Exploiting Spatiotemporal Properties for Efficient Event-Driven Human Pose Estimation
作者: Haoxian Zhou, Chuanzhi Xu, Langyi Chen, Haodong Chen, Yuk Ying Chung, Qiang Qu, Xaoming Chen, Weidong Cai
分类: cs.CV, cs.AI
发布日期: 2025-12-06
💡 一句话要点
提出基于时空特性的事件相机人体姿态估计方法,提升效率与精度
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 事件相机 人体姿态估计 点云处理 时空建模 深度学习
📋 核心要点
- 现有事件相机人体姿态估计方法通常转换为密集帧,牺牲了事件流高时间分辨率的优势,计算成本也较高。
- 论文提出利用事件流的时空特性,设计事件时间切片卷积和事件切片排序模块,进行高效的时序建模。
- 实验表明,该方法在DHP19数据集上,基于PointNet、DGCNN和Point Transformer等骨干网络均取得了性能提升。
📝 摘要(中文)
人体姿态估计旨在预测人体关键点以分析人体运动。事件相机提供高时间分辨率和低延迟,从而能够在具有挑战性的条件下实现稳健的估计。然而,大多数现有方法将事件流转换为密集的事件帧,这增加了额外的计算量并牺牲了事件信号的高时间分辨率。本文旨在利用基于点云框架的事件流的时空特性,以增强人体姿态估计性能。我们设计了事件时间切片卷积模块来捕获事件切片之间的短期依赖关系,并将其与事件切片排序模块相结合,以进行结构化的时间建模。我们还在基于点云的事件表示中应用边缘增强,以增强稀疏事件条件下的空间边缘信息,从而进一步提高性能。在DHP19数据集上的实验表明,我们提出的方法在三个具有代表性的点云骨干网络(PointNet、DGCNN和Point Transformer)上始终如一地提高了性能。
🔬 方法详解
问题定义:现有基于事件相机的人体姿态估计方法,通常将事件流转换为密集的事件帧,这不仅增加了计算负担,还损失了事件相机高时间分辨率的优势。如何在保持事件相机固有优势的前提下,高效准确地进行人体姿态估计是一个挑战。
核心思路:论文的核心思路是直接利用事件流的时空特性,避免转换为密集帧。通过设计专门的模块来捕获事件流在时间和空间上的依赖关系,从而实现高效且准确的姿态估计。这种方法旨在充分利用事件相机提供的高时间分辨率信息。
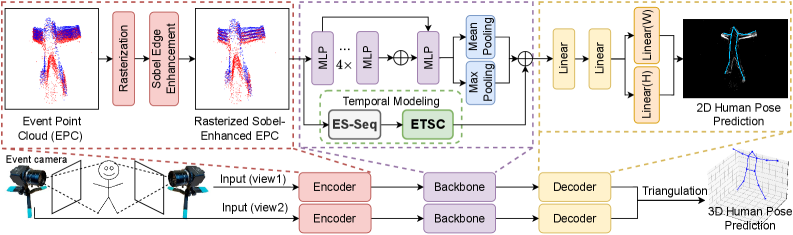
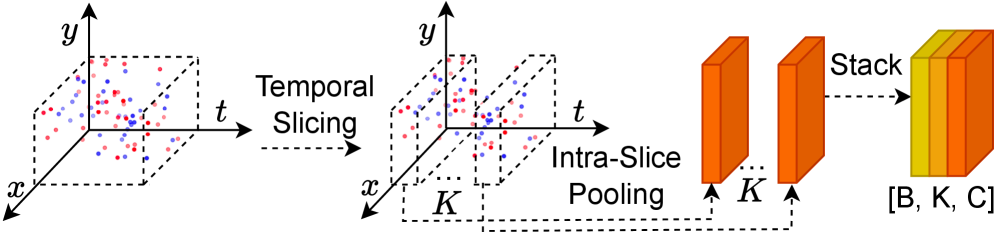
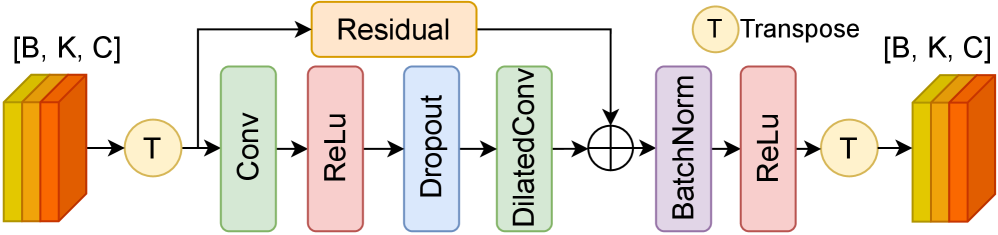
技术框架:整体框架基于点云处理。首先,将事件流转换为点云表示。然后,通过Event Temporal Slicing Convolution (ETSC)模块捕获短时时间依赖关系。接着,使用Event Slice Sequencing (ESS)模块进行结构化的时间建模。最后,通过点云处理骨干网络(如PointNet、DGCNN、Point Transformer)进行特征提取和姿态估计。为了增强稀疏事件条件下的空间信息,还采用了边缘增强技术。
关键创新:关键创新在于直接在事件流的点云表示上进行时空建模,避免了转换为密集帧的步骤。ETSC模块和ESS模块的设计,能够有效地捕获事件流中的时间依赖关系,而边缘增强技术则提升了在稀疏事件条件下的空间信息。
关键设计:ETSC模块通过卷积操作提取相邻时间切片之间的特征,ESS模块则通过序列建模(具体实现方式未知,论文中未详细说明)来捕捉更长的时间依赖关系。边缘增强的具体实现方式也未详细说明,但其目的是增强点云表示中的边缘信息。损失函数和具体的网络参数设置在论文中没有明确给出,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在DHP19数据集上,基于PointNet、DGCNN和Point Transformer等三种不同的点云骨干网络均取得了性能提升。具体提升幅度未知,但论文强调了方法的一致性改进效果,表明其具有较好的泛化能力。
🎯 应用场景
该研究成果可应用于机器人视觉、智能监控、自动驾驶等领域。在这些场景中,事件相机能够提供高动态范围和低延迟的视觉信息,使得在光照变化剧烈或快速运动的条件下进行人体姿态估计成为可能。该方法能够提升这些应用在复杂环境下的鲁棒性和实时性。
📄 摘要(原文)
Human pose estimation focuses on predicting body keypoints to analyze human motion. Event cameras provide high temporal resolution and low latency, enabling robust estimation under challenging conditions. However, most existing methods convert event streams into dense event frames, which adds extra computation and sacrifices the high temporal resolution of the event signal. In this work, we aim to exploit the spatiotemporal properties of event streams based on point cloud-based framework, designed to enhance human pose estimation performance. We design Event Temporal Slicing Convolution module to capture short-term dependencies across event slices, and combine it with Event Slice Sequencing module for structured temporal modeling. We also apply edge enhancement in point cloud-based event representation to enhance spatial edge information under sparse event conditions to further improve performance. Experiments on the DHP19 dataset show our proposed method consistently improves performance across three representative point cloud backbones: PointNet, DGCNN, and Point Transformer.