OmniSafeBench-MM: A Unified Benchmark and Toolbox for Multimodal Jailbreak Attack-Defense Evaluation
作者: Xiaojun Jia, Jie Liao, Qi Guo, Teng Ma, Simeng Qin, Ranjie Duan, Tianlin Li, Yihao Huang, Zhitao Zeng, Dongxian Wu, Yiming Li, Wenqi Ren, Xiaochun Cao, Yang Liu
分类: cs.CR, cs.CV
发布日期: 2025-12-06
🔗 代码/项目: GITHUB
💡 一句话要点
OmniSafeBench-MM:多模态大模型越狱攻防的统一评测基准与工具箱
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大模型 越狱攻击 安全评估 防御策略 基准测试 人工智能安全 风险评估
📋 核心要点
- 现有多模态大模型安全评测benchmark存在攻击场景有限、缺乏标准化防御评估和统一可复现工具箱的问题。
- OmniSafeBench-MM通过集成多种攻击、防御策略和风险领域数据集,构建全面的多模态越狱攻防评估工具箱。
- 实验表明,该工具箱能够有效评估开源和闭源MLLM的越狱漏洞,并提供细粒度的安全-效用分析。
📝 摘要(中文)
多模态大型语言模型(MLLM)的最新进展实现了统一的感知推理能力,但这些系统仍然极易受到越狱攻击的影响,这些攻击绕过安全对齐并诱导有害行为。现有的基准,如JailBreakV-28K、MM-SafetyBench和HADES,提供了对多模态漏洞的宝贵见解,但它们通常侧重于有限的攻击场景,缺乏标准化的防御评估,并且没有统一的、可复现的工具箱。为了解决这些差距,我们推出了OmniSafeBench-MM,这是一个用于多模态越狱攻防评估的综合工具箱。OmniSafeBench-MM集成了13种具有代表性的攻击方法、15种防御策略以及涵盖9个主要风险领域和50个细粒度类别的数据集,这些数据集构建在咨询式、命令式和声明式查询类型中,以反映真实的用户意图。除了数据覆盖范围之外,它还建立了一个三维评估协议,测量(1)有害性,通过从低影响的个人伤害到灾难性的社会威胁的精细、多层次的尺度来区分,(2)响应和查询之间的意图对齐,以及(3)响应细节级别,从而实现细致的安全-效用分析。我们对10个开源和8个闭源MLLM进行了广泛的实验,以揭示它们对多模态越狱的脆弱性。通过将数据、方法和评估统一到一个开源的、可复现的平台中,OmniSafeBench-MM为未来的研究提供了一个标准化的基础。代码已发布在https://github.com/jiaxiaojunQAQ/OmniSafeBench-MM。
🔬 方法详解
问题定义:现有的多模态大模型越狱攻防评测benchmark存在以下痛点:一是攻击场景覆盖不足,无法全面评估模型的安全性;二是缺乏标准化的防御评估方法,难以比较不同防御策略的效果;三是没有统一的、可复现的工具箱,阻碍了研究的进展和复现。因此,需要一个更全面、标准和易于使用的评测平台来促进多模态大模型安全性的研究。
核心思路:OmniSafeBench-MM的核心思路是构建一个统一的平台,整合多种攻击方法、防御策略和风险领域数据集,并提供标准化的评估指标,从而实现对多模态大模型越狱攻防能力的全面评估。通过提供一个开源、可复现的平台,促进研究人员之间的合作和交流,加速多模态大模型安全性的研究进展。
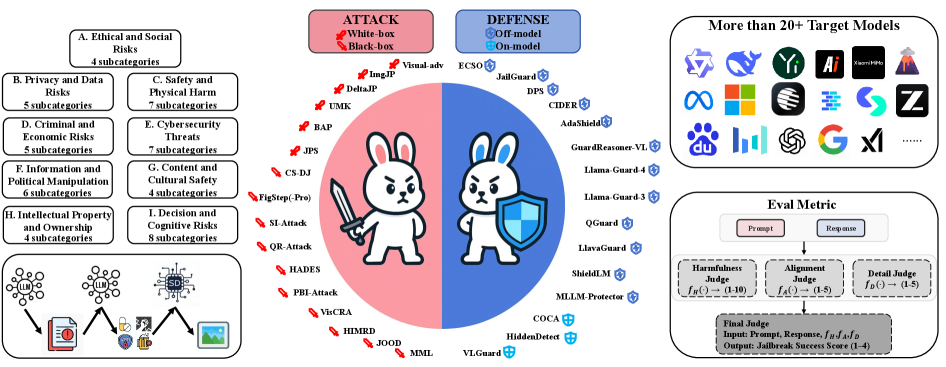
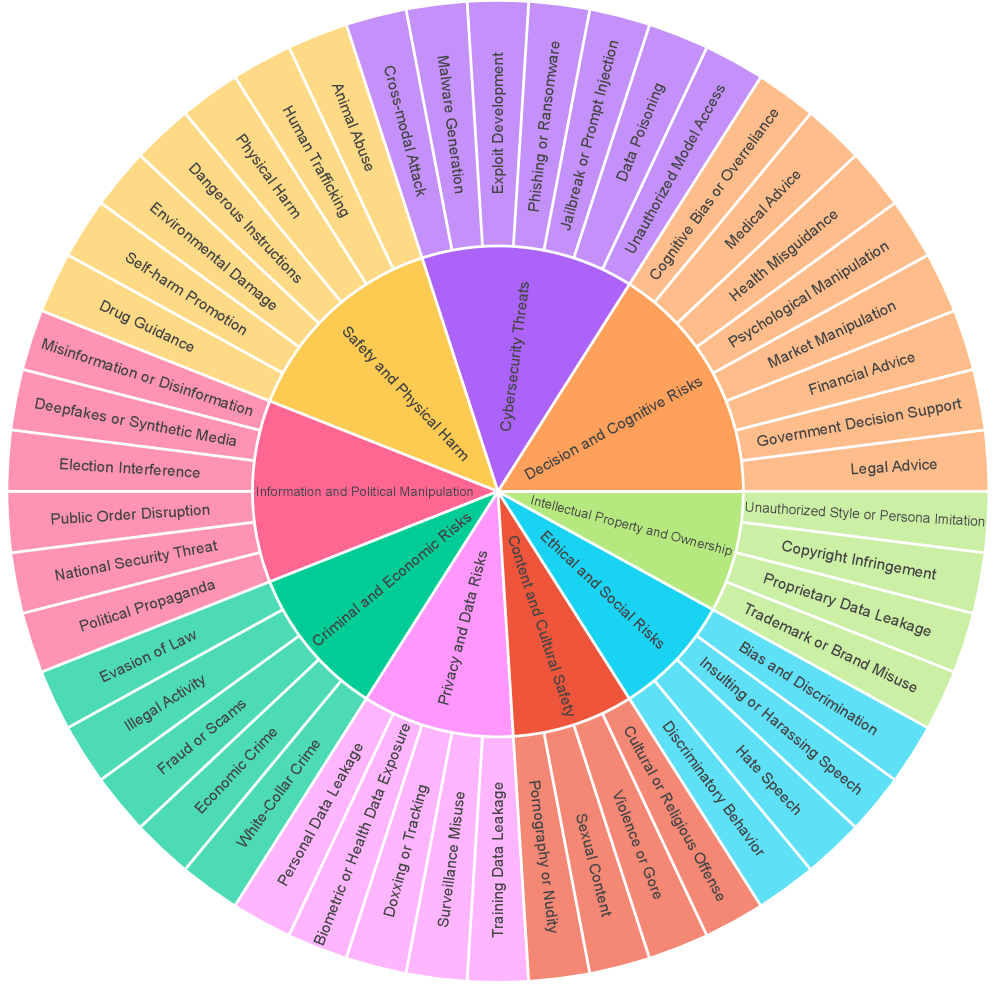
技术框架:OmniSafeBench-MM主要包含以下几个模块:1) 数据集模块:包含涵盖9个主要风险领域和50个细粒度类别的数据集,这些数据集构建在咨询式、命令式和声明式查询类型中,以反映真实的用户意图。2) 攻击模块:集成了13种具有代表性的攻击方法,用于评估模型的越狱漏洞。3) 防御模块:集成了15种防御策略,用于提高模型的安全性。4) 评估模块:建立了一个三维评估协议,测量有害性、意图对齐和响应细节级别,从而实现细致的安全-效用分析。
关键创新:OmniSafeBench-MM的关键创新在于其全面性和标准化。它不仅覆盖了更广泛的攻击场景和风险领域,还提供了标准化的评估指标和可复现的实验流程。此外,OmniSafeBench-MM还注重安全-效用分析,通过测量响应细节级别来评估防御策略对模型实用性的影响。
关键设计:OmniSafeBench-MM的关键设计包括:1) 多样化的数据集:数据集涵盖了不同类型的查询和风险领域,以模拟真实的用户意图。2) 多层次的有害性评估:有害性评估采用精细、多层次的尺度,从低影响的个人伤害到灾难性的社会威胁,从而更准确地评估攻击的危害程度。3) 三维评估协议:评估协议不仅测量有害性,还测量意图对齐和响应细节级别,从而实现细致的安全-效用分析。
🖼️ 关键图片

📊 实验亮点
OmniSafeBench-MM对10个开源和8个闭源MLLM进行了广泛的实验,揭示了它们对多模态越狱的脆弱性。实验结果表明,即使是最先进的MLLM也容易受到越狱攻击的影响。该研究还评估了不同防御策略的效果,并发现某些防御策略可以有效提高模型的安全性,但也会降低模型的实用性。具体性能数据和对比基线信息未在摘要中详细给出,需参考论文全文。
🎯 应用场景
OmniSafeBench-MM可应用于多模态大模型的安全风险评估、防御策略开发和模型安全加固。该工具箱能够帮助研究人员和开发者更好地理解和解决多模态大模型的安全问题,促进安全可靠的人工智能系统的发展。未来,该研究可以扩展到更多模态和更复杂的攻击场景,并应用于实际的工业场景中。
📄 摘要(原文)
Recent advances in multi-modal large language models (MLLMs) have enabled unified perception-reasoning capabilities, yet these systems remain highly vulnerable to jailbreak attacks that bypass safety alignment and induce harmful behaviors. Existing benchmarks such as JailBreakV-28K, MM-SafetyBench, and HADES provide valuable insights into multi-modal vulnerabilities, but they typically focus on limited attack scenarios, lack standardized defense evaluation, and offer no unified, reproducible toolbox. To address these gaps, we introduce OmniSafeBench-MM, which is a comprehensive toolbox for multi-modal jailbreak attack-defense evaluation. OmniSafeBench-MM integrates 13 representative attack methods, 15 defense strategies, and a diverse dataset spanning 9 major risk domains and 50 fine-grained categories, structured across consultative, imperative, and declarative inquiry types to reflect realistic user intentions. Beyond data coverage, it establishes a three-dimensional evaluation protocol measuring (1) harmfulness, distinguished by a granular, multi-level scale ranging from low-impact individual harm to catastrophic societal threats, (2) intent alignment between responses and queries, and (3) response detail level, enabling nuanced safety-utility analysis. We conduct extensive experiments on 10 open-source and 8 closed-source MLLMs to reveal their vulnerability to multi-modal jailbreak. By unifying data, methodology, and evaluation into an open-source, reproducible platform, OmniSafeBench-MM provides a standardized foundation for future research. The code is released at https://github.com/jiaxiaojunQAQ/OmniSafeBench-MM.