MMDuet2: Enhancing Proactive Interaction of Video MLLMs with Multi-Turn Reinforcement Learning
作者: Yueqian Wang, Songxiang Liu, Disong Wang, Nuo Xu, Guanglu Wan, Huishuai Zhang, Dongyan Zhao
分类: cs.CV, cs.CL
发布日期: 2025-12-07
💡 一句话要点
MMDuet2:通过多轮强化学习增强视频MLLM的主动交互能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频多模态大语言模型 主动交互 强化学习 文本到文本 视频理解
📋 核心要点
- 现有视频MLLM系统通常以回合制交互,缺乏在视频播放过程中主动响应的能力,限制了实时应用。
- 提出一种文本到文本的主动交互方法,模型自主决定何时响应,基于对话历史和视频帧内容。
- 采用多轮强化学习训练,无需精确标注响应时间,鼓励及时准确的响应,并在ProactiveVideoQA上取得SOTA。
📝 摘要(中文)
近年来,视频多模态大语言模型(Video MLLMs)的进步显著提升了视频理解和多模态交互能力。现有系统大多以回合制方式运行,模型只能在用户回合后回复。本文提出了一种新的文本到文本方法来实现主动交互,模型能够自主决定在视频播放的每一帧是回复还是保持沉默,决策基于对话历史和当前帧的视觉上下文。为了克服先前方法中手动调整响应决策阈值和标注精确回复时间等困难,我们引入了一种基于多轮强化学习的训练方法,该方法鼓励及时和准确的响应,而无需精确的响应时间标注。我们使用SFT和RL在包含52k个视频和两种对话的数据集上训练了我们的模型MMDuet2。实验结果表明,MMDuet2在响应时间和质量方面优于现有的主动视频MLLM基线,在ProactiveVideoQA基准上实现了最先进的性能。
🔬 方法详解
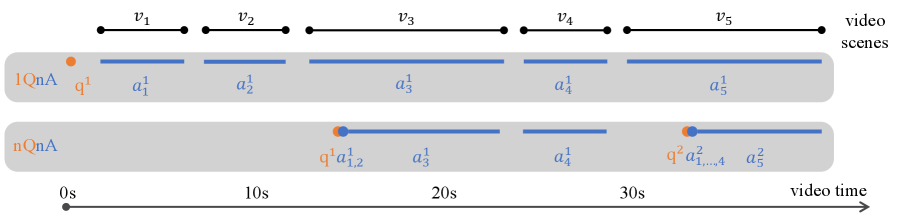
问题定义:现有视频多模态大语言模型主要采用被动式的交互方式,即模型只有在接收到用户的提问后才会进行回答。这种模式无法满足实时应用的需求,例如在观看直播时,模型需要能够主动地根据视频内容和对话历史进行适时地响应。现有方法通常需要手动调整响应决策阈值或标注精确的回复时间,这既费时又费力,且泛化能力较差。
核心思路:本文的核心思路是将主动交互问题转化为一个序列决策问题,即模型在每一帧都需要决定是进行回复还是保持沉默。通过强化学习,模型可以学习到在何时进行回复能够获得最大的奖励,从而实现主动式的交互。这种方法避免了手动调整阈值和标注回复时间,提高了模型的泛化能力。
技术框架:MMDuet2的整体框架是一个文本到文本的模型,它接收对话历史和当前帧的视觉信息作为输入,输出模型是否进行回复的决策以及回复的内容(如果决定回复)。该框架包含以下主要模块:1) 视频编码器:用于提取视频帧的视觉特征。2) 对话历史编码器:用于编码对话历史信息。3) 决策模块:根据视觉特征和对话历史信息,决定是否进行回复。4) 回复生成模块:如果决定回复,则生成回复内容。
关键创新:本文最重要的技术创新点是引入了多轮强化学习来训练模型的主动交互能力。与传统的监督学习方法相比,强化学习不需要精确的回复时间标注,而是通过奖励函数来引导模型学习何时进行回复。此外,本文还提出了一种新的奖励函数,该函数综合考虑了回复的及时性、准确性和流畅性。
关键设计:在强化学习训练过程中,本文采用了一种基于策略梯度的算法。奖励函数的设计至关重要,本文的奖励函数包括以下几个部分:1) 准确性奖励:如果模型的回复是正确的,则给予奖励。2) 及时性奖励:如果模型的回复是及时的,则给予奖励。3) 流畅性奖励:如果模型的回复是流畅的,则给予奖励。4) 惩罚项:如果模型进行了不必要的回复,则给予惩罚。
🖼️ 关键图片


📊 实验亮点
MMDuet2在ProactiveVideoQA基准测试中取得了state-of-the-art的性能,显著优于现有的主动视频MLLM基线。实验结果表明,MMDuet2不仅能够更准确地理解视频内容,还能够更及时地进行回复,从而提供更好的用户体验。具体的性能提升数据在论文中有详细展示。
🎯 应用场景
该研究成果可应用于多种实时视频交互场景,例如智能客服、直播助手、在线教育等。通过主动理解视频内容和用户意图,模型可以提供更加个性化和及时的服务,提升用户体验。未来,该技术有望进一步扩展到机器人交互、自动驾驶等领域,实现更加智能和自然的交互。
📄 摘要(原文)
Recent advances in video multimodal large language models (Video MLLMs) have significantly enhanced video understanding and multi-modal interaction capabilities. While most existing systems operate in a turn-based manner where the model can only reply after user turns, proactively deciding when to reply during video playback presents a promising yet challenging direction for real-time applications. In this work, we propose a novel text-to-text approach to proactive interaction, where the model autonomously determines whether to respond or remain silent at each turn based on dialogue history and visual context up to current frame of an streaming video. To overcome difficulties in previous methods such as manually tuning response decision thresholds and annotating precise reply times, we introduce a multi-turn RL based training method that encourages timely and accurate responses without requiring precise response time annotations. We train our model MMDuet2 on a dataset of 52k videos with two types of dialogues via SFT and RL. Experimental results demonstrate that MMDuet2 outperforms existing proactive Video MLLM baselines in response timing and quality, achieving state-of-the-art performance on the ProactiveVideoQA benchmark.