Towards Stable Cross-Domain Depression Recognition under Missing Modalities
作者: Jiuyi Chen, Mingkui Tan, Haifeng Lu, Qiuna Xu, Zhihua Wang, Runhao Zeng, Xiping Hu
分类: cs.CV
发布日期: 2025-12-06
💡 一句话要点
提出SCD-MLLM框架,解决跨域抑郁症识别中模态缺失时的稳定性问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 抑郁症识别 跨域学习 模态缺失 大型语言模型 自适应融合 心理健康
📋 核心要点
- 现有基于音视频的多模态抑郁症检测方法缺乏统一框架,难以泛化到不同场景,且对模态缺失的鲁棒性不足。
- 提出SCD-MLLM框架,利用多源数据输入适配器(MDIA)和模态感知自适应融合模块(MAFM),实现跨域稳定识别。
- 在五个数据集上的实验表明,SCD-MLLM优于SOTA模型和商业LLM,在跨域泛化和模态缺失场景下表现更佳。
📝 摘要(中文)
抑郁症对公众健康构成严重威胁,及时和可扩展的筛查迫在眉睫。多模态自动抑郁症检测(ADD)提供了一种有前景的解决方案;然而,广泛研究的基于音频和视频的ADD方法缺乏一个统一的、可泛化的框架,以适应不同的抑郁症识别场景,并且在模态缺失时表现出有限的稳定性,而模态缺失在真实世界的数据中很常见。本文提出了一种基于多模态大型语言模型(SCD-MLLM)的稳定跨域抑郁症识别统一框架。该框架支持整合和处理来自不同来源的异构抑郁症相关数据,同时在模态输入不完整的情况下保持稳定性。具体来说,SCD-MLLM引入了两个关键组件:(i)多源数据输入适配器(MDIA),它采用掩码机制和特定于任务的提示,将异构的抑郁症相关输入转换为统一的token序列,从而解决不同数据源之间的不一致性;(ii)模态感知自适应融合模块(MAFM),它通过共享投影机制自适应地整合音频和视觉特征,从而增强在模态缺失条件下的鲁棒性。我们在五个公开可用的异构抑郁症数据集(CMDC、AVEC2014、DAIC-WOZ、DVlog和EATD)上,在多数据集联合训练设置下进行了全面的实验。在完整和部分模态设置下,SCD-MLLM优于最先进(SOTA)的模型以及领先的商业LLM(Gemini和GPT),证明了其卓越的跨域泛化能力、增强的捕捉抑郁症多模态线索的能力,以及在真实世界应用中对模态缺失情况的强大稳定性。
🔬 方法详解
问题定义:论文旨在解决跨域抑郁症识别中,由于数据来源多样性和模态缺失带来的挑战。现有方法难以有效整合异构数据,并且在部分模态缺失时性能显著下降,限制了其在实际应用中的可靠性。
核心思路:论文的核心思路是利用多模态大型语言模型(MLLM)的强大表征能力,构建一个统一的框架,能够处理来自不同来源的异构数据,并在模态缺失的情况下保持识别的稳定性。通过将不同模态的数据转换为统一的token序列,并采用自适应融合机制,模型能够更好地捕捉抑郁症的多模态线索。
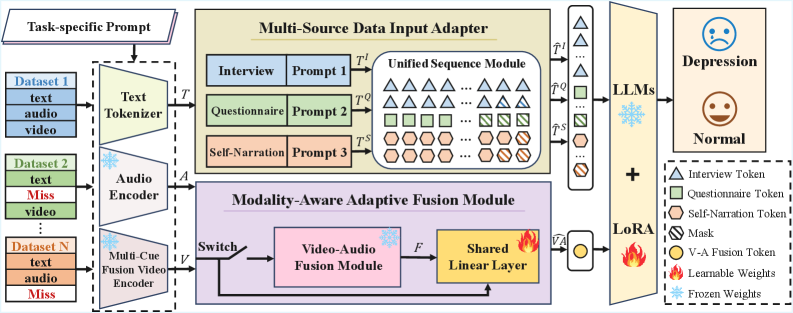
技术框架:SCD-MLLM框架主要包含两个核心模块:多源数据输入适配器(MDIA)和模态感知自适应融合模块(MAFM)。MDIA负责将来自不同数据集的音频和视频数据转换为统一的token序列,利用掩码机制和任务特定提示来处理数据异构性。MAFM则负责自适应地融合音频和视觉特征,通过共享投影机制增强模型在模态缺失情况下的鲁棒性。整个框架基于MLLM构建,利用其强大的语言理解和生成能力进行抑郁症识别。
关键创新:该论文的关键创新在于提出了一个统一的、基于MLLM的框架,能够同时解决跨域数据异构性和模态缺失问题。MDIA和MAFM模块的设计是针对抑郁症识别任务的定制化解决方案,能够有效提升模型在实际应用中的性能和可靠性。与现有方法相比,SCD-MLLM具有更强的泛化能力和鲁棒性。
关键设计:MDIA模块采用掩码机制来处理不同数据源的差异,并使用任务特定提示来引导模型学习。MAFM模块使用共享投影机制将音频和视觉特征映射到同一空间,然后通过自注意力机制进行融合。损失函数方面,论文可能采用了交叉熵损失或类似的分类损失函数,以优化模型的识别性能。具体的网络结构细节,例如MLLM的具体选择和参数设置,可能在论文中有更详细的描述。
🖼️ 关键图片


📊 实验亮点
SCD-MLLM在五个公开数据集上的实验结果表明,其性能优于SOTA模型和商业LLM(Gemini和GPT)。在跨域泛化和模态缺失场景下,SCD-MLLM表现出显著的优势,证明了其在实际应用中的潜力。具体的性能提升幅度可能在论文中有更详细的量化数据。
🎯 应用场景
该研究成果可应用于大规模抑郁症筛查、心理健康咨询和辅助诊断等领域。通过整合来自不同渠道的数据,例如社交媒体、在线访谈和临床记录,可以实现更准确、更全面的抑郁症评估。该框架对模态缺失的鲁棒性使其在实际应用中更具优势,有助于提高抑郁症的早期识别率和干预效果。
📄 摘要(原文)
Depression poses serious public health risks, including suicide, underscoring the urgency of timely and scalable screening. Multimodal automatic depression detection (ADD) offers a promising solution; however, widely studied audio- and video-based ADD methods lack a unified, generalizable framework for diverse depression recognition scenarios and show limited stability to missing modalities, which are common in real-world data. In this work, we propose a unified framework for Stable Cross-Domain Depression Recognition based on Multimodal Large Language Model (SCD-MLLM). The framework supports the integration and processing of heterogeneous depression-related data collected from varied sources while maintaining stability in the presence of incomplete modality inputs. Specifically, SCD-MLLM introduces two key components: (i) Multi-Source Data Input Adapter (MDIA), which employs masking mechanism and task-specific prompts to transform heterogeneous depression-related inputs into uniform token sequences, addressing inconsistency across diverse data sources; (ii) Modality-Aware Adaptive Fusion Module (MAFM), which adaptively integrates audio and visual features via a shared projection mechanism, enhancing resilience under missing modality conditions. e conduct comprehensive experiments under multi-dataset joint training settings on five publicly available and heterogeneous depression datasets from diverse scenarios: CMDC, AVEC2014, DAIC-WOZ, DVlog, and EATD. Across both complete and partial modality settings, SCD-MLLM outperforms state-of-the-art (SOTA) models as well as leading commercial LLMs (Gemini and GPT), demonstrating superior cross-domain generalization, enhanced ability to capture multimodal cues of depression, and strong stability to missing modality cases in real-world applications.