Tracking-Guided 4D Generation: Foundation-Tracker Motion Priors for 3D Model Animation
作者: Su Sun, Cheng Zhao, Himangi Mittal, Gaurav Mittal, Rohith Kukkala, Yingjie Victor Chen, Mei Chen
分类: cs.CV
发布日期: 2025-12-05
备注: 15 pages, 11 figures
💡 一句话要点
提出Track4DGen,通过跟踪引导的4D生成实现高质量3D模型动画
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 4D生成 动态3D模型 多视角视频扩散 点跟踪 高斯溅射 运动先验 时间一致性
📋 核心要点
- 现有方法在稀疏输入下生成动态4D对象时,难以保持视角和时间上外观与运动的一致性,易出现伪影和时间漂移。
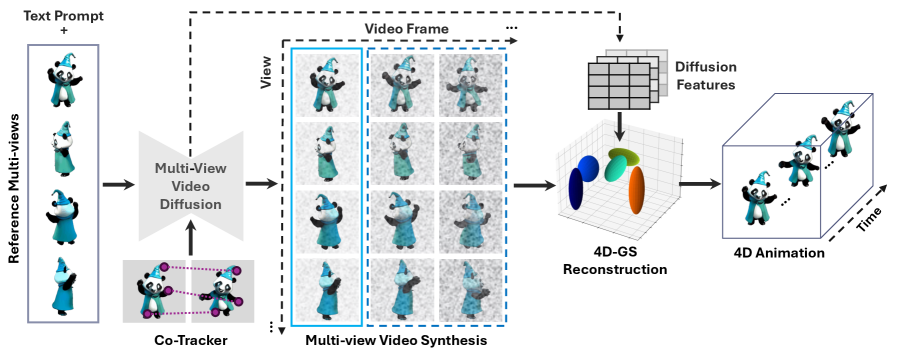
- Track4DGen通过将跟踪器导出的运动先验注入多视角视频生成和4D-GS的中间特征表示中,显式地引入时间感知和特征级跟踪指导。
- Track4DGen在多视角视频生成和4D生成基准测试中超越现有方法,生成时间稳定且可文本编辑的4D资产,并构建了高质量数据集Sketchfab28。
📝 摘要(中文)
从稀疏输入生成动态4D对象极具挑战,因为它需要在不同视角和时间上联合保持外观和运动的一致性,同时抑制伪影和时间漂移。我们认为,视角差异源于仅限于像素或潜在空间视频扩散损失的监督,这些损失缺乏显式的时间感知、特征级跟踪指导。我们提出了Track4DGen,这是一个两阶段框架,将多视角视频扩散模型与基础点跟踪器和混合4D高斯溅射(4D-GS)重建器相结合。核心思想是将跟踪器导出的运动先验显式地注入到多视角视频生成和4D-GS的中间特征表示中。在第一阶段,我们在扩散生成器内部强制执行密集的特征级点对应关系,产生时间上一致的特征,从而抑制外观漂移并增强跨视角一致性。在第二阶段,我们使用混合运动编码重建动态4D-GS,该编码将共位的扩散特征(携带第一阶段的跟踪先验)与Hex-plane特征连接起来,并用4D球谐函数增强它们,以实现更高保真度的动态建模。Track4DGen在多视角视频生成和4D生成基准测试中均优于基线,从而产生时间稳定的、文本可编辑的4D资产。最后,我们策划了Sketchfab28,这是一个高质量的数据集,用于基准测试以对象为中心的4D生成并促进未来的研究。
🔬 方法详解
问题定义:论文旨在解决从稀疏输入生成高质量、时间一致的动态4D对象的问题。现有方法主要依赖于像素或潜在空间的视频扩散损失,缺乏显式的时间感知和特征级跟踪指导,导致视角不一致、时间漂移和伪影等问题。
核心思路:论文的核心思路是将跟踪器导出的运动先验显式地注入到多视角视频生成和4D高斯溅射(4D-GS)重建的中间特征表示中。通过引入特征级的跟踪信息,可以更好地保持时间一致性,抑制外观漂移,并增强跨视角一致性。
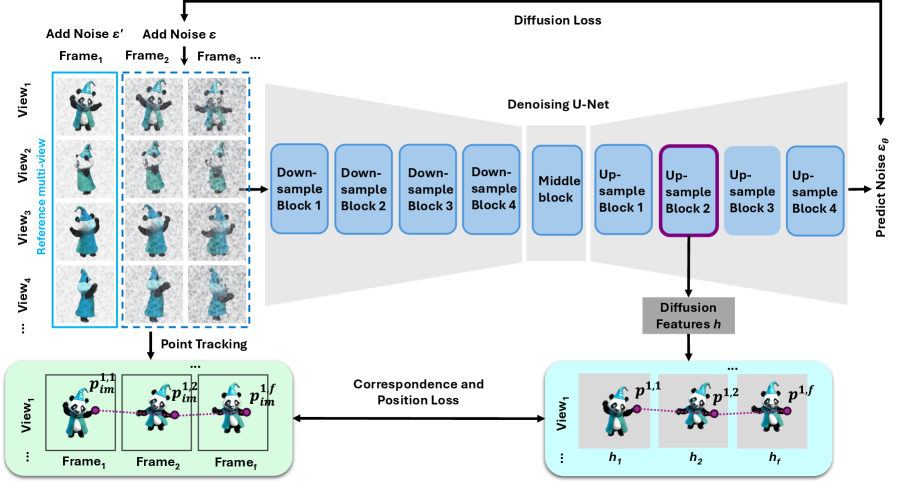
技术框架:Track4DGen是一个两阶段框架: 1. 多视角视频生成阶段:利用多视角视频扩散模型,并强制执行密集的特征级点对应关系,生成时间一致的特征。 2. 4D-GS重建阶段:使用混合运动编码重建动态4D-GS,将扩散特征(携带跟踪先验)与Hex-plane特征连接,并用4D球谐函数增强,以实现更高保真度的动态建模。
关键创新:论文的关键创新在于将基础点跟踪器与多视角视频扩散模型相结合,通过跟踪信息引导特征生成,从而实现时间一致的4D对象生成。这种方法显式地利用了运动信息,克服了传统方法中缺乏时间感知的缺陷。
关键设计: * 特征级点对应:在扩散生成器内部强制执行密集的特征级点对应关系,确保生成特征的时间一致性。 * 混合运动编码:将扩散特征(携带跟踪先验)与Hex-plane特征连接,并用4D球谐函数增强,以实现更高保真度的动态建模。 * Sketchfab28数据集:构建了一个高质量的以对象为中心的4D生成数据集,用于基准测试和未来研究。
🖼️ 关键图片
📊 实验亮点
Track4DGen在多视角视频生成和4D生成基准测试中均优于现有基线方法,能够生成时间稳定的、文本可编辑的4D资产。论文还构建了一个高质量的数据集Sketchfab28,为未来的4D生成研究提供了宝贵资源。具体性能数据和提升幅度在论文正文中给出,此处未知。
🎯 应用场景
该研究成果可应用于虚拟现实、增强现实、游戏开发、电影制作等领域,实现高质量的3D模型动画生成和编辑。例如,可以根据文本描述生成动态的3D角色动画,或者将现有的3D模型转化为可编辑的4D资产,从而大大提高内容创作的效率和质量。
📄 摘要(原文)
Generating dynamic 4D objects from sparse inputs is difficult because it demands joint preservation of appearance and motion coherence across views and time while suppressing artifacts and temporal drift. We hypothesize that the view discrepancy arises from supervision limited to pixel- or latent-space video-diffusion losses, which lack explicitly temporally aware, feature-level tracking guidance. We present \emph{Track4DGen}, a two-stage framework that couples a multi-view video diffusion model with a foundation point tracker and a hybrid 4D Gaussian Splatting (4D-GS) reconstructor. The central idea is to explicitly inject tracker-derived motion priors into intermediate feature representations for both multi-view video generation and 4D-GS. In Stage One, we enforce dense, feature-level point correspondences inside the diffusion generator, producing temporally consistent features that curb appearance drift and enhance cross-view coherence. In Stage Two, we reconstruct a dynamic 4D-GS using a hybrid motion encoding that concatenates co-located diffusion features (carrying Stage-One tracking priors) with Hex-plane features, and augment them with 4D Spherical Harmonics for higher-fidelity dynamics modeling. \emph{Track4DGen} surpasses baselines on both multi-view video generation and 4D generation benchmarks, yielding temporally stable, text-editable 4D assets. Lastly, we curate \emph{Sketchfab28}, a high-quality dataset for benchmarking object-centric 4D generation and fostering future research.