Beyond Hallucinations: A Multimodal-Guided Task-Aware Generative Image Compression for Ultra-Low Bitrate
作者: Kaile Wang, Lijun He, Haisheng Fu, Haixia Bi, Fan Li
分类: cs.CV
发布日期: 2025-12-06
💡 一句话要点
提出多模态引导的任务感知生成图像压缩框架,解决超低码率下的语义偏差问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 生成图像压缩 超低码率 多模态引导 扩散模型 语义通信
📋 核心要点
- 现有生成图像压缩方法在超低码率下易产生幻觉,导致语义偏差,影响实际应用。
- MTGC框架通过融合文本描述、高压缩图像和语义伪词三种模态,增强语义一致性。
- 实验结果表明,MTGC在超低码率下显著提升了语义一致性、感知质量和像素级保真度。
📝 摘要(中文)
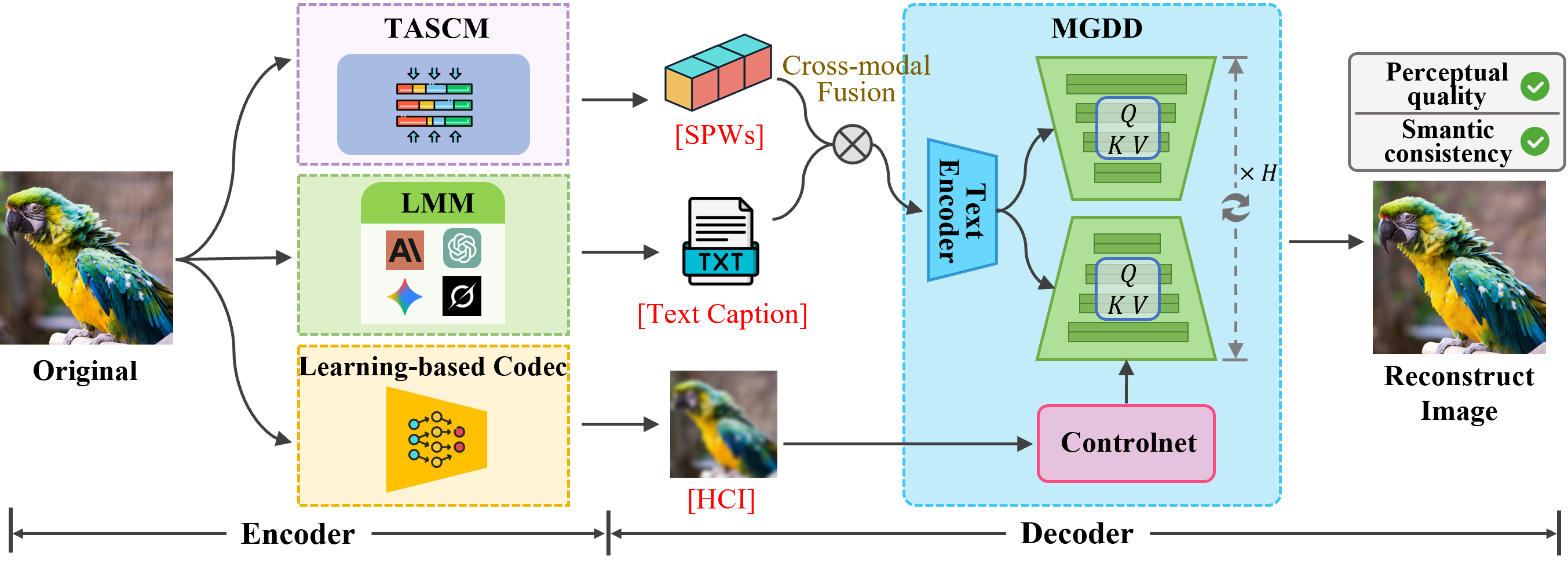
生成图像压缩在感知质量方面表现出色,但在超低码率(bpp < 0.05)下常出现由生成幻觉引起的语义偏差,限制了其在带宽受限的6G语义通信场景中的可靠部署。本文重新评估了多模态引导的定位和作用,并提出了一个多模态引导的任务感知生成图像压缩(MTGC)框架。MTGC集成了三种引导模态以增强语义一致性:用于全局语义的简洁而鲁棒的文本描述,保留低级视觉信息的高度压缩图像(HCI),以及用于细粒度任务相关语义的语义伪词(SPW)。SPW由我们设计的任务感知语义压缩模块(TASCM)生成,该模块以任务为导向,驱动多头自注意力机制关注并提取与生成任务相关的语义,同时过滤掉冗余。随后,为了促进这些模态的协同引导,我们设计了一个多模态引导扩散解码器(MGDD),采用双路径协同引导机制,协同交叉注意力和ControlNet加性残差,将这三种引导精确地注入到扩散过程中,并利用扩散模型强大的生成先验来重建图像。大量实验表明,MTGC在超低码率下持续提高语义一致性(例如,在DIV2K数据集上DISTS下降10.59%),同时在感知质量和像素级保真度方面也取得了显著提升。
🔬 方法详解
问题定义:论文旨在解决超低码率(bpp < 0.05)下,生成图像压缩方法由于生成幻觉而导致的语义偏差问题。现有方法在极低比特率下难以保持图像的语义一致性,影响了其在带宽受限场景下的应用。
核心思路:论文的核心思路是利用多模态信息引导生成过程,从而约束生成结果,减少幻觉,提高语义一致性。具体来说,通过融合文本描述、高压缩图像和任务相关的语义伪词,从全局到局部,多层次地引导图像生成。
技术框架:MTGC框架主要包含两个核心模块:任务感知语义压缩模块(TASCM)和多模态引导扩散解码器(MGDD)。TASCM负责生成任务相关的语义伪词,MGDD则负责将文本描述、高压缩图像和语义伪词融合,并引导扩散模型生成最终图像。整体流程是:输入图像首先经过编码器得到潜在表示,然后通过TASCM生成语义伪词。同时,输入图像被压缩成高压缩图像,并生成文本描述。最后,MGDD将这三种模态的信息注入到扩散模型中,逐步生成高质量的重建图像。
关键创新:论文的关键创新在于多模态引导和任务感知语义压缩。多模态引导通过融合不同模态的信息,提供了更全面的语义约束,有效减少了幻觉。任务感知语义压缩模块则能够提取与特定任务相关的语义信息,从而更好地指导图像生成。此外,MGDD采用双路径协同引导机制,协同交叉注意力和ControlNet加性残差,更精确地注入引导信息。
关键设计:TASCM采用多头自注意力机制,并以任务为导向,学习关注与任务相关的语义信息。MGDD则利用交叉注意力机制融合文本描述,利用ControlNet加性残差融合高压缩图像和语义伪词。损失函数方面,可能采用了感知损失、对抗损失以及像素级损失等,以保证生成图像的感知质量和像素级保真度。(具体损失函数细节未知)
🖼️ 关键图片


📊 实验亮点
实验结果表明,MTGC框架在超低码率下显著提高了语义一致性,例如在DIV2K数据集上DISTS指标下降了10.59%。同时,在感知质量和像素级保真度方面也取得了显著提升。这些结果表明,MTGC框架能够有效解决超低码率下的语义偏差问题,具有很强的竞争力。
🎯 应用场景
该研究成果可应用于带宽受限的6G通信、远程医疗、卫星图像传输等领域。在这些场景下,需要在极低的比特率下传输图像,同时保证图像的语义信息不丢失。MTGC框架能够有效解决这一问题,提高图像传输的效率和可靠性,具有重要的实际应用价值。
📄 摘要(原文)
Generative image compression has recently shown impressive perceptual quality, but often suffers from semantic deviations caused by generative hallucinations at ultra-low bitrate (bpp < 0.05), limiting its reliable deployment in bandwidth-constrained 6G semantic communication scenarios. In this work, we reassess the positioning and role of of multimodal guidance, and propose a Multimodal-Guided Task-Aware Generative Image Compression (MTGC) framework. Specifically, MTGC integrates three guidance modalities to enhance semantic consistency: a concise but robust text caption for global semantics, a highly compressed image (HCI) retaining low-level visual information, and Semantic Pseudo-Words (SPWs) for fine-grained task-relevant semantics. The SPWs are generated by our designed Task-Aware Semantic Compression Module (TASCM), which operates in a task-oriented manner to drive the multi-head self-attention mechanism to focus on and extract semantics relevant to the generation task while filtering out redundancy. Subsequently, to facilitate the synergistic guidance of these modalities, we design a Multimodal-Guided Diffusion Decoder (MGDD) employing a dual-path cooperative guidance mechanism that synergizes cross-attention and ControlNet additive residuals to precisely inject these three guidance into the diffusion process, and leverages the diffusion model's powerful generative priors to reconstruct the image. Extensive experiments demonstrate that MTGC consistently improves semantic consistency (e.g., DISTS drops by 10.59% on the DIV2K dataset) while also achieving remarkable gains in perceptual quality and pixel-level fidelity at ultra-low bitrate.