RefBench-PRO: Perceptual and Reasoning Oriented Benchmark for Referring Expression Comprehension
作者: Tianyi Gao, Hao Li, Han Fang, Xin Wei, Xiaodong Dong, Hongbo Sun, Ye Yuan, Zhongjiang He, Jinglin Xu, Jingmin Xin, Hao Sun
分类: cs.CV, cs.AI
发布日期: 2025-12-06 (更新: 2025-12-13)
💡 一句话要点
提出RefBench-PRO基准,用于评估多模态大模型在指代表达理解中的感知和推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指代表达理解 多模态学习 视觉语言 基准测试 推理能力 感知能力 强化学习
📋 核心要点
- 现有指代表达理解基准侧重感知能力评估,缺乏对推理能力的细粒度评估和可解释的评分机制。
- RefBench-PRO基准将指代表达分解为感知和推理两个维度,并设计六个子任务,实现更全面的评估。
- 提出Ref-R1学习方案,结合动态IoU的GRPO,提升复杂推理条件下的定位精度,并作为更强的基线。
📝 摘要(中文)
指代表达理解(REC)是一项基于文本描述定位特定图像区域的视觉-语言任务。现有的REC基准主要评估感知能力,缺乏可解释的评分机制,无法揭示多模态大型语言模型(MLLM)在不同认知能力上的基础能力。为了解决这一局限性,我们引入了RefBench-PRO,一个全面的REC基准,它将指代表达分解为两个核心维度,即感知和推理,并进一步细分为六个渐进式挑战任务,如属性、位置、交互、常识、关系和拒绝。我们还开发了一个全自动数据生成管道,用于生成跨这六个子维度的多样化指代表达。此外,我们提出了一种基于RL的学习方案Ref-R1,它结合了基于动态IoU的GRPO,以提高在日益复杂的推理条件下的定位精度,为REC建立更强的基线。大量的实验表明,我们的RefBench-PRO能够对MLLM在指代表达理解方面进行可解释的评估,在感知和推理方面都提出了更大的挑战。
🔬 方法详解
问题定义:现有的指代表达理解(REC)基准测试主要关注模型的感知能力,缺乏对模型推理能力的深入评估。此外,现有的评分机制不够透明,难以解释模型在不同认知能力方面的表现。这使得我们难以了解多模态大型语言模型(MLLM)在理解复杂指代表达时的真正能力,以及它们在哪些方面存在不足。
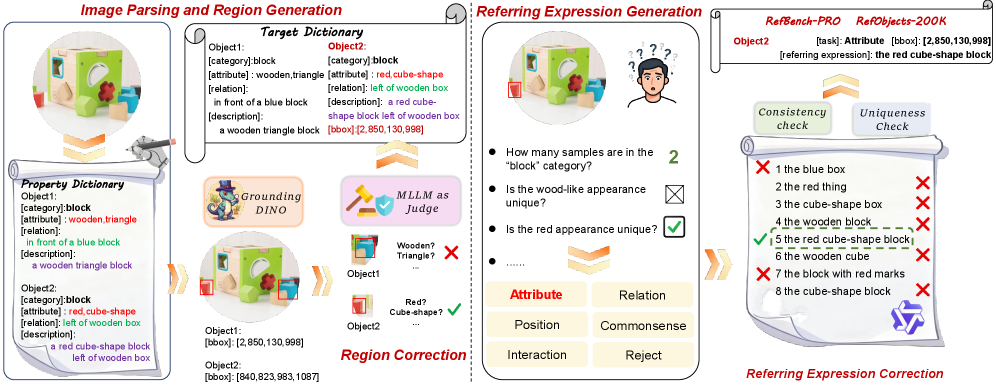
核心思路:RefBench-PRO的核心思路是将指代表达理解任务分解为感知和推理两个关键维度,并进一步细化为六个具有挑战性的子任务。通过这种分解,可以更精确地评估模型在不同认知能力上的表现。此外,论文还提出了Ref-R1学习方案,旨在提高模型在复杂推理条件下的定位精度。
技术框架:RefBench-PRO基准包含一个全自动的数据生成管道,用于生成多样化的指代表达。这些指代表达涵盖了六个子任务:属性、位置、交互、常识、关系和拒绝。Ref-R1学习方案则采用强化学习框架,并结合了基于动态IoU的GRPO(Gradient-based Policy Optimization)方法。整体流程为:输入图像和指代表达,模型预测目标区域,Ref-R1根据预测结果和真实标签计算奖励,并优化模型策略。
关键创新:RefBench-PRO的关键创新在于其对指代表达理解任务的细粒度分解,以及全自动的数据生成管道。这种分解使得可以对模型的感知和推理能力进行更精确的评估。Ref-R1的关键创新在于其动态IoU的GRPO方法,该方法可以根据预测结果动态调整奖励函数,从而提高模型在复杂推理条件下的定位精度。
关键设计:Ref-R1学习方案的关键设计包括:1) 基于动态IoU的奖励函数,该函数可以根据预测结果动态调整奖励,从而更好地引导模型学习。2) GRPO方法,该方法可以有效地优化模型策略,提高模型的定位精度。3) 强化学习框架,该框架可以使模型在与环境的交互中不断学习和改进。
🖼️ 关键图片


📊 实验亮点
实验结果表明,RefBench-PRO能够有效评估MLLM在指代表达理解方面的能力,并在感知和推理方面都提出了更大的挑战。Ref-R1学习方案在复杂推理条件下显著提高了定位精度,相较于现有基线方法取得了明显的性能提升。具体性能数据未知。
🎯 应用场景
该研究成果可应用于智能机器人、自动驾驶、图像搜索等领域。通过提高模型对指代表达的理解能力,可以使机器更好地理解人类指令,从而实现更智能的人机交互。例如,在智能机器人领域,机器人可以根据用户的指代表达,准确地找到目标物体并执行相应的任务。在自动驾驶领域,车辆可以根据行人的指代表达,更好地理解行人的意图,从而提高驾驶安全性。
📄 摘要(原文)
Referring Expression Comprehension (REC) is a vision-language task that localizes a specific image region based on a textual description. Existing REC benchmarks primarily evaluate perceptual capabilities and lack interpretable scoring mechanisms, which cannot reveal the grounding capability of Multi-modal Large Language Model (MLLM) across different cognitive abilities. To address this limitation, we introduce RefBench-PRO, a comprehensive REC benchmark, which decomposes referring expressions into two core dimensions, i.e., perception and reasoning, and further subdivides them into six progressively challenging tasks, such as attribute, position, interaction, commonsense, relation and reject. We also develop a fully automated data-generation pipeline that produces diverse referring expressions across these six sub-dimensions. Furthermore, We propose Ref-R1, an RL-based learning scheme, which incorporates Dynamic IoU-based GRPO to improve localization accuracy under increasingly complex reasoning conditions, establishing a stronger baseline for REC. Extensive experiments demonstrate that our RefBench-PRO enables interpretable evaluation of MLLM on referring expression comprehension, presenting greater challenges in both perception and reasoning.