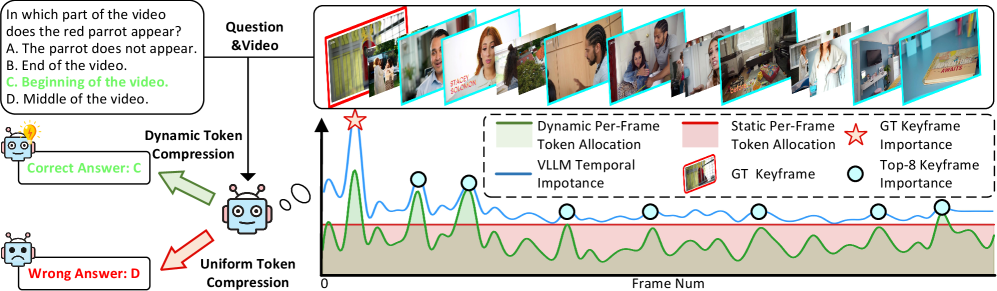
问题定义:本文旨在解决长视频理解中由于视觉令牌序列过长而导致的计算复杂度高的问题。现有的关键帧采样方法虽然提高了时间建模效率,但在特征编码前增加了计算成本,且二进制帧选择方法并不理想。
核心思路:DyToK的核心思想是利用VLLMs的注意力机制,动态调整每帧的令牌保留比例,优先选择语义丰富的帧,从而实现高效的动态令牌压缩。这样的设计可以有效减少冗余信息,提高模型的处理效率。
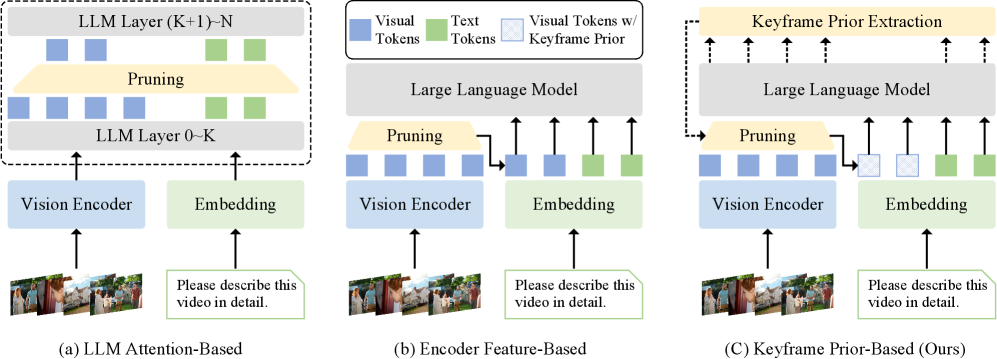
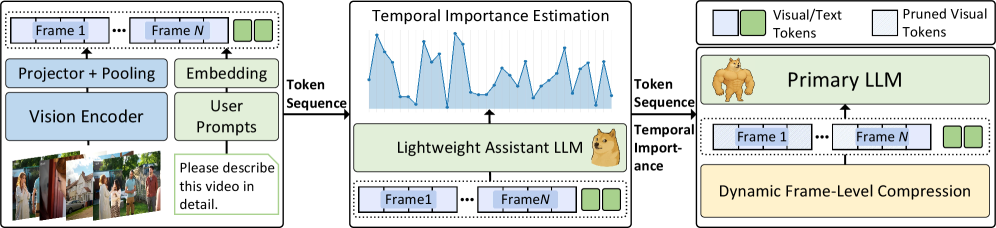
技术框架:DyToK的整体架构包括输入视频的关键帧提取、基于VLLM的注意力机制分析、动态令牌选择与压缩等主要模块。通过这些模块,DyToK能够在不需要额外训练的情况下,实时调整令牌的保留策略。
关键创新:DyToK的主要创新在于其训练自由的动态令牌压缩机制,利用VLLM的注意力层自然编码的查询条件关键帧先验,实现了对每帧令牌的动态调整。这一方法与现有的静态关键帧选择方法本质上不同,能够更灵活地应对视频内容的变化。
关键设计:DyToK在参数设置上,采用了基于语义信息的动态令牌保留比例,并设计了适应性损失函数以优化关键帧的选择。网络结构上,DyToK与现有的压缩方法如VisionZip和FastV兼容,确保了其在实际应用中的灵活性。
🖼️ 关键图片
📊 实验亮点
DyToK在多个VLLMs上实现了4.3倍的推理速度提升,同时保持了准确性,展示了其在效率与准确性之间的优越平衡。与现有压缩方法相比,DyToK在动态令牌选择上表现出更高的灵活性和适应性,进一步推动了视频理解技术的发展。
🎯 应用场景
DyToK的研究成果在视频理解、视频检索和多媒体内容分析等领域具有广泛的应用潜力。通过提高长视频处理的效率,该方法能够为实时视频分析、智能监控和自动内容生成等场景提供支持,推动相关技术的发展与应用。
📄 摘要(原文)
Recent advances in Video Large Language Models (VLLMs) have achieved remarkable video understanding capabilities, yet face critical efficiency bottlenecks due to quadratic computational growth with lengthy visual token sequences of long videos. While existing keyframe sampling methods can improve temporal modeling efficiency, additional computational cost is introduced before feature encoding, and the binary frame selection paradigm is found suboptimal. Therefore, in this work, we propose Dynamic Token compression via LLM-guided Keyframe prior (DyToK), a training-free paradigm that enables dynamic token compression by harnessing VLLMs' inherent attention mechanisms. Our analysis reveals that VLLM attention layers naturally encoding query-conditioned keyframe priors, by which DyToK dynamically adjusts per-frame token retention ratios, prioritizing semantically rich frames while suppressing redundancies. Extensive experiments demonstrate that DyToK achieves state-of-the-art efficiency-accuracy tradeoffs. DyToK shows plug-and-play compatibility with existing compression methods, such as VisionZip and FastV, attaining 4.3x faster inference while preserving accuracy across multiple VLLMs, such as LLaVA-OneVision and Qwen2.5-VL. Code is available at https://github.com/yu-lin-li/DyToK .