Pseudo Anomalies Are All You Need: Diffusion-Based Generation for Weakly-Supervised Video Anomaly Detection
作者: Satoshi Hashimoto, Hitoshi Nishimura, Yanan Wang, Mori Kurokawa
分类: cs.CV
发布日期: 2025-12-07
💡 一句话要点
提出PA-VAD,利用扩散模型生成伪异常视频,解决弱监督视频异常检测中异常数据稀缺问题。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 视频异常检测 弱监督学习 扩散模型 伪异常生成 域对齐
📋 核心要点
- 真实异常视频数据稀缺且收集成本高昂,限制了视频异常检测在实际场景中的应用。
- 利用扩散模型生成伪异常视频,结合真实正常视频训练异常检测器,无需真实异常数据。
- 在ShanghaiTech和UCF-Crime数据集上取得了显著的性能提升,验证了该方法的有效性。
📝 摘要(中文)
本文旨在解决视频异常检测中真实异常视频数据稀缺且收集成本高昂的问题。作者提出了一种名为PA-VAD的生成驱动方法,该方法无需任何真实异常视频进行训练,而是在标准的弱监督设置下进行评估。PA-VAD利用少量真实正常图像驱动合成伪异常视频,并将其与真实正常视频配对,从而训练异常检测器。在合成方面,该方法使用CLIP选择与类别相关的初始图像,并通过视觉-语言模型优化文本提示,以提高保真度和场景一致性,然后调用视频扩散模型。在训练方面,通过一个域对齐正则化模块来缓解合成异常中过度的时空幅度,该模块结合了域对齐和内存使用感知更新。大量实验表明,该方法在ShanghaiTech数据集上达到98.2%,在UCF-Crime数据集上达到82.5%,超过了ShanghaiTech上最强的真实异常方法+0.6%,并且在UCF-Crime上优于UVAD最先进水平+1.9%。结果表明,无需收集真实异常即可获得高精度的异常检测,为可扩展部署提供了一条实用途径。
🔬 方法详解
问题定义:视频异常检测任务旨在识别视频中不寻常的事件。现有的方法通常依赖于大量的标注数据,特别是异常数据的标注。然而,在实际应用中,异常数据往往难以获取,且标注成本高昂。因此,如何在缺乏异常数据的情况下进行有效的异常检测是一个重要的挑战。
核心思路:本文的核心思路是利用扩散模型生成伪异常视频,从而缓解异常数据稀缺的问题。通过将生成的伪异常视频与真实正常视频结合,可以训练出一个能够区分正常和异常事件的异常检测器。这种方法避免了对真实异常数据的依赖,降低了数据收集和标注的成本。
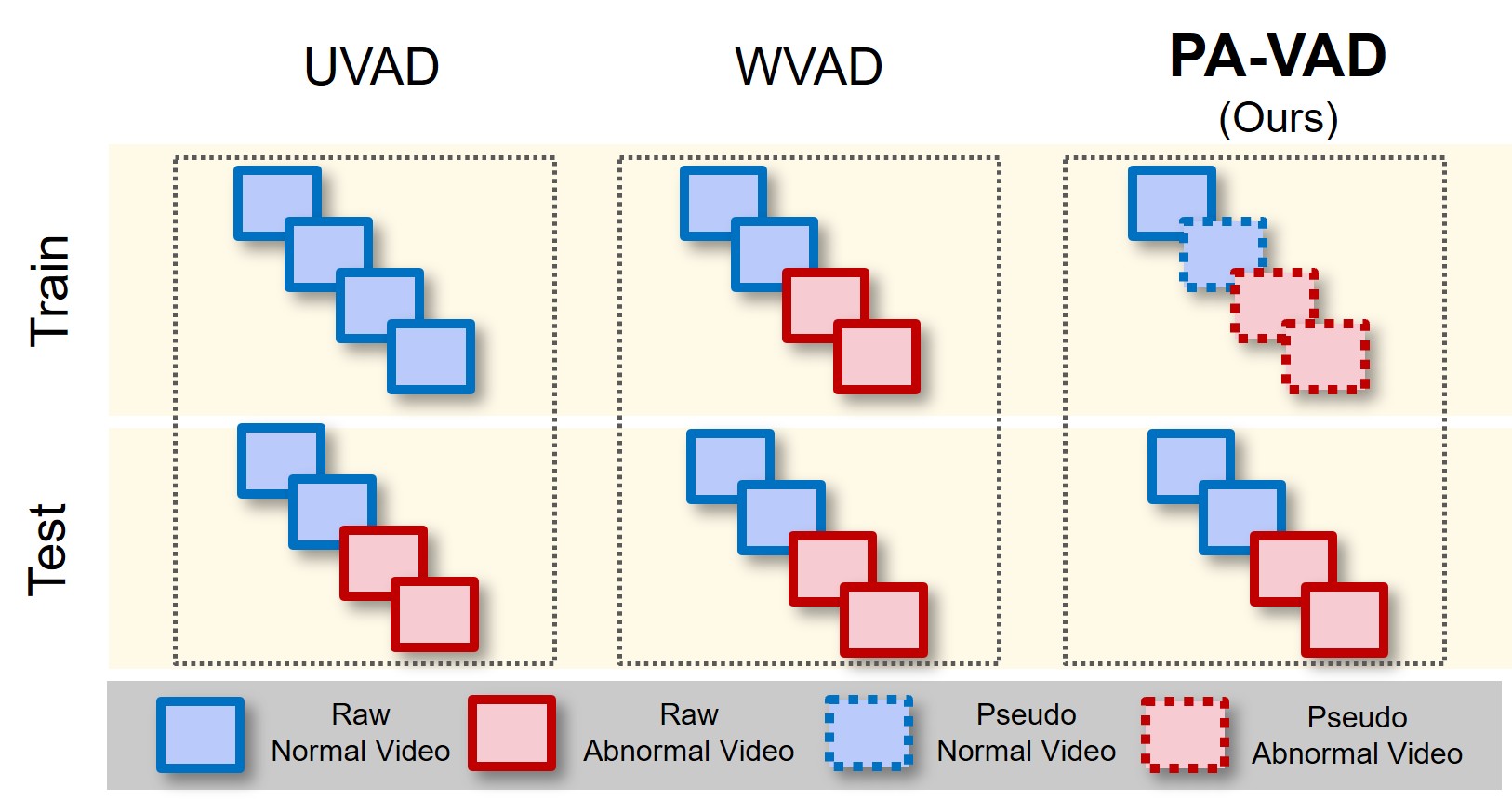
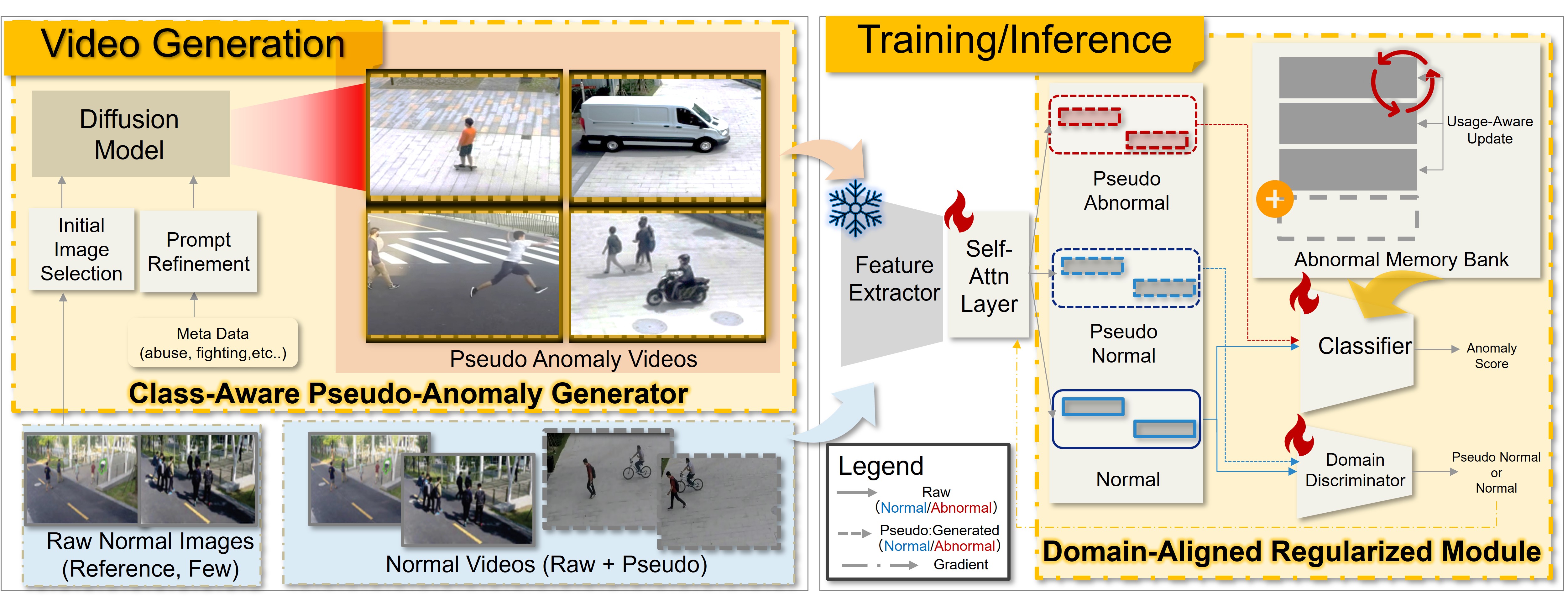
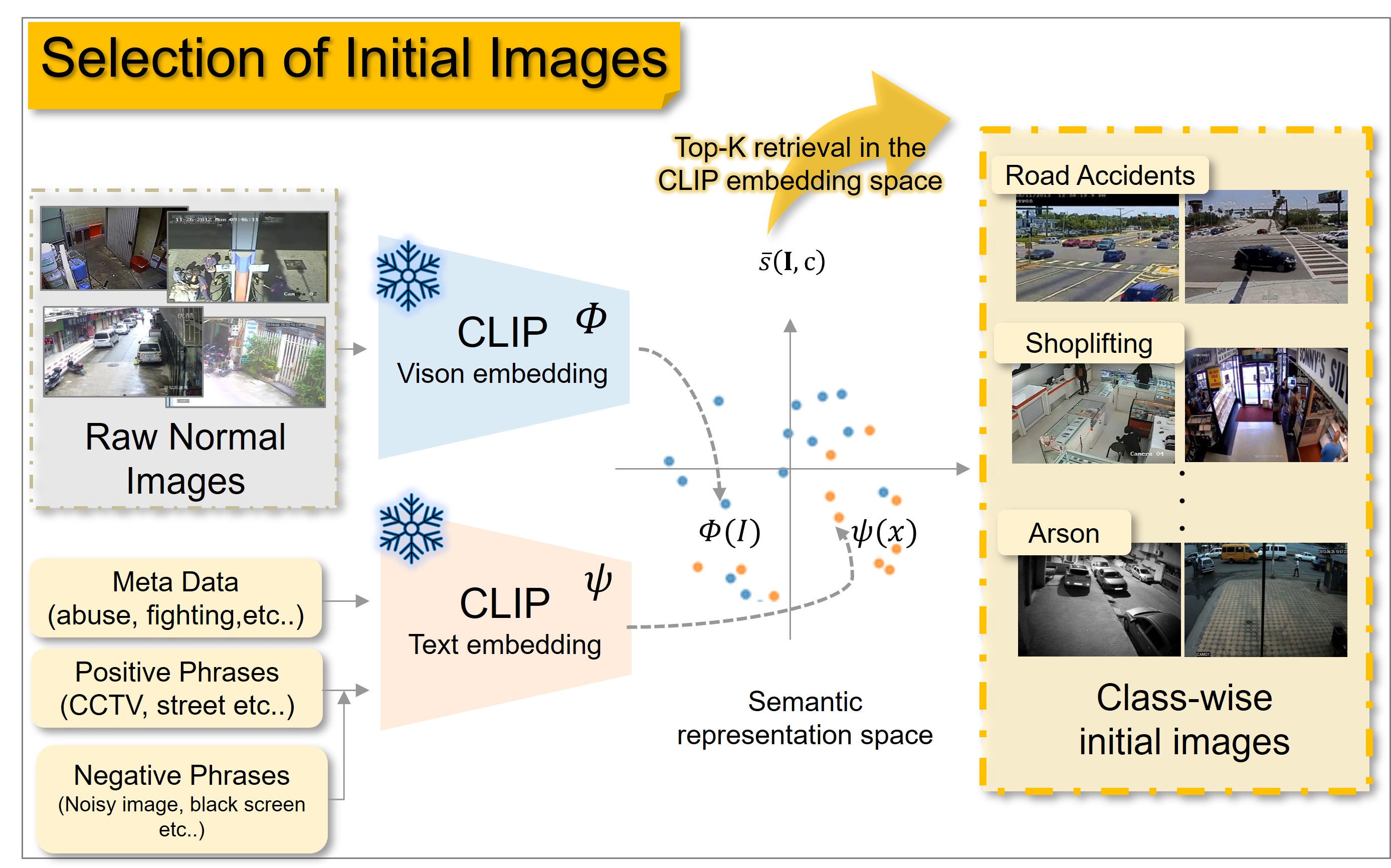
技术框架:PA-VAD方法的整体框架包括三个主要阶段:1) 伪异常视频生成:首先,使用CLIP模型选择与类别相关的初始图像,然后利用视觉-语言模型优化文本提示,最后使用视频扩散模型生成伪异常视频。2) 异常检测器训练:将生成的伪异常视频与真实正常视频配对,用于训练异常检测器。3) 域对齐正则化:为了缓解合成异常中过度的时空幅度,引入了一个域对齐正则化模块,该模块结合了域对齐和内存使用感知更新。
关键创新:该方法最重要的技术创新点在于利用扩散模型生成高质量的伪异常视频。通过CLIP和视觉-语言模型的辅助,可以生成与真实场景更加一致的异常视频,从而提高异常检测器的性能。与现有方法相比,该方法无需任何真实异常数据,降低了数据依赖性。
关键设计:在伪异常视频生成阶段,CLIP模型用于选择与类别相关的初始图像,确保生成的异常事件与场景相关。视觉-语言模型用于优化文本提示,提高生成视频的保真度和场景一致性。域对齐正则化模块通过最小化真实正常视频和伪异常视频之间的域差异,缓解合成异常中过度的时空幅度。内存使用感知更新策略用于优化训练过程,提高训练效率。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PA-VAD方法在ShanghaiTech数据集上达到了98.2%的AUC,超过了最强的真实异常方法+0.6%。在UCF-Crime数据集上,PA-VAD达到了82.5%的AUC,优于UVAD最先进水平+1.9%。这些结果表明,该方法在无需真实异常数据的情况下,能够实现高精度的视频异常检测。
🎯 应用场景
该研究成果可广泛应用于智能监控、工业安全、医疗诊断等领域。例如,在智能监控中,可以用于检测异常行为,如打架、盗窃等;在工业安全中,可以用于检测设备故障或操作失误;在医疗诊断中,可以用于检测医学影像中的异常病灶。该方法降低了对异常数据的依赖,为大规模部署视频异常检测系统提供了可能。
📄 摘要(原文)
Deploying video anomaly detection in practice is hampered by the scarcity and collection cost of real abnormal footage. We address this by training without any real abnormal videos while evaluating under the standard weakly supervised split, and we introduce PA-VAD, a generation-driven approach that learns a detector from synthesized pseudo-abnormal videos paired with real normal videos, using only a small set of real normal images to drive synthesis. For synthesis, we select class-relevant initial images with CLIP and refine textual prompts with a vision-language model to improve fidelity and scene consistency before invoking a video diffusion model. For training, we mitigate excessive spatiotemporal magnitude in synthesized anomalies by an domain-aligned regularized module that combines domain alignment and memory usage-aware updates. Extensive experiments show that our approach reaches 98.2% on ShanghaiTech and 82.5% on UCF-Crime, surpassing the strongest real-abnormal method on ShanghaiTech by +0.6% and outperforming the UVAD state-of-the-art on UCF-Crime by +1.9%. The results demonstrate that high-accuracy anomaly detection can be obtained without collecting real anomalies, providing a practical path toward scalable deployment.