AGORA: Adversarial Generation Of Real-time Animatable 3D Gaussian Head Avatars
作者: Ramazan Fazylov, Sergey Zagoruyko, Aleksandr Parkin, Stamatis Lefkimmiatis, Ivan Laptev
分类: cs.CV
发布日期: 2025-12-06 (更新: 2025-12-10)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
AGORA:提出基于对抗生成网络的实时可控3D高斯头部头像
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D高斯溅射 生成对抗网络 头部头像生成 实时渲染 FLAME模型
📋 核心要点
- 现有基于NeRF的头像生成方法渲染速度慢,动态一致性差,而3DGS方法缺乏动态控制,难以满足实时应用需求。
- AGORA通过在GAN框架内扩展3DGS,并引入FLAME条件变形分支预测高斯残差,实现身份保持和细粒度表情控制。
- 实验表明,AGORA在表情准确性上优于NeRF方法,并在GPU和CPU上均实现了实时渲染速度,为数字人应用带来突破。
📝 摘要(中文)
生成高保真、可动画的3D人体头像仍然是计算机图形学和视觉领域的核心挑战,在VR、远程呈现和娱乐方面有广泛应用。现有的基于NeRF等隐式表示的方法渲染速度慢且动态不一致,而3D高斯溅射(3DGS)方法通常仅限于静态头部生成,缺乏动态控制。我们通过引入AGORA来弥合这一差距,AGORA是一个新颖的框架,它在生成对抗网络中扩展了3DGS以生成可动画的头像。我们的主要贡献是一个轻量级的、FLAME条件变形分支,它可以预测每个高斯的残差,从而实现保持身份的、细粒度的表情控制,同时允许实时推理。通过利用参数化网格的合成渲染的双鉴别器训练方案来强制执行表情保真度。AGORA生成的头像不仅在视觉上逼真,而且可以精确控制。在定量方面,我们优于最先进的基于NeRF的方法,在单个GPU上以250+ FPS的速度渲染,并且值得注意的是,在仅CPU推理下以~9 FPS的速度渲染——据我们所知,这是首次展示了实用的仅CPU可动画3DGS头像合成。这项工作代表了朝着实用、高性能数字人迈出的重要一步。
🔬 方法详解
问题定义:现有基于NeRF的方法渲染速度慢,难以满足实时应用需求,且动态一致性较差。而3D高斯溅射(3DGS)方法虽然渲染速度快,但通常仅限于静态头部生成,缺乏动态控制,无法生成可动画的头像。因此,如何生成高保真、可动画且能实时渲染的3D头部头像是一个关键问题。
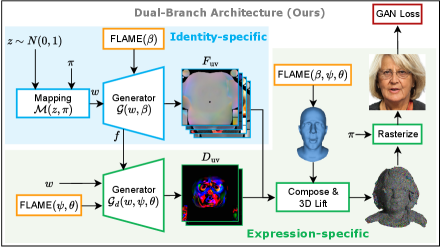
核心思路:AGORA的核心思路是将3DGS扩展到生成对抗网络(GAN)中,利用GAN的生成能力来生成逼真的头像,并引入一个轻量级的FLAME条件变形分支来控制头像的表情。通过预测每个高斯的残差,实现对3D高斯分布的精细调整,从而实现身份保持和细粒度的表情控制。
技术框架:AGORA的整体框架是一个生成对抗网络,其中生成器基于3DGS,用于生成3D头部头像。生成器接收FLAME参数作为输入,通过FLAME条件变形分支预测每个高斯的残差,然后对3D高斯分布进行调整。判别器则用于区分生成的头像和真实头像,从而提高生成头像的逼真度。框架包含以下主要模块:3DGS生成器、FLAME条件变形分支、双鉴别器。
关键创新:AGORA最重要的技术创新点是FLAME条件变形分支,它能够预测每个高斯的残差,从而实现对3D高斯分布的精细调整。与现有方法相比,AGORA的变形分支更加轻量级,能够实现实时推理。此外,AGORA还采用了双鉴别器训练方案,利用参数化网格的合成渲染来强制执行表情保真度。
关键设计:AGORA的关键设计包括:1) 使用FLAME参数作为变形分支的输入,从而实现对表情的精确控制;2) 设计轻量级的变形分支,以保证实时推理速度;3) 采用双鉴别器训练方案,分别从图像空间和特征空间对生成头像进行约束,提高生成头像的逼真度和表情准确性。损失函数包括对抗损失、表情损失和身份保持损失等。
🖼️ 关键图片


📊 实验亮点
AGORA在表情准确性方面优于最先进的基于NeRF的方法,并在单个GPU上实现了250+ FPS的渲染速度。更重要的是,AGORA在仅CPU推理下也能达到~9 FPS的渲染速度,这使得它成为首个展示了实用的仅CPU可动画3DGS头像合成的方法。这些实验结果表明,AGORA在性能和效率方面都具有显著优势。
🎯 应用场景
AGORA具有广泛的应用前景,包括虚拟现实(VR)、远程呈现、娱乐、游戏和社交媒体等领域。它可以用于创建逼真的虚拟化身,实现远程会议和协作,为游戏角色赋予更丰富的表情,以及在社交媒体上进行个性化表达。AGORA的实时渲染能力使其能够应用于对延迟敏感的场景,为用户带来更流畅的体验。
📄 摘要(原文)
The generation of high-fidelity, animatable 3D human avatars remains a core challenge in computer graphics and vision, with applications in VR, telepresence, and entertainment. Existing approaches based on implicit representations like NeRFs suffer from slow rendering and dynamic inconsistencies, while 3D Gaussian Splatting (3DGS) methods are typically limited to static head generation, lacking dynamic control. We bridge this gap by introducing AGORA, a novel framework that extends 3DGS within a generative adversarial network to produce animatable avatars. Our key contribution is a lightweight, FLAME-conditioned deformation branch that predicts per-Gaussian residuals, enabling identity-preserving, fine-grained expression control while allowing real-time inference. Expression fidelity is enforced via a dual-discriminator training scheme leveraging synthetic renderings of the parametric mesh. AGORA generates avatars that are not only visually realistic but also precisely controllable. Quantitatively, we outperform state-of-the-art NeRF-based methods on expression accuracy while rendering at 250+ FPS on a single GPU, and, notably, at $\sim$9 FPS under CPU-only inference - representing, to our knowledge, the first demonstration of practical CPU-only animatable 3DGS avatar synthesis. This work represents a significant step toward practical, high-performance digital humans. Project website: https://ramazan793.github.io/AGORA/