Training Multi-Image Vision Agents via End2End Reinforcement Learning
作者: Chengqi Dong, Chuhuai Yue, Hang He, Rongge Mao, Fenghe Tang, S Kevin Zhou, Zekun Xu, Xiaohan Wang, Jiajun Chai, Wei Lin, Guojun Yin
分类: cs.CV, cs.AI
发布日期: 2025-12-05 (更新: 2025-12-16)
💡 一句话要点
提出IMAgent,通过端到端强化学习训练多图视觉Agent,解决复杂多图QA任务。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多图问答 视觉Agent 强化学习 工具使用 视觉语言模型 端到端训练 多模态学习
📋 核心要点
- 现有基于VLM的Agent在工具使用方面表现出色,但大多仅限于单图输入,难以应对真实世界的多图QA任务。
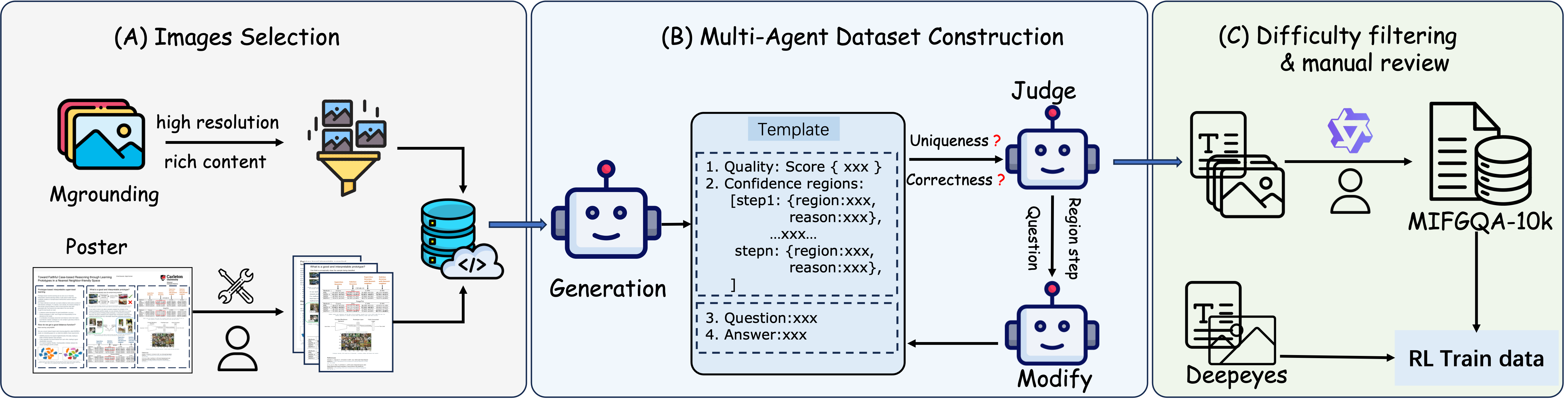
- IMAgent通过端到端强化学习训练,利用多Agent系统生成复杂多图QA对,并设计视觉反思和确认工具,提升模型对图像内容的关注。
- 实验表明,IMAgent在单图基准上保持性能,并在提出的多图数据集上取得显著提升,为多图视觉Agent研究提供新思路。
📝 摘要(中文)
本文提出IMAgent,一个开源的视觉Agent,通过端到端强化学习训练,专门用于处理复杂的多图任务。利用多Agent系统,生成具有挑战性和视觉丰富性的多图QA对,充分激活基础VLM的工具使用潜力。通过人工验证,构建了包含1万个样本的MIFG-QA数据集,用于训练和评估。针对VLM在深度推理中可能忽略视觉输入的问题,开发了视觉反思和确认工具,使模型在推理过程中主动重新分配对图像内容的注意力。受益于精心设计的动作轨迹两级掩码策略,IMAgent通过纯强化学习训练实现了稳定的工具使用行为,无需昂贵的监督微调数据。大量实验表明,IMAgent在现有单图基准上保持了强大的性能,并在提出的多图数据集上取得了显著的改进,分析为研究社区提供了可操作的见解。代码和数据即将发布。
🔬 方法详解
问题定义:现有基于视觉语言模型(VLM)的Agent在处理需要工具使用的任务时,通常仅限于单张图像的输入。然而,现实世界中的许多任务,例如多图问答(QA),需要同时处理多张图像才能完成。现有方法无法有效利用多图信息,导致性能受限。此外,VLM在进行深度推理时,可能会逐渐忽略视觉输入,进一步降低性能。
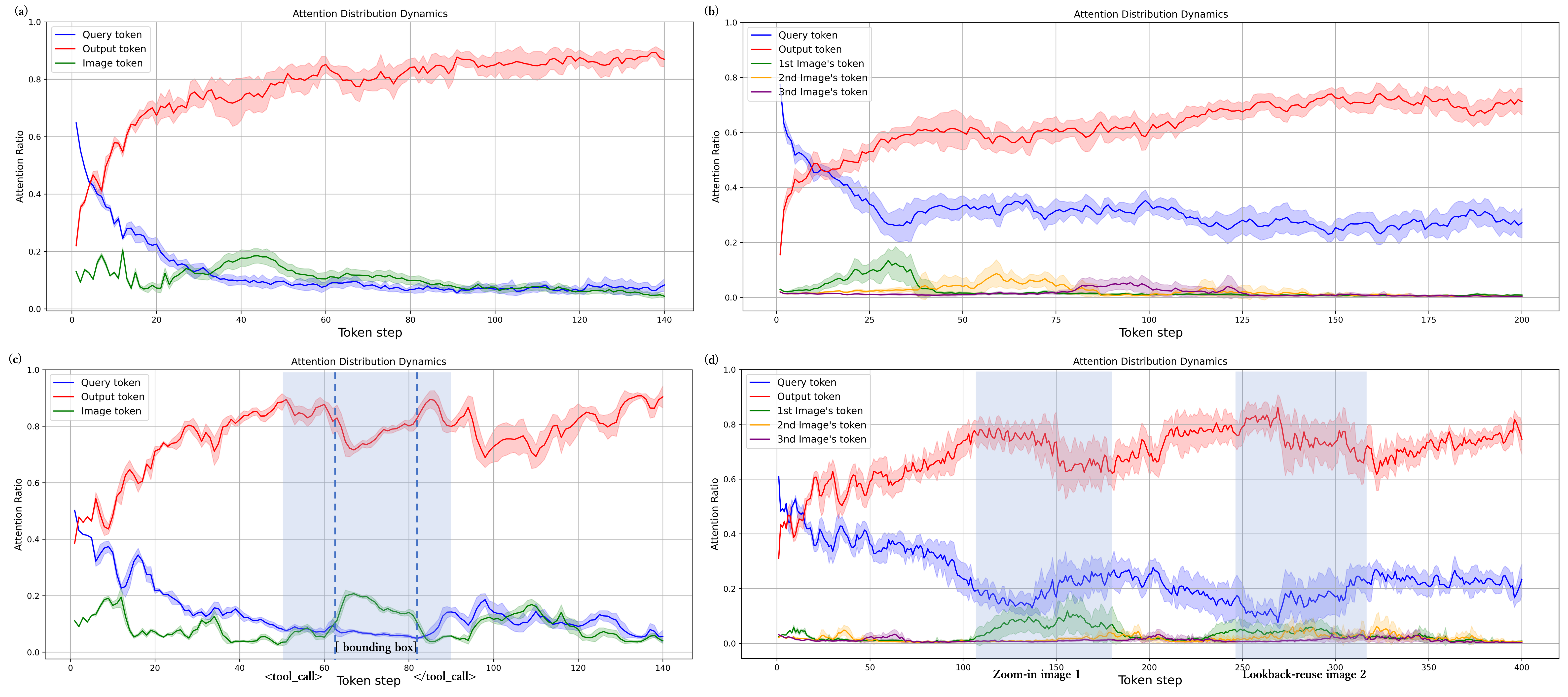
核心思路:IMAgent的核心思路是通过端到端强化学习,训练一个能够有效利用多图信息并进行工具使用的Agent。为了解决VLM在深度推理中忽略视觉输入的问题,引入了视觉反思和确认工具,使Agent能够主动关注图像内容。此外,通过精心设计的动作轨迹两级掩码策略,实现了稳定的工具使用行为。
技术框架:IMAgent的技术框架主要包括以下几个部分:1) 多Agent系统:用于生成具有挑战性和视觉丰富性的多图QA对,作为训练数据。2) 基础VLM:作为Agent的核心推理引擎。3) 视觉反思和确认工具:用于在推理过程中重新分配对图像内容的注意力。4) 强化学习训练:通过端到端强化学习,优化Agent的工具使用策略。5) 动作轨迹两级掩码策略:用于稳定工具使用行为。
关键创新:IMAgent的关键创新在于:1) 提出了一个基于端到端强化学习的多图视觉Agent训练框架。2) 设计了视觉反思和确认工具,解决了VLM在深度推理中忽略视觉输入的问题。3) 提出了动作轨迹两级掩码策略,实现了稳定的工具使用行为,无需昂贵的监督微调数据。4) 构建了MIFG-QA数据集,为多图视觉Agent的研究提供了新的基准。
关键设计:在多Agent系统中,需要设计合适的奖励函数,鼓励生成具有挑战性和视觉丰富性的多图QA对。在视觉反思和确认工具中,需要设计合适的注意力机制,使Agent能够有效地重新分配对图像内容的注意力。在动作轨迹两级掩码策略中,需要设计合适的掩码策略,防止Agent过早或过晚地使用工具。具体的参数设置、损失函数、网络结构等技术细节在论文中进行了详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
IMAgent在提出的多图数据集MIFG-QA上取得了显著的改进,性能提升幅度未知。同时,IMAgent在现有的单图基准上保持了强大的性能,表明其具有良好的泛化能力。通过消融实验,验证了视觉反思和确认工具以及动作轨迹两级掩码策略的有效性。
🎯 应用场景
IMAgent具有广泛的应用前景,例如智能客服、医疗诊断、工业检测等领域。在智能客服中,可以利用IMAgent处理用户上传的多张图片,进行更准确的问题解答。在医疗诊断中,可以利用IMAgent分析多张医学影像,辅助医生进行诊断。在工业检测中,可以利用IMAgent检测产品表面的缺陷。
📄 摘要(原文)
Recent VLM-based agents aim to replicate OpenAI O3's ``thinking with images" via tool use, but most open-source methods limit input to a single image, falling short on real-world multi-image QA tasks. To address this, we propose IMAgent, an open-source vision agent trained via end-to-end reinforcement learning dedicated for complex multi-image tasks. By leveraging a multi-agent system, we generate challenging and visually-rich multi-image QA pairs to fully activate the tool-use potential of the base VLM. Through manual verification, we obtain MIFG-QA, comprising 10k samples for training and evaluation. With deeper reasoning steps, VLMs may increasingly ignore visual inputs. We therefore develop two specialized tools for visual reflection and confirmation, allowing the model to proactively reallocate its attention to image content during inference. Benefiting from our well-designed action-trajectory two-level mask strategy, IMAgent achieves stable tool use behavior via pure RL training without requiring costly supervised fine-tuning data. Extensive experiments demonstrate that IMAgent maintains strong performance on existing single-image benchmarks while achieving substantial improvements on our proposed multi-image dataset, with our analysis providing actionable insights for the research community. Codes and data will be released soon.