Boosting Unsupervised Video Instance Segmentation with Automatic Quality-Guided Self-Training
作者: Kaixuan Lu, Mehmet Onurcan Kaya, Dim P. Papadopoulos
分类: cs.CV
发布日期: 2025-12-07
备注: Accepted to WACV 2026. arXiv admin note: substantial text overlap with arXiv:2508.19808
🔗 代码/项目: GITHUB
💡 一句话要点
AutoQ-VIS:基于质量引导自训练提升无监督视频实例分割性能
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视频实例分割 无监督学习 自训练 质量评估 域适应
📋 核心要点
- 视频实例分割标注成本高昂,现有无监督方法受限于合成数据与真实数据之间的域差距。
- AutoQ-VIS通过质量引导的自训练,建立伪标签生成与质量评估的闭环,实现从合成到真实的逐步适应。
- 实验表明,AutoQ-VIS在YouTubeVIS-2019验证集上超越现有最优方法4.4%,验证了质量感知自训练的有效性。
📝 摘要(中文)
视频实例分割(VIS)由于需要像素级掩码和时间一致性标签,面临着巨大的标注挑战。最近的无监督方法,如VideoCutLER,通过合成数据消除了对光流的依赖,但仍然受到合成到真实域差距的限制。我们提出了AutoQ-VIS,一种新颖的无监督框架,通过质量引导的自训练来弥合这一差距。我们的方法在伪标签生成和自动质量评估之间建立了一个闭环系统,从而能够从合成视频逐步适应到真实视频。实验表明,在YouTubeVIS-2019 $ exttt{val}$ 集上,我们的方法达到了52.6 $ ext{AP}_{50}$ 的最先进性能,超过了之前的最先进方法VideoCutLER 4.4%,且无需人工标注。这证明了质量感知的自训练对于无监督VIS的可行性。
🔬 方法详解
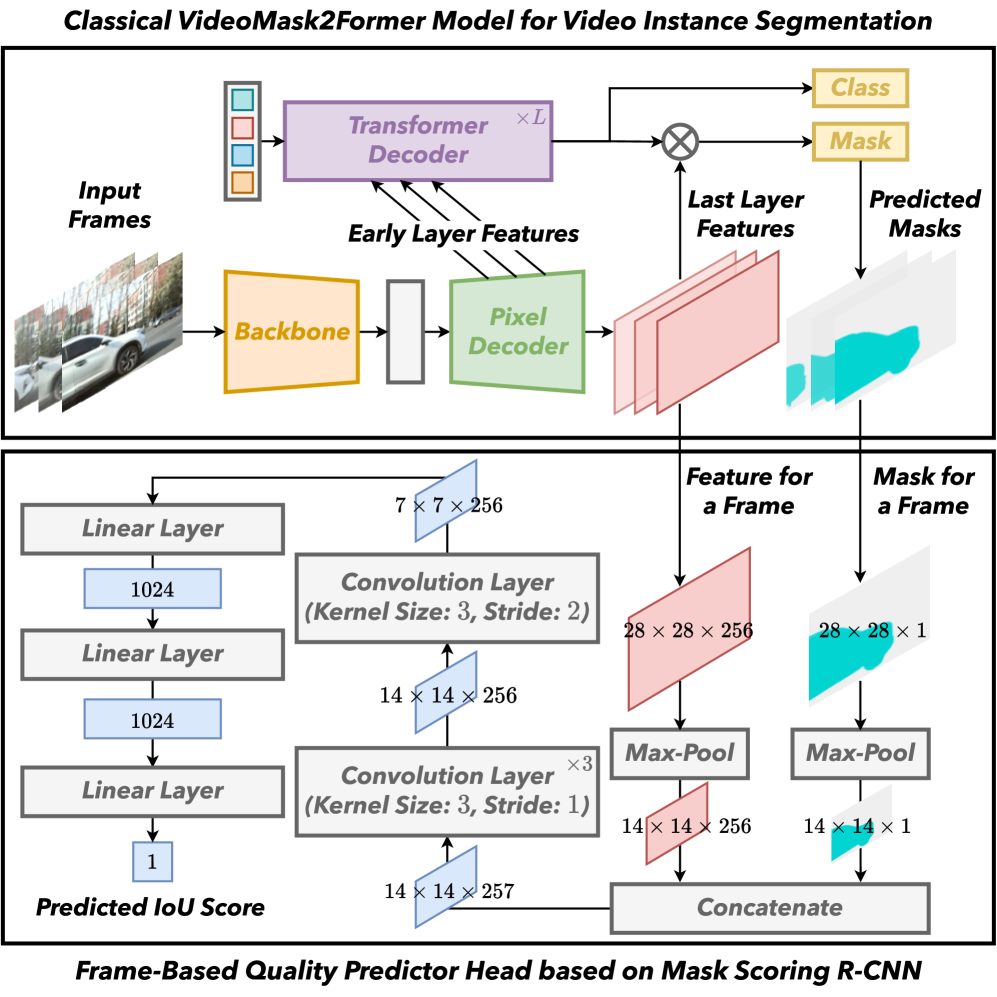
问题定义:论文旨在解决无监督视频实例分割问题,即在没有人工标注的情况下,对视频中的每个实例进行像素级别的分割和跟踪。现有方法,如VideoCutLER,虽然利用合成数据避免了对光流的依赖,但由于合成数据与真实数据存在域差距,导致性能受限。
核心思路:论文的核心思路是利用自训练的方式,逐步将模型从合成数据迁移到真实数据。通过自动评估伪标签的质量,并以此指导模型的训练,从而减小域差距,提高分割精度。关键在于建立一个伪标签生成和质量评估的闭环系统。
技术框架:AutoQ-VIS框架包含以下主要模块:1) 伪标签生成模块:利用在合成数据上预训练的模型,对真实视频生成伪标签。2) 质量评估模块:自动评估生成的伪标签的质量,例如通过一致性检查、置信度评分等方式。3) 自训练模块:利用高质量的伪标签对模型进行训练,并不断迭代更新模型参数。整个过程形成一个闭环,模型在真实数据上不断优化。
关键创新:最重要的技术创新点在于自动质量评估机制。传统自训练方法通常直接使用所有伪标签,而AutoQ-VIS能够自动识别并过滤掉低质量的伪标签,从而避免引入噪声,提高训练效率和模型性能。这种质量感知的自训练是本文的核心贡献。
关键设计:具体的质量评估方法可能包括:1) 基于实例分割结果的置信度评分,例如利用分割头的输出概率。2) 基于时间一致性的评估,例如比较相邻帧之间分割结果的一致性。3) 基于几何约束的评估,例如利用实例的形状和大小信息。损失函数的设计也至关重要,可能包括分割损失、一致性损失等,以保证分割精度和时间一致性。
🖼️ 关键图片


📊 实验亮点
AutoQ-VIS在YouTubeVIS-2019验证集上取得了显著的性能提升,达到了52.6 $ ext{AP}_{50}$,超过了之前的state-of-the-art方法VideoCutLER 4.4%。这一结果表明,质量引导的自训练是提升无监督视频实例分割性能的有效途径,并且无需任何人工标注。
🎯 应用场景
AutoQ-VIS在视频监控、自动驾驶、机器人导航等领域具有广泛的应用前景。它可以帮助机器自动理解视频内容,识别和跟踪视频中的目标,从而实现智能化的视频分析和决策。该研究降低了视频实例分割对人工标注的依赖,为大规模视频数据的处理提供了可能。
📄 摘要(原文)
Video Instance Segmentation (VIS) faces significant annotation challenges due to its dual requirements of pixel-level masks and temporal consistency labels. While recent unsupervised methods like VideoCutLER eliminate optical flow dependencies through synthetic data, they remain constrained by the synthetic-to-real domain gap. We present AutoQ-VIS, a novel unsupervised framework that bridges this gap through quality-guided self-training. Our approach establishes a closed-loop system between pseudo-label generation and automatic quality assessment, enabling progressive adaptation from synthetic to real videos. Experiments demonstrate state-of-the-art performance with 52.6 $\text{AP}_{50}$ on YouTubeVIS-2019 $\texttt{val}$ set, surpassing the previous state-of-the-art VideoCutLER by 4.4%, while requiring no human annotations. This demonstrates the viability of quality-aware self-training for unsupervised VIS. We will release the code at https://github.com/wcbup/AutoQ-VIS.