Stitch and Tell: A Structured Multimodal Data Augmentation Method for Spatial Understanding
作者: Hang Yin, Xiaomin He, PeiWen Yuan, Yiwei Li, Jiayi Shi, Wenxiao Fan, Shaoxiong Feng, Kan Li
分类: cs.CV, cs.AI
发布日期: 2025-12-07
💡 一句话要点
提出Stitch and Tell方法,通过结构化多模态数据增强提升视觉语言模型的空间理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 空间理解 数据增强 空间幻觉 多模态学习
📋 核心要点
- 现有视觉语言模型在理解图像中物体相对位置关系时存在空间幻觉问题,导致生成错误的描述。
- Stitch and Tell (SiTe)方法通过拼接图像并生成空间感知的文本描述,为模型注入结构化的空间监督。
- 实验结果表明,SiTe在空间理解任务上取得了显著提升,同时保持了通用视觉语言任务的性能。
📝 摘要(中文)
现有的视觉语言模型常常遭受空间幻觉问题,即生成关于图像中物体相对位置的不正确描述。我们认为这个问题主要源于图像和文本之间的不对称性。为了丰富视觉语言模型的空间理解能力,我们提出了一种简单、无标注、即插即用的方法,名为Stitch and Tell (SiTe),它将结构化的空间监督注入到数据中。SiTe通过沿空间轴拼接图像并基于拼接图像的布局生成空间感知的标题或问答对来构建拼接的图像-文本对,而无需依赖昂贵的高级模型或人工参与。我们在包括LLaVA-v1.5-7B、LLaVA-Qwen2-1.5B和HALVA-7B在内的三种架构、两个训练数据集和八个基准上评估了SiTe。实验表明,SiTe提高了空间理解任务的性能,例如$ ext{MME}_{ ext{Position}}$ (+5.50%)和Spatial-MM (+4.19%),同时保持或提高了通用视觉语言基准的性能,包括COCO-QA (+1.02%)和MMBench (+4.76%)。我们的研究结果表明,将空间感知的结构显式地注入到训练数据中,提供了一种有效的方法来减轻空间幻觉并提高空间理解能力,同时保留通用的视觉语言能力。
🔬 方法详解
问题定义:论文旨在解决视觉语言模型中存在的空间幻觉问题,即模型无法准确理解和描述图像中物体之间的空间关系。现有方法往往依赖于大量标注数据或复杂的模型结构,成本较高且效果有限。
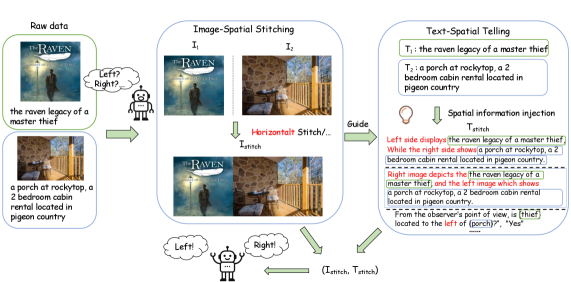
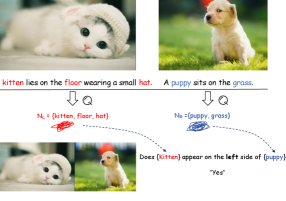
核心思路:论文的核心思路是通过数据增强的方式,显式地将空间信息注入到训练数据中。具体而言,通过拼接图像并生成与拼接布局相对应的文本描述,使模型能够学习到物体之间的空间关系。这种方法无需人工标注,且易于实现。
技术框架:SiTe方法主要包含以下几个步骤:1) 选择需要拼接的图像;2) 沿水平或垂直方向拼接图像;3) 根据拼接图像的布局,生成相应的文本描述,例如描述物体之间的相对位置关系;4) 将拼接后的图像和生成的文本描述作为新的训练数据,用于训练视觉语言模型。
关键创新:该方法的主要创新在于其简单性和有效性。它无需复杂的模型结构或大量的人工标注,即可有效地提升视觉语言模型的空间理解能力。通过拼接图像并生成空间感知的文本描述,SiTe方法为模型提供了明确的空间监督信号。
关键设计:SiTe方法的关键设计在于如何生成与拼接图像布局相对应的文本描述。论文中采用了一种基于规则的方法,根据拼接图像中物体的位置关系,自动生成描述物体相对位置的文本。例如,如果两个物体分别位于拼接图像的左侧和右侧,则生成的文本可能包含“左边的物体在右边的物体的左边”等描述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SiTe方法在多个空间理解基准上取得了显著提升。例如,在$ ext{MME}_{ ext{Position}}$上提升了5.50%,在Spatial-MM上提升了4.19%。同时,SiTe方法在通用视觉语言基准上也保持了良好的性能,例如在COCO-QA上提升了1.02%,在MMBench上提升了4.76%。这些结果表明,SiTe方法能够有效地提升视觉语言模型的空间理解能力,同时保持其通用性。
🎯 应用场景
该研究成果可应用于需要精确空间理解的视觉语言任务,例如机器人导航、图像编辑、视觉问答等。通过提升模型对空间关系的理解能力,可以提高这些应用场景的性能和可靠性。未来,该方法可以扩展到更复杂的场景和任务中,例如三维场景理解和多模态交互。
📄 摘要(原文)
Existing vision-language models often suffer from spatial hallucinations, i.e., generating incorrect descriptions about the relative positions of objects in an image. We argue that this problem mainly stems from the asymmetric properties between images and text. To enrich the spatial understanding ability of vision-language models, we propose a simple, annotation-free, plug-and-play method named $\text{Stitch and Tell}$ (abbreviated as SiTe), which injects structured spatial supervision into data. It constructs stitched image-text pairs by stitching images along a spatial axis and generating spatially-aware captions or question answer pairs based on the layout of stitched image, without relying on costly advanced models or human involvement. We evaluate SiTe across three architectures including LLaVA-v1.5-7B, LLaVA-Qwen2-1.5B and HALVA-7B, two training datasets, and eight benchmarks. Experiments show that SiTe improves spatial understanding tasks such as $\text{MME}_{\text{Position}}$ (+5.50%) and Spatial-MM (+4.19%), while maintaining or improving performance on general vision-language benchmarks including COCO-QA (+1.02%) and MMBench (+4.76%). Our findings suggest that explicitly injecting spatially-aware structure into training data offers an effective way to mitigate spatial hallucinations and improve spatial understanding, while preserving general vision-language capabilities.