Opinion: Learning Intuitive Physics May Require More than Visual Data
作者: Ellen Su, Solim Legris, Todd M. Gureckis, Mengye Ren
分类: cs.CV, cs.LG
发布日期: 2025-12-06
💡 一句话要点
研究表明,仅凭大量视觉数据或类儿童视角数据难以使模型掌握直观物理
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 直观物理 深度学习 视频表征学习 自监督学习 数据分布 SAYCam数据集 V-JEPA模型
📋 核心要点
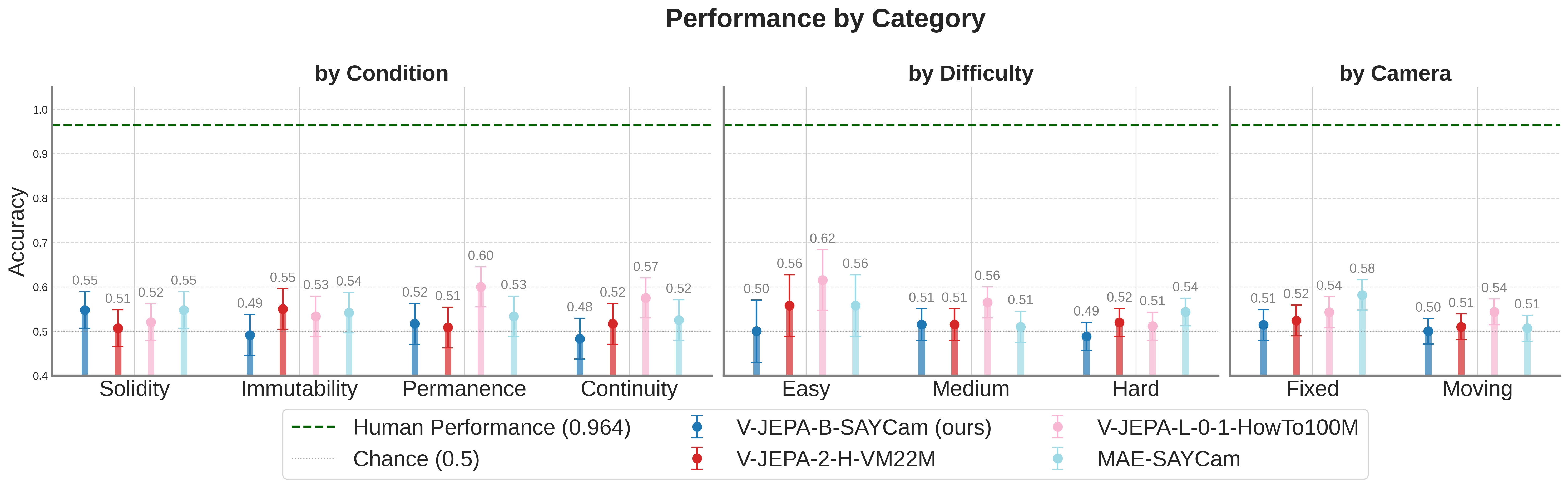
- 现有深度学习模型在直观物理任务上表现不佳,即使在大量数据上训练也是如此,表明数据量可能不是唯一瓶颈。
- 论文探索了数据分布的影响,使用模拟儿童视角的SAYCam数据集预训练模型,试图提高模型对直观物理的理解。
- 实验结果表明,即使使用更符合人类发展的数据集,现有模型在直观物理基准测试上的性能提升仍然有限。
📝 摘要(中文)
人类通过构建基于直观物理的丰富内部模型来熟练地在世界中活动。然而,尽管在大量的互联网视频数据上进行了训练,但最先进的深度学习模型在直观物理基准测试中仍然达不到人类水平的性能。本文研究了数据分布而非数据量是否是学习这些原则的关键。我们使用SAYCam(一个发展上真实的、以自我为中心的视频数据集,部分捕捉了三个孩子的日常视觉体验)预训练了一个视频联合嵌入预测架构(V-JEPA)模型。我们发现,在这个数据集上进行训练(仅占SOTA模型训练数据量的0.01%)并不能在IntPhys2基准测试中带来显著的性能提升。我们的结果表明,仅仅在发展上真实的数据集上进行训练,对于当前的架构来说,不足以学习支持直观物理的表征。我们得出结论,仅改变视觉数据量和分布可能不足以构建具有人工直观物理的系统。
🔬 方法详解
问题定义:论文旨在解决深度学习模型在学习直观物理方面表现不佳的问题。现有方法通常依赖于大量互联网视频数据进行训练,但这些数据可能缺乏人类学习环境的关键特征,例如以自我为中心的视角和特定的交互模式。因此,模型难以泛化到需要直观物理推理的任务中。
核心思路:论文的核心思路是,数据分布比数据量更重要。通过使用一个更符合人类早期视觉经验的数据集(SAYCam),模型可能能够学习到更有效的表征,从而更好地理解直观物理。SAYCam数据集模拟了儿童的视角,包含了大量的自我运动和物体交互,这可能有助于模型学习到物体之间的关系和物理规律。
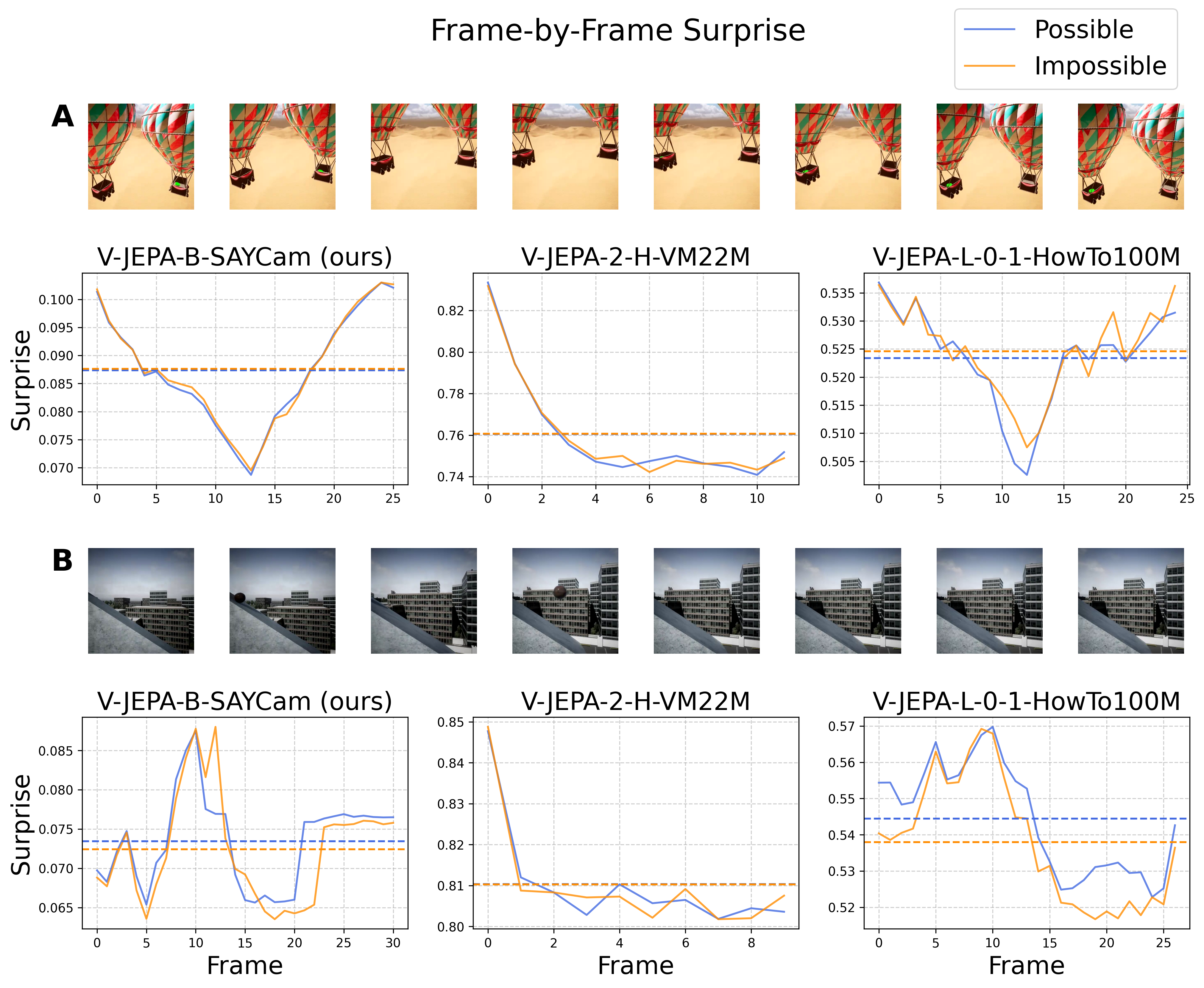
技术框架:论文使用视频联合嵌入预测架构(V-JEPA)作为基础模型。V-JEPA是一种自监督学习框架,通过预测视频中的未来帧来学习视频表征。该框架包含一个编码器,用于将视频帧编码成潜在向量,以及一个预测器,用于根据过去的潜在向量预测未来的潜在向量。然后,使用解码器将预测的潜在向量解码成视频帧。
关键创新:论文的关键创新在于使用SAYCam数据集进行预训练,并评估模型在IntPhys2基准测试上的性能。SAYCam数据集提供了一个更符合人类早期视觉经验的数据分布,这与以往使用的大规模互联网视频数据有所不同。通过比较在SAYCam上预训练的模型与在其他数据集上预训练的模型的性能,论文可以评估数据分布对学习直观物理的影响。
关键设计:论文使用了标准的V-JEPA架构,并使用Adam优化器进行训练。损失函数是预测帧和真实帧之间的均方误差。模型在SAYCam数据集上进行了预训练,然后在IntPhys2基准测试上进行了微调。具体的参数设置(例如学习率、批大小、网络结构)在论文中没有详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,即使使用SAYCam数据集进行预训练,V-JEPA模型在IntPhys2基准测试上的性能提升仍然有限。与在其他数据集上预训练的模型相比,SAYCam预训练的模型并没有表现出显著的优势。这表明,仅仅改变数据分布可能不足以使模型学习到直观物理。具体的性能数据和提升幅度在论文中没有明确给出,属于未知信息。
🎯 应用场景
该研究对开发更智能的机器人和人工智能系统具有重要意义。如果仅靠大量数据无法使模型掌握直观物理,那么就需要探索新的学习方法和数据表示方式。未来的研究可以关注如何设计更有效的模型架构,以及如何利用先验知识和符号推理来增强模型的物理理解能力。这对于开发能够在复杂环境中自主导航和交互的机器人至关重要。
📄 摘要(原文)
Humans expertly navigate the world by building rich internal models founded on an intuitive understanding of physics. Meanwhile, despite training on vast quantities of internet video data, state-of-the-art deep learning models still fall short of human-level performance on intuitive physics benchmarks. This work investigates whether data distribution, rather than volume, is the key to learning these principles. We pretrain a Video Joint Embedding Predictive Architecture (V-JEPA) model on SAYCam, a developmentally realistic, egocentric video dataset partially capturing three children's everyday visual experiences. We find that training on this dataset, which represents 0.01% of the data volume used to train SOTA models, does not lead to significant performance improvements on the IntPhys2 benchmark. Our results suggest that merely training on a developmentally realistic dataset is insufficient for current architectures to learn representations that support intuitive physics. We conclude that varying visual data volume and distribution alone may not be sufficient for building systems with artificial intuitive physics.