EditThinker: Unlocking Iterative Reasoning for Any Image Editor
作者: Hongyu Li, Manyuan Zhang, Dian Zheng, Ziyu Guo, Yimeng Jia, Kaituo Feng, Hao Yu, Yexin Liu, Yan Feng, Peng Pei, Xunliang Cai, Linjiang Huang, Hongsheng Li, Si Liu
分类: cs.CV
发布日期: 2025-12-05
备注: Project page: https://appletea233.github.io/think-while-edit
💡 一句话要点
EditThinker:解锁任意图像编辑器迭代推理能力,提升指令遵循性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像编辑 指令遵循 迭代推理 多模态大语言模型 强化学习
📋 核心要点
- 现有基于指令的图像编辑方法,受限于生成模型的随机性和缺乏迭代优化,单轮指令遵循成功率较低。
- EditThinker框架通过模拟人类“思考-编辑”循环,迭代地批判结果、改进指令并重新生成,从而提升编辑质量。
- 通过强化学习对齐EditThinker的思考和编辑过程,使其能够生成更有针对性的指令改进,显著提升指令遵循能力。
📝 摘要(中文)
基于指令的图像编辑已成为一个重要的研究领域。受益于图像生成基础模型,该领域在美学质量上取得了显著进展,使得指令遵循能力成为主要挑战。现有方法通过监督学习或强化学习来提高指令遵循性,但由于固有的随机性和缺乏深思熟虑,单轮成功率仍然有限。本文提出了一个深思熟虑的编辑框架,通过迭代执行“思考-编辑”循环来模拟人类的认知过程:批判结果并改进指令,然后重复生成直到满意。具体来说,我们训练了一个单一的多模态大语言模型EditThinker,作为该框架的推理引擎,共同产生批判分数、推理过程和改进的指令。我们采用强化学习来使EditThinker的思考与其编辑对齐,从而生成更有针对性的指令改进。在四个基准测试上的大量实验表明,我们的方法显著提高了任何图像编辑模型的指令遵循能力。
🔬 方法详解
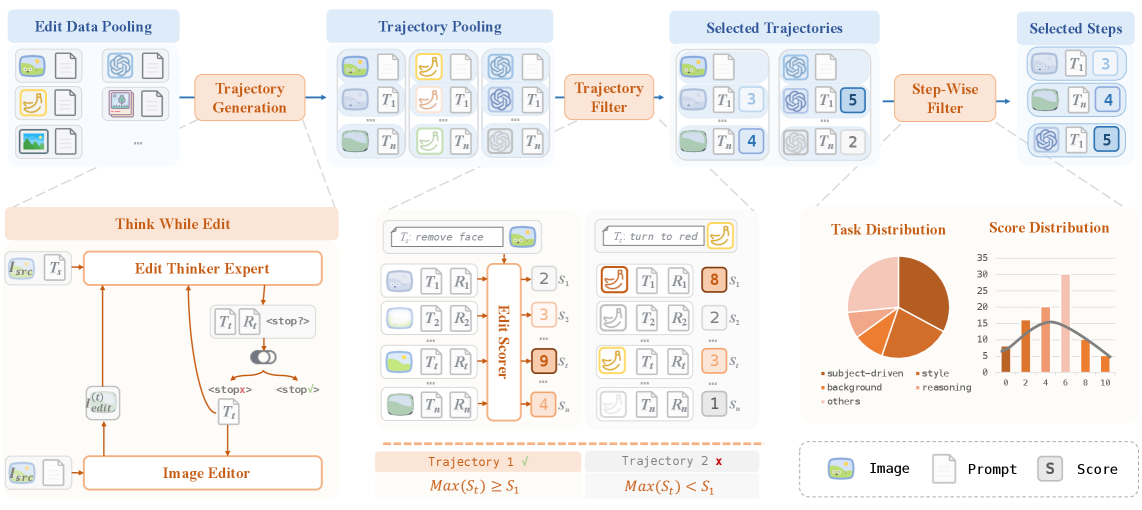
问题定义:现有基于指令的图像编辑方法,虽然在图像生成质量上有所提升,但由于生成过程的随机性以及缺乏迭代优化机制,模型难以准确理解并执行复杂的编辑指令,导致单轮编辑的指令遵循成功率较低。现有方法主要依赖监督学习或强化学习来提升指令遵循性,但效果仍然有限,无法充分模拟人类编辑过程中不断思考和改进的认知过程。
核心思路:本文的核心思路是引入一个迭代的“思考-编辑”循环,模拟人类在编辑图像时的认知过程。通过让模型在每次编辑后进行自我批判,并基于批判结果改进指令,然后重新生成图像,从而逐步逼近用户期望的编辑效果。这种迭代优化的方式可以有效克服生成模型的随机性,并提升模型对复杂指令的理解和执行能力。
技术框架:EditThinker框架的核心是一个多模态大语言模型(MLLM),作为整个框架的推理引擎。框架主要包含以下几个阶段:1) 图像编辑模型根据初始指令生成图像;2) EditThinker对生成的图像进行评估,给出批判分数和推理过程;3) EditThinker基于批判结果和推理过程,生成改进后的指令;4) 使用改进后的指令重新生成图像,并重复上述过程,直到达到满意的编辑效果。整个框架通过迭代执行“思考-编辑”循环,不断优化编辑结果。
关键创新:本文最重要的技术创新点在于提出了一个迭代的“思考-编辑”框架,将人类的认知过程融入到图像编辑流程中。与现有方法相比,EditThinker不仅关注单轮编辑的准确性,更注重通过迭代优化来逐步提升编辑质量。此外,使用强化学习对齐EditThinker的思考和编辑过程,使其能够生成更有针对性的指令改进,也是一个重要的创新点。
关键设计:EditThinker模型是一个多模态大语言模型,需要同时处理图像和文本信息。模型的设计需要考虑如何有效地融合这两种模态的信息,并生成高质量的批判分数、推理过程和改进指令。强化学习部分,需要设计合适的奖励函数,以鼓励EditThinker生成能够有效提升编辑质量的指令改进。具体的参数设置、损失函数和网络结构等细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片


📊 实验亮点
实验结果表明,EditThinker框架在四个基准测试上显著提高了图像编辑模型的指令遵循能力。具体提升幅度未知,但摘要中提到是“a large margin”,表明提升效果显著。通过与其他基线方法的对比,验证了EditThinker框架的有效性和优越性。论文将公开数据构建框架、数据集和模型,有助于推动该领域的研究。
🎯 应用场景
EditThinker框架具有广泛的应用前景,可以应用于各种图像编辑场景,例如照片修复、风格迁移、图像增强等。该框架可以显著提升图像编辑的自动化程度和用户体验,降低专业图像编辑的门槛。未来,该框架还可以扩展到视频编辑、3D模型编辑等领域,为内容创作提供更强大的工具。
📄 摘要(原文)
Instruction-based image editing has emerged as a prominent research area, which, benefiting from image generation foundation models, have achieved high aesthetic quality, making instruction-following capability the primary challenge. Existing approaches improve instruction adherence via supervised or reinforcement learning, yet single-turn success rates remain limited due to inherent stochasticity and a lack of deliberation. In this work, we propose a deliberative editing framework to 'think' while they edit, which simulates the human cognitive loop by iteratively executing a Think-while-Edit cycle: Critiquing results and Refining instructions , followed by Repeating the generation until satisfactory. Specifically, we train a single MLLM, EditThinker, to act as the reasoning engine of this framework, which jointly produce the critique score, reasoning process, and refined instructions. We employ reinforcement learning to align the EditThinker's thinking with its editing, thereby generating more targeted instruction improvements. Extensive experiments on four benchmarks demonstrate that our approach significantly improves the instruction-following capability of any image editing model by a large margin. We will release our data construction framework, datasets, and models to benefit the community.