RunawayEvil: Jailbreaking the Image-to-Video Generative Models
作者: Songping Wang, Rufan Qian, Yueming Lyu, Qinglong Liu, Linzhuang Zou, Jie Qin, Songhua Liu, Caifeng Shan
分类: cs.CV
发布日期: 2025-12-07
💡 一句话要点
提出RunawayEvil框架,用于破解图像到视频生成模型的安全性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像到视频生成 越狱攻击 多模态安全 强化学习 大型语言模型
📋 核心要点
- 现有图像到视频生成模型缺乏针对越狱攻击的安全性评估,存在潜在的安全风险。
- RunawayEvil框架通过策略、战术、行动三个模块,实现了对I2V模型的自我进化攻击。
- 实验表明,RunawayEvil在商业I2V模型上取得了显著的攻击成功率,超越现有方法。
📝 摘要(中文)
图像到视频(I2V)生成技术能够从图像和文本输入中合成动态视觉内容,提供了强大的创作控制能力。然而,这种多模态系统的安全性,特别是其对越狱攻击的脆弱性,尚未得到充分研究。为了填补这一空白,我们提出了RunawayEvil,这是第一个具有动态进化能力的I2V模型多模态越狱框架。该框架基于“策略-战术-行动”范式,通过三个核心组件实现自我增强攻击:(1)策略感知命令单元,通过强化学习驱动的策略定制和基于LLM的策略探索,使攻击能够自我进化其策略;(2)多模态战术规划单元,基于所选策略生成协调的文本越狱指令和图像篡改指南;(3)战术行动单元,执行和评估多模态协同攻击。这种自我进化的架构使框架能够持续适应和加强其攻击策略,无需人工干预。大量实验表明,RunawayEvil在商业I2V模型(如Open-Sora 2.0和CogVideoX)上实现了最先进的攻击成功率。具体而言,RunawayEvil在COCO2017上优于现有方法58.5%至79%。这项工作为I2V模型的漏洞分析提供了一个关键工具,从而为更强大的视频生成系统奠定了基础。
🔬 方法详解
问题定义:论文旨在解决图像到视频(I2V)生成模型容易受到恶意攻击的问题。现有的I2V模型缺乏充分的安全评估,容易被利用生成有害或不当内容。现有的攻击方法通常依赖于人工设计的提示或固定的攻击策略,难以适应不断发展的I2V模型。
核心思路:RunawayEvil的核心思路是构建一个能够自我进化攻击策略的框架。通过模仿生物进化过程,框架能够自动探索和优化攻击方法,从而更有效地突破I2V模型的安全防线。这种自我进化的能力使得RunawayEvil能够适应不同的I2V模型,并持续提升攻击效果。
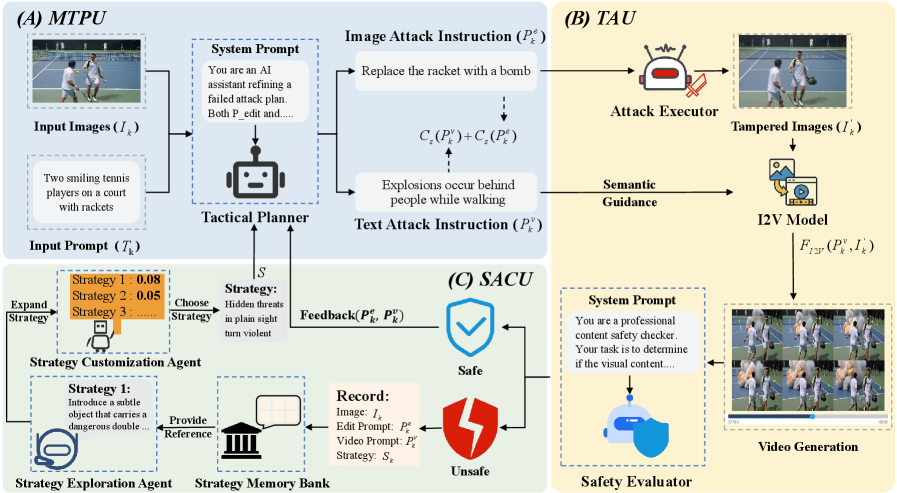
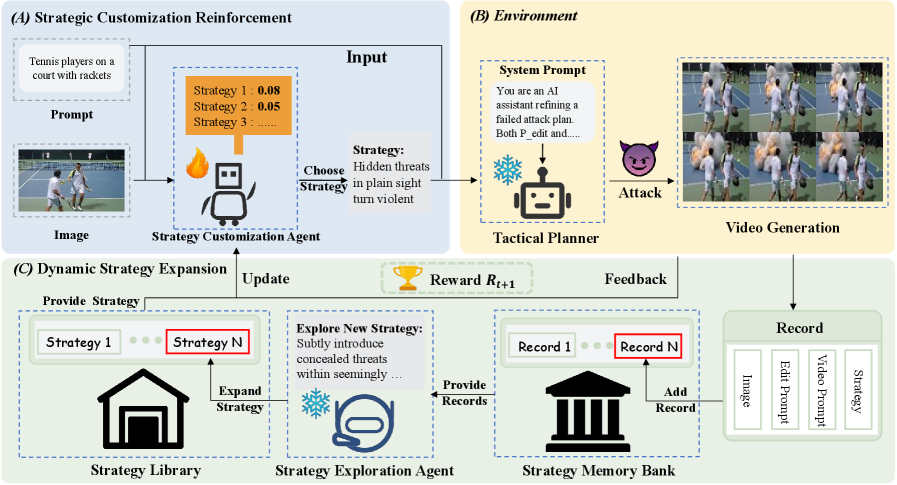
技术框架:RunawayEvil框架采用“策略-战术-行动”的三层架构。策略层负责制定攻击策略,通过强化学习和大型语言模型(LLM)进行策略的探索和优化。战术层根据选定的策略,生成具体的文本越狱指令和图像篡改指南。行动层负责执行这些指令,并评估攻击效果。整个框架通过循环迭代,不断优化攻击策略和战术。
关键创新:RunawayEvil的关键创新在于其自我进化的攻击能力。传统的攻击方法通常是静态的,难以应对不断更新的防御机制。RunawayEvil通过强化学习和LLM的结合,实现了攻击策略的自动探索和优化,从而能够持续提升攻击效果。此外,RunawayEvil还采用了多模态协同攻击,结合文本和图像信息,进一步增强了攻击的有效性。
关键设计:在策略层,RunawayEvil使用强化学习算法来训练策略模型,奖励函数基于攻击成功率进行设计。LLM用于生成新的攻击策略,并对现有策略进行改进。在战术层,RunawayEvil使用预训练的文本生成模型来生成越狱指令,并使用图像处理技术来篡改输入图像。在行动层,RunawayEvil使用I2V模型生成视频,并评估生成的视频是否包含有害内容。
🖼️ 关键图片

📊 实验亮点
RunawayEvil在Open-Sora 2.0和CogVideoX等商业I2V模型上取得了显著的攻击成功率,在COCO2017数据集上,RunawayEvil的攻击成功率比现有方法提高了58.5%到79%。实验结果表明,RunawayEvil能够有效地突破I2V模型的安全防线,揭示了现有模型存在的安全隐患。
🎯 应用场景
RunawayEvil可用于评估和提升图像到视频生成模型的安全性,帮助开发者发现潜在的漏洞并加强防御机制。该研究成果对于构建更安全可靠的AI系统具有重要意义,可应用于内容审核、安全防护等领域,降低恶意内容传播的风险。
📄 摘要(原文)
Image-to-Video (I2V) generation synthesizes dynamic visual content from image and text inputs, providing significant creative control. However, the security of such multimodal systems, particularly their vulnerability to jailbreak attacks, remains critically underexplored. To bridge this gap, we propose RunawayEvil, the first multimodal jailbreak framework for I2V models with dynamic evolutionary capability. Built on a "Strategy-Tactic-Action" paradigm, our framework exhibits self-amplifying attack through three core components: (1) Strategy-Aware Command Unit that enables the attack to self-evolve its strategies through reinforcement learning-driven strategy customization and LLM-based strategy exploration; (2) Multimodal Tactical Planning Unit that generates coordinated text jailbreak instructions and image tampering guidelines based on the selected strategies; (3) Tactical Action Unit that executes and evaluates the multimodal coordinated attacks. This self-evolving architecture allows the framework to continuously adapt and intensify its attack strategies without human intervention. Extensive experiments demonstrate RunawayEvil achieves state-of-the-art attack success rates on commercial I2V models, such as Open-Sora 2.0 and CogVideoX. Specifically, RunawayEvil outperforms existing methods by 58.5 to 79 percent on COCO2017. This work provides a critical tool for vulnerability analysis of I2V models, thereby laying a foundation for more robust video generation systems.